
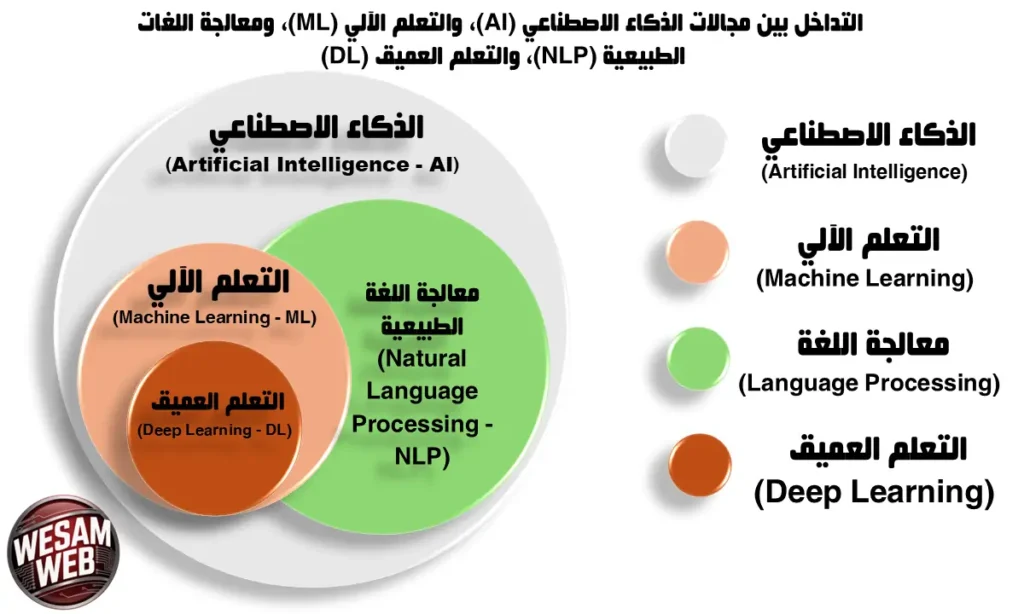
معالجة اللغة الطبيعية (NLP): هل ينتج الذكاء الاصطناعي نصً مقنع دون فهم حقيقي لمعناه؟


هل تساءلت يومًا كيف يفهم الذكاء الاصطناعي اللغة التي نستخدمها؟ تخيل أن جهاز الكمبيوتر الخاص بك لا يستطيع فقط تنفيذ أوامرك، بل يفهم نبرة صوتك عندما تكون متوتراً، أو يميز السخرية في رسالة بريدك الإلكتروني، أو يلخص آلاف الصفحات في فقرات قليلة ذات معنى. هذا ليس خيالاً علمياً بل واقع نعيشه اليوم، بفضل مجال ثوري يجمع بين اللغويات وعلوم الحاسوب: معالجة اللغة الطبيعية (NLP).
في عالم يشهد انفجاراً في البيانات النصية والصوتية، أصبحت القدرة على فهم اللغة البشرية وتحليلها تكنولوجياً واحدة من أهم التحولات في تاريخ التفاعل بين الإنسان والآلة. من المساعدات الذكية على هواتفنا إلى أنظمة الترجمة الفورية، ومن مرشحات البريد المزعج إلى محركات البحث المتطورة، تعمل معالجة اللغة الطبيعية في الخلفية، وتعيد تشكيل طريقة تواصلنا مع التكنولوجيا.
لكن كيف تتم هذه المعجزة؟ كيف تتحول الكلمات والعبارات التي نتفهمها بحدسنا البشري إلى بيانات تستطيع الخوارزميات معالجتها؟ هذا المقال سيأخذك في رحلة استكشافية إلى قلب معالجة اللغة الطبيعية، حيث سنكشف:
- الأساسيات العلمية التي تمكن الآلات من “فهم” اللغة
- التقنيات المتطورة مثل نماذج الذكاء الاصطناعي التحويلية (Transformers)
- التطبيقات الثورية التي غيرت قطاعات الصحة والمالية والتعليم
- التحديات الأخلاقية والعملية التي تواجه هذا المجال المتسارع النمو
ستلاحظ أن معالجة اللغة الطبيعية هي أكثر من مجرد برنامج حاسوبي عادي. إنها أشبه بجسر سحري يربط بين عالمين مختلفين تماماً: من جهة، عالم الآلات الذي يعتمد على لغة الأرقام البسيطة (صفر وواحد)، ومن جهة أخرى، عالم اللغة البشرية المليء بالمشاعر والتشبيهات والسخرية والسياق. هذه التقنية لا تقلد فهمنا للكلمات فحسب، بل قد تغير مفهومنا للأصالة والذكاء في المستقبل. فهيا بنا نكمل الرحلة معاً، لنرى خطوة بخطوة كيف تتعلم الآلة لغة البشر، وكيف سيغير هذا التقارب عالمنا.
جدول المحتويات
- فيديو التعرف على مجال معالجة اللغة الطبيعية (NLP)
- ما هي معالجة اللغة الطبيعية (NLP)؟
- تاريخ معالجة اللغة الطبيعية (NLP)
- ما هي خوارزميات معالجة اللغات الطبيعية؟
- كيف تعمل معالجة اللغة الطبيعية (NLP)؟ فك شفرة لغة البشر للآلة
- أهم 4 مراحل في بناء أنظمة معالجة اللغة الطبيعية
- دور التعلم العميق في أنظمة NLP الحديثة
- أهم استخدامات معالجة اللغة الطبيعية
- ما هو تنقيب البيانات في معالجة اللغة الطبيعية؟
- تطبيقات معالجة اللغة الطبيعية (NLP)
- 1. كشف الرسائل غير المرغوب فيها (Spam Detection)
- 2. روبوتات الدردشة (Chatbots)
- 3. الترجمة الآلية (Machine Translation)
- 4. تحليل المشاعر (Sentiment Analysis)
- 5. تلخيص النص (Text Summarization)
- 6. حل الغموض (Word Sense Disambiguation)
- 7. التعرف على الكيانات المسماة (Named Entity Recognition – NER)
- 8. معالجة اللغة الطبيعية في المجال الطبي
- 9. التعرف على الكلام (Speech Recognition)
- 10. استخراج المعلومات (Information Extraction)
- مراحل معالجة اللغة الطبيعية (Natural Language Processing Stages)
- الفرق بين معالجة اللغة الطبيعية NLP و توليد اللغة الطبيعية NLG
- تحديات معالجة اللغة الطبيعية (NLP)
- ما هي مميزات وعيوب معالجة اللغة الطبيعية؟
- توقعاتنا من مستقبل معالجة اللغة الطبيعية (NLP)
- اتجاهات إضافية مستقبلية لاستخدام معالجة اللغة الطبيعية NLP في الشركات
- التطورات الحديثة والمستقبلية في معالجة اللغة الطبيعية (NLP) من واقع تجربتنا
- أهم المصادر للتدريب على معالجة اللغة الطبيعية (NLP) للمبتدئين والمتقدمين
- الخاتمة
فيديو التعرف على مجال معالجة اللغة الطبيعية (NLP)
تعتبر معالجة اللغات الطبيعية، وهي اللغة التي نستخدمها غريزيًا في تواصلنا اليومي وتفاعلاتنا المختلفة، من أحدث المجالات وأكثرها انتشارًا في عالم الذكاء الاصطناعي. وتنبع هذه الشعبية من ظهور العديد من التطبيقات التي تعتمد عليها، مثل تلك التي سنستعرضها أدناه:
- مولدات النصوص التي تستخدم في كتابة مقالات مترابطة وذات معنى واضح.
- روبوتات الدردشة (Chatbots) التي تظهر مستوىً متقدمًا من التفاعل، ما يدفع الإنسان للتفكير في مدى ما تمتلكه من “وعي” أو “إحساس” ظاهري.
- برامج تحويل النص إلى صورة، والتي تنشئ صورًا واقعية بناءً على الأوصاف التي نقدمها لها على شكل مطالب أو أوامر (Prompts).
وخلال السنوات الأخيرة، شهدنا ثورة حقيقية في قدرة الحواسيب على فهم اللغات البشرية، ولغات البرمجة، بل وحتى السلاسل البيولوجية والكيميائية، مثل تراكيب البروتين والحمض النووي DNA التي تشبه في بنيتها مفهوم اللغة. وقد مهّدت أحدث نماذج الذكاء الاصطناعي الطريق لهذه المجالات، عبر تمكينها من تحليل المعاني الكامنة في النصوص المُدخلة وإنتاج مخرجات ذات دلالة ومعنى واضح وقابل للاستخدام.
ما هي معالجة اللغة الطبيعية (NLP)؟
معالجة اللغة الطبيعية (Natural Language Processing | NLP) إحدى الركائز الأساسية للذكاء الاصطناعي الحديث، إذ تمنح الحواسيب القدرة على فهم اللغة البشرية المنطوقة والمكتوبة، ومعالجتها، والاستجابة لها بطريقة ذكية. ببساطة، هي الجسر التكنولوجي الذي يسمح لنا بالتواصل مع الآلات بلغتنا الطبيعية، كما نتواصل مع بعضنا البعض.
وضع حجر الأساس النظري لهذا المجال على يد آلان تورينج (Alan Turing) في خمسينيات القرن الماضي، عبر طرحه لـ “اختبار تورينج” (Turing Test)، الذي جعل من القدرة على إجراء محادثة طبيعية مقياساً للذكاء الآلي. وبدأت التجارب العملية تتوالى، مثل برنامج “إليزا” (ELIZA) في عام 1966، وهو أول روبوت محادثة (Chatbot) طوِر لمحاكاة المعالج النفسي باستخدام تقنيات مطابقة الأنماط (Pattern Matching).
شهدت العقود التالية تطورات متسارعة، انتقلت خلالها التقنية من النماذج القائمة على القواعد (Rule-based Systems) إلى النماذج الإحصائية (Statistical Models)، لتصل إلى الثورة الحقيقية مع ظهور التعلم العميق (Deep Learning) وخاصة معمارية المحولات (Transformer Architecture).
هذه التقنية، التي تستخدم آلية “الانتباه” (Attention Mechanism)، مكنت النماذج اللغوية مثل GPT (Generative Pre-trained Transformer) وBERT (Bidirectional Encoder Representations from Transformers) من فهم السياق بدقة غير مسبوقة وتوليد لغة طبيعية متماسكة.
اليوم، لم يعد الـ NLP مجرد بحث أكاديمي؛ فهو العصب الخفي الذي يدفع معظم التقنيات التي نتفاعل معها يومياً. فهو الذي يجعل المساعدات الذكية (Intelligent Virtual Assistants) مثل سيري (Siri) وأليكسا (Alexa) تفهم أوامرك الصوتية، ويتيح لـ مترجم جوجل (Google Translate) تقديم ترجمة فورية، ويشغل خوارزميات التوصية (Recommendation Algorithms) في منصات مثل يوتيوب (YouTube) ونتفليكس (Netflix)، ويفعل مرشحات البريد العشوائي (Spam Filters) في بريدك الإلكتروني، بل ويمكن أدوات مثل شات جي بي تي (ChatGPT) من إجراء حوارات إبداعية.
مقالة ذات صلة: الذكاء الاصطناعي (AI): ثورة في تحسين كفاءة الأعمال وتطوير المستقبل.
تاريخ معالجة اللغة الطبيعية (NLP)
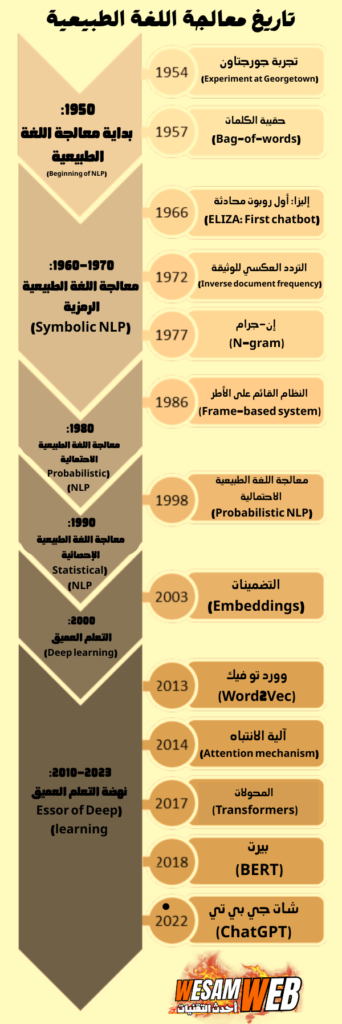
يعود تاريخ معالجة اللغات الطبيعية إلى القرن السابع عشر، عندما اقترح فلاسفة مثل لايبنتز وديكارت رموزًا لربط الكلمات بين اللغات. إلا أن جميع هذه المقترحات ظلت نظرية بحتة ولم تفض إلى تطوير آلة حقيقية. سجلت أول براءة اختراع في مجال معالجة اللغات في منتصف ثلاثينيات القرن العشرين؛ وكانت لقاموس آلي ثنائي اللغة باستخدام شريط ورقي، طوره جورج آرتسروني. ثم جاء اقتراح أكثر تفصيلًا من الروسي بيتر ترويانسكي.
تضمن هذا الاختراع قاموسًا ثنائي اللغة، بالإضافة إلى طريقة للتعامل مع الأدوار النحوية بين اللغات. في عام ١٩٥٠، نشر آلان تورينج بحثه الشهير “آلات الحوسبة والذكاء الاصطناعي”، المعروف الآن باسم اختبار تورينج. يقيس هذا الاختبار قدرة برنامج حاسوبي على محاكاة محادثة كتابية آنية مع قاضٍ بشري.
في عام ١٩٥٧، أحدثت “البنى النحوية” لتشومسكي ثورة في علم اللغويات من خلال طرح مفهوم “القواعد النحوية الشاملة”. كانت هذه التراكيب نظامًا قائمًا على القواعد النحوية للغة. ثم انخفض تمويل معالجة اللغة الطبيعية (NLP) بشكل ملحوظ لفترة، مما أدى إلى قلة الأبحاث في هذا المجال حتى أواخر ثمانينيات القرن الماضي. حتى ذلك الحين، اعتمدت معظم أنظمة معالجة اللغة الطبيعية على مجموعة معقدة من القواعد المكتوبة بخط اليد.
وبدءًا من أواخر ثمانينيات القرن الماضي، شهدت معالجة اللغة الطبيعية ثورة مع إدخال خوارزميات التعلم الآلي. وتحققت العديد من النجاحات اللاحقة باستخدام نماذج إحصائية أكثر تطورًا. وقد ركزت الأبحاث الحديثة بشكل متزايد على خوارزميات التعلم غير الخاضعة للإشراف وشبه الخاضعة للإشراف.
العصر الحديث: الطفرة مع النماذج التحويلية والتعلم العميق (منذ 2017)
شهد العقد الماضي تحولاً جذرياً بظهور معمارية المحولات (Transformer) في عام 2017، والتي قدمت آلية “الانتباه الذاتي” (Self-Attention). هذه الآلية تسمح للنموذج بوزن أهمية كل كلمة في النص بالنسبة إلى جميع الكلمات الأخرى، مما يمكنه من فهم السياق بعمق غير مسبوق، بغض النظر عن موقع الكلمات في الجملة.
أدى هذا إلى ظهور جيل جديد من النماذج اللغوية الضخمة قبل التدريب (Large Pre-trained Language Models) مثل:
- BERT (من جوجل، 2018): رائد في فهم السياق من الاتجاهين (اليسار واليمين)، مما أدى إلى طفرات في مهام مثل الإجابة على الأسئلة وتحليل المشاعر.
- GPT سلسلة (من OpenAI، بدءًا من 2018): رائدة في توليد النصوص الإبداعية والمتماسكة، حيث يعتمد كل إصدار (GPT-2, GPT-3, GPT-4) على عدد هائل من المعلمات (مئات المليارات) وكميات هائلة من بيانات التدريب.
- النماذج متعددة اللغات والتخصصات: مثل T5 ومقباس (Mistral) ولياما (Llama) من ميتا، التي توسع في قدرات الفهم والتوليد عبر لغات ومجالات متعددة.
الإحصاءات الحديثة توضح حجم هذه الطفرة:
- حجم البيانات: تم تدريب نموذج GPT-3 على أكثر من 500 مليار كلمة من نصوص الإنترنت والكتب.
- عدد المعلمات: تضخم حجم النماذج من بضعة ملايين من المعلمات في العقد الأول للقرن الواحد والعشرين إلى أكثر من تريليون معلمة في بعض النماذج التجريبية الحديثة.
- الأداء: تفوقت هذه النماذج على البشر في مهام معيارية متخصصة مثل فهم القراءة (على مجموعة بيانات SQuAD) وترجمة اللغات.
الاتجاهات الحالية (2020 وما بعدها)
- النماذج متعددة الوسائط (Multimodal Models): مثل GPT-4V وCLIP، التي تفهم وتربط بين النصوص والصور والصوت في نموذج موحد، مما يقربنا من الذكاء الاصطناعي العام.
- النماذج الفعالة (Efficient Models): التركيز على تقليل حجم النماذج واستهلاكها للطاقة مع الحفاظ على الأداء، لجعلها قابلة للتشغيل على أجهزة الهواتف والحواسيب الشخصية (التدريب الصفري/الوحشي النقل).
- NLP المسؤول والخلاق: مع زيادة قوة النماذج، تبرز تحديات التحيز في البيانات، والأمان، وشفافية القرارات، واستهلاك الطاقة. أصبح تطوير NLP أخلاقي وموثوق مجال بحث نشط.
- التخصيص الدقيق (Fine-tuning) والتوجيه (Prompting): أصبحت تقنيات مثل التدريب على المهام المتعددة والتوجيه البشري (Instruct Tuning) والتعلم من خلال التغذية الراجعة البشرية (RLHF) أدوات أساسية لتوجيه النماذج الضخمة لأداء مهام محددة بدقة عالية وبسلوك مرغوب.
نسنخلص من هذا، تطورت معالجة اللغة الطبيعية من أفكار فلسفية وقواعد يدوية، إلى نماذج إحصائية، وصولاً إلى عصر النماذج العصبية الضخمة القائمة على المحولات التي تظهر فهماً وتوليداً يشبه البشر في كثير من الأحيان. اليوم، لم يعد السؤال “هل تستطيع الآلة فهم اللغة؟”، بل “إلى أي مدى يمكنها الفهم، وكيف نوجه هذه القوة الهائلة بشكل مسؤول ومفيد للمجتمع؟”.
ما هي خوارزميات معالجة اللغات الطبيعية؟
خوارزميات معالجة اللغة الطبيعية هي مجموعات من القواعد الرياضية والحسابية المصممة لتمكين الحواسيب من فهم اللغة البشرية الطبيعية ومعالجتها وتوليدها. تعمل هذه الخوارزميات على تحويل النصوص والكلام إلى تمثيلات رقمية يمكن للحواسيب التعامل معها، مما يجعل اللغة البشرية قابلة للتحليل الآلي. تتراوح هذه الخوارزميات بين الأساليب التقليدية القائمة على القواعد اللغوية والنماذج الإحصائية إلى النماذج العصبية العميقة الحديثة التي تستخدم التعلم الآلي لاكتشاف الأنماط المعقدة في البيانات اللغوية.
تطورت هذه الخوارزميات عبر مراحل متعددة، بدءاً من الخوارزميات البسيطة التي تعتمد على تحليل القواعد النحوية والصرفية، مروراً بالأساليب الإحصائية التي تستخدم احتمالات ظهور الكلمات والعبارات، ووصولاً إلى النماذج العصبية المتقدمة التي تعتمد على تقنيات مثل الشبكات العصبية التلافيفية والشبكات العصبية المتكررة. اليوم، تهيمن معماريات المحولات العصبية (Transformers) على المجال، حيث تتيح خوارزميات مثل الانتباه الذاتي (Self-Attention) للنماذج وزن أهمية كل كلمة في السياق بشكل ديناميكي، مما يمكنها من فهم العلاقات الدلالية والنحوية بعمق غير مسبوق.
تطبق هذه الخوارزميات في مهام متنوعة تشمل التصنيف والتجميع والاستخراج والتحويل والتوليد، وتشكل العمود الفقري لتطبيقات مثل الترجمة الآلية والمساعدات الذكية وتحليل المشاعر وتلخيص النصوص. قوة هذه الخوارزميات تكمن في قدرتها على التعلم من كميات هائلة من البيانات النصية، مما يمكنها من محاكاة الفهم اللغوي البشري بدرجات متفاوتة من الدقة والتعقيد، مع بقاء التحدي الأكبر في تمكينها من فهم السياق الثقافي والسخرية والحدس البشري الذي يميز استخدامنا للغة.
كيف تعمل معالجة اللغة الطبيعية (NLP)؟ فك شفرة لغة البشر للآلة
تخيل أنك تريد تعليم طفل صغير لا يعرف سوى الأرقام (0 و1) كيف يفهم قصيدة أو يجيب على سؤال. هذا هو التحدي الجوهري لمعالجة اللغة الطبيعية (NLP): جسر الهوة بين اللغة البشرية الغنية والغامضة، واللغة الرقمية الحرفية والصارمة للآلات.
لا تفهم الحواسيب المعنى، بل تتعامل مع الإحصاءات والأنماط. لذلك، تقوم خوارزميات NLP بتحويل “الفوضى” الإبداعية للغة البشر إلى “نظام” رياضي يمكن قياسه وتحليله. تمر هذه الرحلة بثلاث مراحل رئيسية، أشبه بتحضير وجبة طهي معقدة:
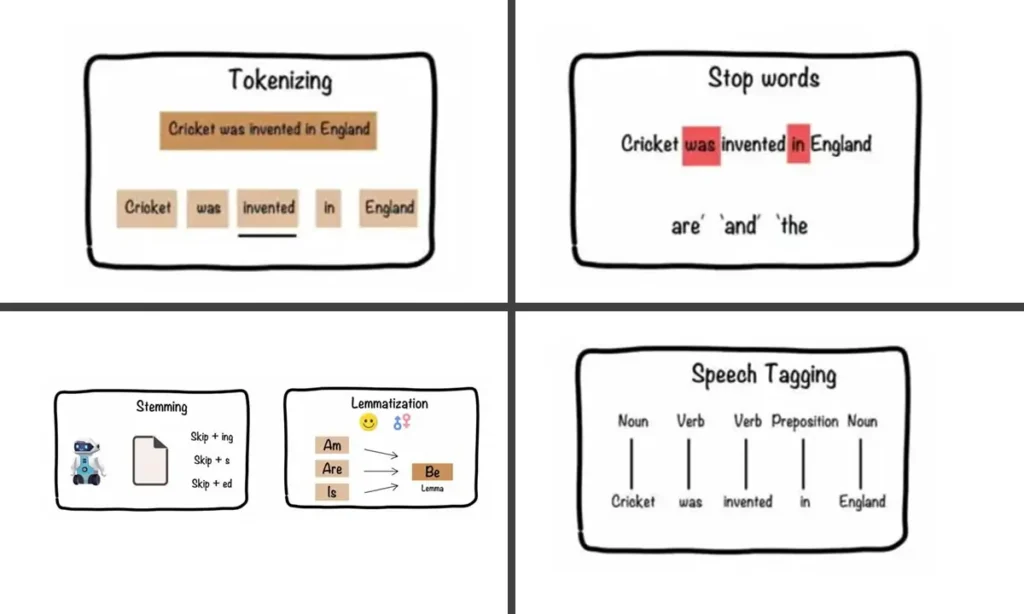
المرحلة الأولى: التحضير والتنظيف – المعالجة المسبقة للبيانات
قبل أن تبدأ الآلة في “الفهم”، يجب تنظيم البيانات الخام (نص، صوت محول إلى نص) وجعلها في شكل مقروء للخوارزميات. هذه الخطوة حاسمة وتشمل:
- التجزئة (Tokenization): تقطيع الجملة إلى وحدات صغيرة (كلمات أو مقاطع). مثل تقطيع الخضروات قبل الطهي.
- مثال:
"كيف حالك؟"→ ["كيف","حالك","؟"]
- مثال:
- التجذيع والتصريف (Stemming & Lemmatization): اختزال الكلمات إلى جذرها الأساسي لتقليل التعقيد.
- مثال:
"يركض","ركض","ركضان"← جميعها تختزل إلى الجذر “رَكَضَ”.
- مثال:
- إزالة كلمات التوقف (Stop Words Removal): حذف الكلمات الشائعة التي لا تحمل معنى دلالياً كبيراً في السياق (مثل: “في”، “إلى”، “هل”، “ال”).
- مثال:
"القطة تجري في الحديقة بسرعة"←["قطة", "تجري", "حديقة", "بسرعة"].
- مثال:
- وسم أجزاء الكلام (POS Tagging): تحديد الدور النحوي لكل كلمة (اسم، فعل، صفة، إلخ).
- مثال:
"الطالب المجتهد يذاكر دروسه"← (الطالب: اسم), (المجتهد: صفة), (يذاكر: فعل), (دروسه: اسم).
- مثال:
الهدف النهائي من هذه المرحلة: تحويل النص إلى قائمة منظمة من “الوحدات النظيفة” الجاهزة للتحليل.
المرحلة الثانية: الفهم والتمثيل – تحويل الكلمات إلى أرقام (التضمين)
الكلمات بالنسبة للآلة مجرد رموز. المفتاح هو تمثيلها كمتجهات رقمية (قوائم أرقام) تحمل معنى وعلاقات.
- الفكرة القديمة (مثل: كيس الكلمات): تحسب تكرار الكلمات ولكنها تفقد السياق. جملة “جيد ليس سيئاً” وجملة “سيئ ليس جيداً” قد تحصلان على نفس التمثيل!
- الفكرة الحديثة (التضمينات السياقية مثل BERT, GPT): هنا تحدث المعجزة. كل كلمة تحول إلى متجه فريد (نقاط في فضاء ذي أبعاد عالية) بحيث تعبر المسافة والاتجاه بين هذه النقاط عن العلاقة الدلالية بين الكلمات.
- نتيجة سحرية: في هذا الفضاء الرياضي، تكون الكلمة “ملك” قريبة من “ملكة” بنفس المسافة التي تكون فيها “رجل” قريبة من “امرأة” (علاقة: الملك – الملكة = رجل – امرأة). وكذلك تكون كلمة “باريس” قريبة من “فرنسا” كما “برلين” قريبة من “ألمانيا”.
الهدف النهائي من هذه المرحلة: إنشاء “خريطة معنوية” رقمية للغة، حيث العلاقات بين الكلمات مُعرفة رياضياً.
المرحلة الثالثة: التطبيق والتنفيذ – النماذج والتدريب
بعد أن أصبح لدينا تمثيل رقمي ذكي للنص، نمرره إلى نموذج (عادة شبكة عصبية عميقة) يتم تدريبه على مهمة محددة.
- التدريب: نعرض للنموذج آلاف أو ملايين الأمثلة (نص + الإجابة الصحيحة أو التصنيف المناسب).
- مهمة تحليل المشاعر: نعطيه مراجعات:
"الفيلم رائع"← (مشاعر إيجابية)،"الخدمة سيئة"← (مشاعر سلبية). - مهمة الترجمة: نعطيه أزواج جمل:
"Hello world"←"مرحباً أيها العالم". - يتعلم النموذج من هذه البيانات الأنماط الإحصائية الخفية والتي تسمى الترميز التي تربط البنية اللغوية بالمخرجات المطلوبة. تشير الإحصاءات إلى أن نماذج مثل GPT-3 تم تدريبها على أكثر من 500 مليار كلمة!
- مهمة تحليل المشاعر: نعطيه مراجعات:
- الاستدلال (التشغيل): بعد اكتمال التدريب، يصبح النموذج جاهزاً للعمل. الآن، عندما تدخل له جملة جديدة (مثل استفسار لمساعد ذكي)، يقوم بما يلي:
- معالجتها مسبقاً.
- تحويل كلماتها إلى متجهات سياقية.
- استخدام الأنماط التي تعلمها للتنبؤ بأفضل رد أو إجراء (كتابة رد، تلخيص، ترجمة، إلخ).
خلاصة مبسطة:
- التنظيف: تقطيع النص وتنقيته.
- التحويل: جعل الكلمات أرقاماً ذكية تحمل معناها وعلاقاتها.
- التعلم: تعليم النموذج على أمثلة كثيرة حتى يتعلم الربط بين هذه الأرقام والمهمة المطلوبة (رد، ترجمة، تحليل).
- العمل: استخدام النموذج المتعلم لفهم النصوص الجديدة والتفاعل معها.
تتيح هذه العملية لسيري فهم طلبك، ولجوجل ترانسليت توفير ترجمة متماسكة، وأدوات التدقيق اللغوي لتصحيح الأخطاء الإملائية والنحوية والدلالية. الأمر ليس سحرًا؛ بل هو رياضيات لغوية معقدة وتعلم آلي عميق يحول كلماتنا إلى عالم تفهمه أجهزة الكمبيوتر.
أهم 4 مراحل في بناء أنظمة معالجة اللغة الطبيعية
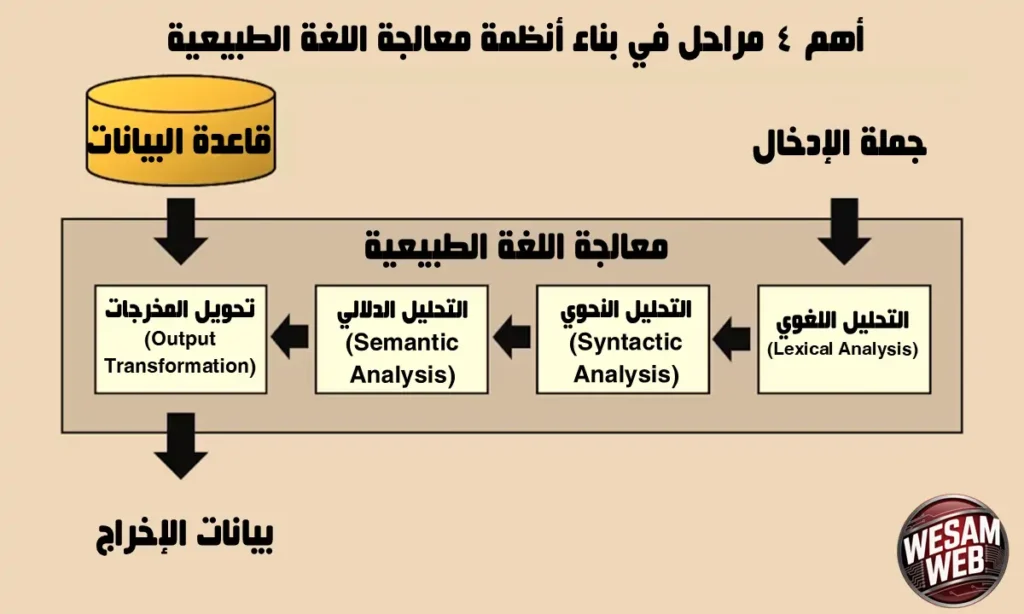
بشكل عام، تعتمد معالجة اللغة الطبيعية (Natural Language Processing – NLP) على سلسلة من المراحل المترابطة التي تهدف إلى تحويل اللغة البشرية، المكتوبة أو المنطوقة، إلى شكل يمكن للآلة فهمه وتحليله ومعالجته بدقة. تشمل هذه العملية أربع مراحل أساسية تمثل الأساس الذي تُبنى عليه معظم أنظمة NLP الحديثة، وهي:
- التحليل اللغوي (Lexical Analysis)،
- التحليل النحوي (Syntactic Analysis)،
- التحليل الدلالي (Semantic Analysis)،
- تحويل المخرجات (Output Transformation).
وفيما يلي شرح موسع لكل مرحلة من هذه المراحل:
أولاً: التحليل اللغوي (Lexical Analysis)
تعرف هذه المرحلة أيضًا باسم Tokenization، وهي الخطوة الأولى في مسار معالجة اللغة الطبيعية. في هذه المرحلة، يتم تقسيم الجملة أو النص إلى وحدات أصغر تسمى رموزًا أو وحدات لغوية (Tokens)، وقد تكون هذه الوحدات كلمات مفردة، أو علامات ترقيم، أو حتى مقاطع لغوية (Subwords).
لا يقتصر دور التحليل اللغوي على التقسيم فقط، بل يشمل أيضًا:
- التعرّف على نوع كل كلمة (اسم، فعل، حرف، إلخ) – Part of Speech Tagging (POS Tagging)
- تقليل الكلمات إلى أصلها اللغوي باستخدام Stemming أو Lemmatization
- إزالة الكلمات الشائعة غير المؤثرة (Stop Words) في بعض التطبيقات
تهدف هذه العملية إلى تجهيز النص وفهم مكوّناته الأولية قبل الانتقال إلى مراحل تحليل أعمق وأكثر تعقيدًا.
ثانيًا: التحليل النحوي (Syntactic Analysis)
تعرف هذه المرحلة باسم Parsing، وتهدف إلى فهم البنية النحوية للجملة وكيفية ارتباط الكلمات بعضها ببعض وفقًا لقواعد اللغة. في هذه المرحلة يتم:
- تحديد العلاقات بين الكلمات والعبارات ضمن الجملة
- تحليل ترتيب الكلمات وبناء هياكل نحوية صحيحة
- تمثيل العلاقات في صورة هياكل شجرية تُسمى Parse Trees أو Syntax Trees
- التعرف على الأجزاء الأساسية للجملة مثل الفاعل (Subject)، والفعل (Verb)، والمفعول به (Object)
يساعد التحليل النحوي النظام على فهم بنية الجملة وليس مجرد كلمات منفصلة، مما يُمكّنه من التعامل مع التراكيب اللغوية المعقدة بشكل أكثر دقة.
ثالثًا: التحليل الدلالي (Semantic Analysis)
في مرحلة التحليل الدلالي (Semantic Analysis) ينتقل النظام من مستوى البنية النحوية إلى مستوى المعنى. حيث يتم ربط الكلمات والتراكيب بمعانيها الحقيقية، وفهم الرسالة الكامنة خلف النص، بغضّ النظر عن اللغة المستخدمة.
تشمل هذه المرحلة عددًا من العمليات المهمة مثل:
- فهم معنى الكلمات في سياقها (Word Sense Disambiguation)
- تحليل العلاقات بين المفاهيم (Semantic Relations)
- التعرف على الكيانات المسماة مثل الأشخاص، الأماكن، والمنظمات – Named Entity Recognition (NER)
- استخراج المعنى على مستوى العبارات، الجمل، الفقرات، وأحيانًا النص الكامل
وتهدف هذه العملية إلى منح النظام القدرة على استيعاب المقاصد، وليس فقط الكلمات، وهو ما يعد خطوة أساسية في تطبيقات مثل الترجمة الآلية، وتحليل المشاعر (Sentiment Analysis)، والإجابة عن الأسئلة (Question Answering).
رابعًا: تحويل المخرجات (Output Transformation)
في هذه المرحلة الأخيرة، يتم إنتاج المخرجات النهائية (Output) بناءً على النتائج المستخلصة من التحليل الدلالي للنص أو الكلام. ويختلف نوع المخرج حسب طبيعة التطبيق المستخدم.
قد تكون المخرجات على سبيل المثال:
- ترجمة نص من لغة إلى أخرى (Machine Translation)
- إكمال جملة أو اقتراح نص (Text Autocomplete)
- تصحيح الأخطاء النحوية والإملائية (Grammar & Spell Checking)
- توليد ردود ذكية في روبوتات المحادثة (Chatbot Responses)
- تلخيص نصوص طويلة (Text Summarization)
يتم ضبط هذه المخرجات بحيث تتوافق مع الهدف الذي صمم من أجله التطبيق، سواء كان تعليميًا، تجاريًا، طبيًا، أو ترفيهيًا.
دور التعلم العميق في أنظمة NLP الحديثة

في التطبيقات الحديثة لمعالجة اللغة الطبيعية، ولا سيما خلال السنوات الأخيرة، أصبح الاعتماد كبيرًا على تقنيات التعلّم العميق (Deep Learning) والشبكات العصبية المتقدمة مثل Transformers ونماذج اللغة الكبيرة (LLMs).
على سبيل المثال، في عام 2016، قام Google Translate بالتحول إلى استخدام الشبكات العصبية العميقة عبر ما يعرف بـ Neural Machine Translation (NMT)، مما أدى إلى تحسّن هائل في جودة الترجمة ودقتها الطبيعية مقارنة بالأنظمة التقليدية القائمة على القواعد (Rule-Based Systems) أو النماذج الإحصائية (Statistical Models).
وتستخدم اليوم نماذج متقدمة مثل:
- BERT – Bidirectional Encoder Representations from Transformers
- GPT – Generative Pre-trained Transformer
- T5 – Text-to-Text Transfer Transformer
في فهم اللغة، وتوليد النصوص، والتلخيص، والترجمة، وإنشاء المحتوى بشكل يحاكي التفكير البشري إلى حدٍّ كبير.
أهم استخدامات معالجة اللغة الطبيعية
تساعد معالجة اللغة الطبيعية (NLP) أجهزة الكمبيوتر من فهم الكلام البشري وتحليله وتمثيله، بل وحتى إنتاج لغة طبيعية تُحاكي التواصل البشري. ولهذا السبب، تعد من أكثر تقنيات الذكاء الاصطناعي استخدامًا اليوم، حيث تدمج في عشرات التطبيقات اليومية في التعليم والطب والتجارة والإعلام وخدمة العملاء. فيما يلي شرح محدث وموسع لأهم استخدامات معالجة اللغة الطبيعية:
التدقيق الإملائي والنحوي
كان الهدف الأساسي لأدوات التدقيق النحوي والإملائي، مثل Writer’s Workbench، هو اكتشاف الأخطاء المتعلقة بأسلوب الكتابة وعلامات الترقيم. ومع ذلك، مع تطور تقنيات معالجة اللغة الطبيعية (NLP) ودمجها مع التعلم الآلي والتعلم العميق، أصبحت هذه الأدوات قادرة على اكتشاف:
- الأخطاء الإملائية (Spelling Errors)
- الأخطاء النحوية (Grammatical Errors)
- المشكلات الأسلوبية (Style Issues)
- الأخطاء الدلالية (Semantic Errors)
- التركيب غير الصحيح للجملة (Sentence Structure Problems)
ويتم إجراء التدقيق اللغوي باستخدام ثلاث طرق رئيسية:
1. النهج القائم على القواعد (Rule-Based Approach)
يعتمد هذا الأسلوب على خبراء لغويين (Linguists) يقومون بوضع قواعد صارمة تستعمل في:
- تقسيم النص إلى أجزاء صغيرة (Tokenization)
- تعيين نوع الكلمة (Part of Speech Tagging – POS)
- مطابقة القواعد للكشف عن الأخطاء المحتملة
2. النهج المعتمد على تعلم الآلة (Machine Learning-Based)
يعتمد على خوارزميات التعلم المُراقب (Supervised Learning) التي يتم تدريبها على قواعد بيانات لغوية ضخمة. تمكن هذه الخوارزميات من:
- التحليل الإحصائي للجمل
- التعرّف على الأنماط الشائعة للأخطاء
- التنبؤ بالصياغة الأكثر صحة بناءً على البيانات السابقة
3. النهج الهجين (Hybrid Approach)
وهو مزيج بين الطريقتين السابقتين (Rule-Based + Machine Learning) من أجل تحقيق أعلى نسبة دقة.
فعلى سبيل المثال:
- تستخدم القواعد الثابتة في الأخطاء الواضحة مثل استخدام a / an باللغة الإنجليزية
- بينما يُعتمد على تعلم الآلة في فهم السياق والمعنى العام للجملة
الترجمة في NLP
تمتلك تطبيقات الترجمة الحديثة القدرة على الجمع بين النهج المختلفة في الترجمة، مثل:
1. الترجمة المعتمدة على القواعد (Rule-Based Machine Translation – RBMT)
تعتمد على ترجمة الكلمات والتركيبات اعتمادًا على قواعد لغوية ثابتة، بطريقة تشبه عمل القواميس (Dictionaries).
2. الترجمة المعتمدة على تعلم الآلة (Machine Learning & Neural Machine Translation – NMT)
تعتمد على فهم المعنى الكامل للجملة أو الفقرة، وليس مجرد ترجمة كلمة بكلمة. وتقوم هذه النماذج بما يلي:
- تحليل السياق العام للجملة
- فهم العلاقات بين الكلمات
- توليد ترجمة أكثر طبيعية ودقة وسلاسة
ويعد نظام Neural Machine Translation (NMT) أساسًا لمنصات مثل:
- Google Translate
- DeepL
- Microsoft Translator
والتي تعتمد على شبكات عصبية عميقة مثل Transformers وAttention Mechanism.
الشات بوت في معالجة اللغة الطبيعية
الشات بوت (Chatbots) أو روبوتات المحادثة هي أنظمة ذكية تتيح للبشر التواصل مع الآلة بطريقة طبيعية تشبه المحادثة البشرية.
تعتمد الشات بوتات بشكل أساسي على:
- معالجة اللغة الطبيعية (NLP)
- التعرّف على نية المستخدم (Intent Recognition)
- فهم السياق (Context Awareness)
- توليد اللغة الطبيعية (Natural Language Generation – NLG)
وتنقسم إلى عدة أنواع:
- روبوتات قائمة على القواعد (Rule-Based Chatbots)
- روبوتات مدعومة بالذكاء الاصطناعي (AI-Powered Chatbots)
- روبوتات هجينة (Hybrid Chatbots)
وخلال السنوات الخمس الماضية فقط، ازداد الاهتمام بهذه التقنية بما يقارب 5 أضعاف، وذلك بسبب فوائدها الكبيرة في قطاعات مثل:
- الفنادق والسياحة
- البنوك والخدمات المالية
- التجارة الإلكترونية
- العقارات
- الرعاية الصحية
كما يمكن لهذه الأنظمة دمج تقنيات أخرى مثل:
- تحليل المشاعر (Sentiment Analysis)
- تحليل سلوك المستخدم
- عرض صور، خرائط ووسائط متعددة لتحسين تجربة المستخدم (User Experience)
إكمال الجملة في NLP
يعد إكمال الجملة (Sentence Completion) أحد أكثر استخدامات NLP شيوعًا في حياتنا اليومية، حيث نراه عند:
- كتابة الرسائل
- البحث في Google
- الردود التلقائية
- اقتراح الكلمات في تطبيقات المراسلة
ويتم ذلك بالاعتماد على خوارزميات متقدمة من تعلم الآلة والتعلم العميق، أبرزها:
الشبكات العصبية التكرارية
هي خوارزميات تستخدم بكثرة في تطبيقات Deep Learning، وتعمل بطريقة تحاكي اتصالات الخلايا العصبية في الدماغ، حيث:
- تتعامل مع البيانات المتسلسلة (Sequential Data)
- تتذكر السياق السابق للكلمات
- تستخدم حلقات التغذية الراجعة (Feedback Loops)
- تتنبأ بالكلمة التالية بناءً على السياق الزمني للجملة
التحليل الدلالي الكامن (Latent Semantic Analysis – LSA)
تعتمد هذه الطريقة على تحليل العلاقة بين التوكنات (Tokens) داخل النص، حيث يتم:
- تحويل النص إلى مصفوفة علاقات (Relationship Matrix)
- قياس الترابط بين الكلمات
- توقع الكلمة أو الجملة التالية بناءً على الفرضية التوزيعية، التي تنص على:
“الكلمات التي تحمل معانٍ متشابهة تظهر في سياقات متقاربة”
أما الطرق الأبسط من إكمال الجمل، فتعتمد على نماذج Supervised Learning التي قد تعاني أحيانًا من:
- التحيز في البيانات (Data Bias)
- نقص التنوع
- التخصص في مجالات محددة
ومن أبرز النماذج الحديثة المستخدمة في هذا المجال:
- GPT (Generative Pre-trained Transformer) – من OpenAI
- BERT – من Google
- T5 – من Google
وهي قادرة على توليد نصوص شبه بشرية بدرجة عالية من السلاسة والاتساق.
ما هو تنقيب البيانات في معالجة اللغة الطبيعية؟
تمثل تحليلات البيانات (Data Analytics) وتنقيب البيانات (Data Mining) عملية استخراج المعرفة والرؤى من البيانات المهيكلة وغير المهيكلة بهدف اتخاذ قرارات دقيقة قائمة على البيانات.
وهنا تلعب NLP دورًا محوريًا في هذه العملية، حيث تساعد على:
- استخراج النصوص المهمة (Text Extraction)
- تصنيف المعلومات (Text Classification)
- تحليل مشاعر المستخدمين (Sentiment Analysis)
- فهم المحتوى النصي والصوتي بشكل دقيق
وتعد هذه القدرات ضرورية في مجالات مثل:
- تحليل آراء العملاء
- التنبؤ بسلوك المستهلك
- دعم اتخاذ القرار في الشركات والمؤسسات
- تحليل وسائل التواصل الاجتماعي
وبذلك، تصبح معالجة اللغة الطبيعية أداة استراتيجية في عالم الأعمال والبحث العلمي والذكاء الاصطناعي المتقدم.
تطبيقات معالجة اللغة الطبيعية (NLP)
تساعد معالجة اللغة الطبيعية (NLP) البرامج الحاسوبية على ترجمة النص من لغة إلى أخرى، والرد على المحادثات النصية، وتلخيص كميات هائلة من النص بسرعة فائقة (حتى في الوقت الفعلي Real-time). تعتمد المساعدات الرقمية، وبرامج التصحيح التلقائي، وروبوتات الدردشة لخدمة العملاء، والعديد من وسائل الراحة القائمة على النص، جميعها على تقنيات NLP. في هذا القسم، سنشرح فوائد استخدام معالجة اللغة الطبيعية في مجال النص.
تتضمن بعض تطبيقات معالجة اللغة الطبيعية ما يلي:
- الترجمة الآلية (Machine Translation)
- التعرف على الكلام (Speech Recognition)
- تحليل المشاعر (Sentiment Analysis)
- الإجابة على الأسئلة (Question Answering)
- تلخيص النص (Text Summarization)
- روبوتات الدردشة (Chatbots)
- الأنظمة الذكية (Intelligent Systems)
- تصنيف النص (Text Classification)
- التعرف على الأحرف (Character Recognition)
- التدقيق الإملائي (Spell Checking)
- كشف الرسائل غير المرغوب فيها (Spam Detection)
- الإكمال التلقائي (Autocomplete)
- التعرف على الكيانات المسماة (Named Entity Recognition – NER)
- التنبؤ بالكلمات التالية (Predictive Typing)
- استخراج المعلومات (Information Extraction)
والآن، دعونا نستعرض بعضاً من هذه التطبيقات المذكورة بالتفصيل:
1. كشف الرسائل غير المرغوب فيها (Spam Detection)
قد لا يبدو كشف الرسائل غير المرغوب فيها (البريد العشوائي) كواحد من تطبيقات NLP للوهلة الأولى، لكن أفضل التقنيات الحالية (مثل تلك المستخدمة من قبل جوجل في خدمة البريد الإلكتروني Gmail) تعتمد على قدرات تصنيف النص بمساعدة NLP للتمييز بين البريد العادي والرسائل غير المرغوب فيها. تتضمن بعض المؤشرات المستخدمة في التصنيف: الإفراط في استخدام مصطلحات ترويجية معينة، والقواعد النحوية السيئة، واللغة التهديدية، والموضوع غير المناسب، وأسماء الشركات ذات الأخطاء الإملائية، وغيرها.
2. روبوتات الدردشة (Chatbots)
تستخدم المساعدات الافتراضية مثل “سيري” في أنظمة أبل و”أليكسا” في أجهزة أمازون، تقنية التعرف على الكلام لاكتشاف أنماط الأوامر الصوتية، وتستخدم توليد اللغة الطبيعية (NLG) للرد بإجراءات مناسبة أو تعليقات مفيدة.
تتبع روبوتات الدردشة النصية نفس النهج في الرد على النصوص المكتوبة. أفضل روبوتات الدردشة تتعلم كيفية اكتشاف السياق النصي في استفسارات المستخدمين وتستخدمه لتقديم ردود أو خيارات أفضل مع مرور الوقت.
تتلخص الخطوة التالية لهذه البرامج في الإجابة على الأسئلة، مما يتضمن القدرة على الرد على أي نوع من الأسئلة، المتوقعة أو غير المتوقعة، بردود ذات صلة ومفيدة. على سبيل المثال، يستخدم أكثر من 80% من الشركات نوعاً من روبوتات المحادثة للتفاعل مع العملاء، حيث يمكن أن تقلل تكاليف خدمة العملاء بنسبة تصل إلى 30%.
3. الترجمة الآلية (Machine Translation)
من التطبيقات الرئيسية الأخرى لمعالجة اللغة الطبيعية الترجمة الآلية، والتي تستخدم لتحويل النص أو الكلام من لغة طبيعية (الإدخال) إلى لغة طبيعية أخرى (الإخراج). أصبحت خدمات مثل ترجمة جوجل (Google Translate) تترجم أكثر من 100 مليار كلمة يومياً، معتمدًة على نماذج متقدمة مثل Transformer التي حسنت الدقة بشكل كبير مقارنة بالطرق الإحصائية القديمة.
4. تحليل المشاعر (Sentiment Analysis)
في السنوات الأخيرة، أصبحت NLP أداة تجارية ضرورية لكشف الرؤى الخفية في البيانات، وخاصة على وسائل التواصل الاجتماعي. باستخدام تحليل المشاعر، يمكن تحليل المنشورات والردود على وسائل التواصل الاجتماعي لاستخراج المواقف والمشاعر تجاه المنتجات أو الإعلانات أو الأحداث.
يمكن للشركات بعد ذلك استخدام هذه المعلومات في تصميم المنتجات، والحملات الإعلانية، وغيرها. على سبيل المثال، يمكن لنظام تحليل المشاعر تتبع ردود الفعل على إطلاق منتج جديد في الوقت الفعلي، مما يسمح للشركات بقياس التأثير الفعلي والتكيف بسرعة.
5. تلخيص النص (Text Summarization)
يستخدم تلخيص النص تقنيات NLP لهضم كميات هائلة من النصوص الرقمية وإنشاء ملخصات لفهارس البحث، أو قواعد البيانات، أو للقراء المشغولين الذين ليس لديهم وقت لقراءة النص الكامل. تستخدم أفضل برامج تلخيص النط المنطق الدلالي وتوليد اللغة الطبيعية (NLG) لإنتاج نص ملائم يتناسب مع سياق النص الأصلي (سواء كان رياضيًا أو إخباريًا، إلخ) ويقدم استنتاجات وخلاصات دقيقة.
تستخدم الكثير من منصات الأخبار والتقارير المالية هذه التقنية لتقديم موجز سريع، حيث يمكن اختصار تقرير مالي من 5000 كلمة إلى 500 كلمة مع الحفاظ على النقاط الرئيسية.
6. حل الغموض (Word Sense Disambiguation)
عملية حل غموض المعنى هي اختيار المعنى المناسب للكلمة من بين عدة معانٍ محتملة من خلال منهج التحليل الدلالي. وبناءً عليه، يتم اختيار الكلمة التي يتوافق معناها بشكل أكبر مع النص المحدد. على سبيل المثال، تحدد العملية معنى كلمة “سِير” في جملة “برنامج سِير الذكي” بخلاف معناها في جملة “سَيْرُ الحجاج نحو مكة”. تعد هذه التقنية حاسمة لفهم السياق، حيث أن أكثر من 40% من الكلمات في اللغات الطبيعية لها أكثر من معنى.
7. التعرف على الكيانات المسماة (Named Entity Recognition – NER)
يحدد التعرف على الكيانات المسماة (NER) الكلمات أو العبارات ككيانات مفيدة. على سبيل المثال، يحدد NER كلمة “الرياض” كموقع، وكلمة “سلمان” كاسم شخص. يتم تطوير خوارزميات مفيدة في هذا المجال بشكل سنوي، وتستخدم على نطاق واسع في استخراج المعلومات من المقالات الإخبارية والمستندات القانونية، حيث يمكن أن تصل دقة أفضل الأنظمة الحديثة إلى أكثر من 95% في تحديد الأسماء والأماوان والتواريخ.
8. معالجة اللغة الطبيعية في المجال الطبي
تمكن NLP من تشخيص الأمراض والتنبؤ بها بناءً على السجلات الصحية الإلكترونية ووصف المريض نفسه. يتم استكشاف هذه القدرة في ظروف صحية متنوعة، بدءاً من أمراض القلب والأوعية الدموية وصولاً إلى الاكتئاب وحتى الفصام.
على سبيل المثال، “Comprehend Medical” هي إحدى خدمات أمازون التي تستخدم NLP لاستخراج الحالات المرضية والأدوية ونتائج العلاج من ملاحظات الأطباء، وتقارير التجارب السريرية، والسجلات الصحية الإلكترونية الأخرى. أظهرت دراسة أن استخدام NLP لتحليل ملاحظات الأطباء الحرّة يمكن أن يحسن اكتشاف حالات مثل تعفن الدم (Sepsis) بمعدل أسرع بست ساعات مقارنة بالطرق التقليدية.
9. التعرف على الكلام (Speech Recognition)
تشمل تطبيقات معالجة اللغة الطبيعية مجالات مختلفة مثل التعرف على الكلام، حيث يتم تحويل المحتوى الصوتي إلى نص. يمكن استخدام هذه التقنية في تطبيقات الهواتف المحمولة، وأتمتة المنازل الذكية، واسترجاع الفيديو، والقياسات الحيوية الصوتية (المصادقة عبر الصوت)، وواجهات المستخدم الصوتية، وتحويل الكلام إلى نص (كما في برنامج Microsoft Word). من أشهر الأمثلة على ذلك المساعد الصوتي “أليكسا” من أمازون. تشير التقديرات إلى أن أكثر من 4 مليارات جهاز مساعد صوتي ذكي ستكون قيد الاستخدام بحلول عام 2025.
10. استخراج المعلومات (Information Extraction)
يعد استخراج المعلومات أحد أهم تطبيقات معالجة اللغة الطبيعية، حيث يستخدم لاستخراج معلومات منظمة (Structured Information) من معلومات غير منظمة (Unstructured Information) أو شبه منظمة (Semi-structured Information)، مما يجعلها مفيدة للغاية للحواسيب والأنظمة.
مثال عملي على ذلك: استخراج أرقام الهواتف أو عناوين البريد الإلكتروني أو أرقام الهويات الوطنية من مجموعة كبيرة من المستندات النصية مثل الصحف أو رسائل البريد الإلكتروني. تستخدم هذه التقنية بكثافة في مجالي الاستخبارات المالية (Financial Intelligence) وأمن المعلومات (Cybersecurity) لرصد الأنماط والشذوذ.
مراحل معالجة اللغة الطبيعية (Natural Language Processing Stages)
عند النظر إلى معالجة اللغة الطبيعية (Natural Language Processing – NLP) من منظور شامل (Macro View)، يمكن تقسيمها إلى محورين أساسيين يشكّلان العمود الفقري لفهم اللغة الإنسانية والتفاعل معها:
- فهم اللغة الطبيعية – Natural Language Understanding (NLU)
- توليد اللغة الطبيعية – Natural Language Generation (NLG)
يشكل هذان الفرعان الأساس الذي تعتمد عليه جميع تطبيقات الذكاء الاصطناعي اللغوي، مثل المساعدات الذكية، وأنظمة الترجمة، ومحركات البحث، وروبوتات المحادثة (Chatbots).
ما هو فهم اللغة الطبيعية؟ (Natural Language Understanding – NLU)
فهم اللغة الطبيعية (NLU) هو أحد أهم وأكثر فروع معالجة اللغة الطبيعية تعقيدًا، ويهدف إلى تمكين الآلات والأنظمة الحاسوبية من فهم المعنى الحقيقي للنص أو للكلام البشري، بدلًا من مجرد قراءة الكلمات بشكل سطحي.
تقوم أنظمة NLU بذلك من خلال استخراج ما يُعرف بـ البيانات الوصفية (Metadata) من المحتوى اللغوي، والتي تشمل:
- المفاهيم (Concepts)
- الكيانات (Entities) مثل: الأسماء، الأماكن، التواريخ
- الكلمات المفتاحية (Keywords)
- المشاعر والانفعالات (Sentiment / Emotion)
- العلاقات بين الكلمات (Relations)
- الأدوار الدلالية (Semantic Roles)
والهدف الرئيسي من NLU هو تحليل النص وفهمه على المستوى الدلالي (Semantic Level) وليس فقط على المستوى اللغوي الظاهري.
التطبيقات العملية لـ NLU
غالبًا ما يتم استخدام NLU في الأنظمة التجارية والتطبيقات الذكية من أجل:
- تحليل شكاوى العملاء المكتوبة أو الصوتية
- فهم استفسارات المستخدمين في محركات البحث
- تحليل مراجعات المنتجات والمحتوى في وسائل التواصل الاجتماعي
- تصنيف النصوص وتحديد نوايا المستخدم (Intent Detection)
المهام الأساسية لـ NLU
تشمل المهام الرئيسية لـ NLU ما يلي:
- تحويل اللغة الطبيعية إلى تمثيل قابل للمعالجة
ويتم ذلك عبر تحويل الكلمات والجمل إلى تمثيل رقمي يُعرف بـ المتجهات العددية (Numerical Vectors) أو التضمينات الدلالية (Word Embeddings) مثل:- Word2Vec
- GloVe
- BERT Embeddings
- تحليل المكونات اللغوية للنص
مثل:- التحليل الصرفي (Morphological Analysis)
- التحليل النحوي (Syntactic Analysis)
- التحليل الدلالي (Semantic Analysis)
- تحليل السياق (Contextual Analysis)
ملاحظة مهمة
قد تتساءل: لماذا يتم تحويل الجمل إلى أرقام؟
السبب بسيط جدًا: لأن الحاسوب لا يفهم سوى الأرقام والبيانات الرقمية، ولا يمكنه التعامل مع الحروف والكلمات كما نفعل نحن البشر. لذلك يتم تحويل اللغة إلى صيغ رياضية يمكن للخوارزميات تحليلها وفهم أنماطها والعلاقات بينها.
ما هو توليد اللغة الطبيعية؟ (Natural Language Generation – NLG)
توليد اللغة الطبيعية (NLG: Natural Language Generation) هو العملية العكسية لـ NLU، حيث تقوم الآلة بعد فهم البيانات أو النتائج الرقمية بـ صياغة نصوص وجمل جديدة بلغة إنسانية مفهومة.
بعبارة أخرى:
إذا كان NLU هو “الفهم”، فإن NLG هو “الحديث والكتابة”.
يشبه NLG المترجم أو الكاتب أو الشاعر، حيث يقوم بتحويل البيانات الرقمية أو النتائج التحليلية إلى:
- جمل مفهومة
- فقرات متناسقة
- تقارير كاملة
- إجابات تلقائية في المحادثات
المهام الأساسية لـ NLG
- Content Planning (تخطيط المحتوى)
- Sentence Planning (تخطيط الجملة)
- Text Realization (إخراج النص النهائي)
وهو ما نشاهده اليوم في تطبيقات مثل:
- ChatGPT
- Google Assistant
- أدوات كتابة المحتوى بالذكاء الاصطناعي
الفرق بين معالجة اللغة الطبيعية NLP و توليد اللغة الطبيعية NLG
| البُعد | فهم اللغة الطبيعية (NLU) Natural Language Understanding | توليد اللغة الطبيعية (NLG) Natural Language Generation |
|---|---|---|
| التعريف العام | فرع من معالجة اللغة الطبيعية (NLP) يركّز على تمكين الآلة من استيعاب المدخلات اللغوية (نص أو كلام) وتحليل نواياها ومعانيها السياقية. | فرع من معالجة اللغة الطبيعية (NLP) يركّز على تمكين الآلة من إنتاج نصوص طبيعية مفهومة وبأسلوب بشري، انطلاقًا من بيانات منظمة أو تمثيل دلالي. |
| الاتجاه في سير العمل | من اللغة → المعنى (تحويل المدخل اللغوي إلى تمثيل دلالي/منطقي) | من المعنى → اللغة (تحويل هيكل دلالي/بيانات إلى مخرج نصّي طبيعي) |
| المهمة الأساسية | الإجابة على: ماذا يقصد المستخدم؟ | الإجابة على: كيف نعبّر عن هذه المعلومة بلغة بشرية؟ |
| المراحل النموذجية |
|
|
| التحديات الرئيسية |
|
|
| أمثلة على التطبيقات |
|
|
| النماذج والتقنيات الشائعة |
|
|
| نوع المدخل/المخرج | المدخل: نص طبيعي (عربي/إنجليزي/إلخ) المخرج: تمثيل دلالي/منطقي (مثل: JSON يحتوي على {"intent": "book_flight", "entities": {"destination": "القاهرة"}}) | المدخل: بيانات منظمة (جداول، قواعد بيانات، تمثيل دلالي) المخرج: نص طبيعي سلس (مثل: "تم حجز رحلة إلى القاهرة يوم الثلاثاء القادم.") |
| العلاقة بـ NLP | جزء من NLP ← يركّز على الجانب التحليلي (نحو "القراءة" و"الفَهم") | جزء من NLP ← يركّز على الجانب الإبداعي/الإخراجي (نحو "الكتابة" و"التعبير") |
| التقييم (المقاييس) |
|
|
| ملاحظة تكاملية | في الأنظمة الكاملة (مثل Chatbots)، يعمل NLU وNLG معًا: 1. يستقبل النظام مدخل المستخدم → يُحلّل عبر NLU لاستخلاص النية والبيانات. 2. تُعالج النية (عبر محرك منطقي أو قاعدة معرفية). 3. تُولّد الإجابة عبر NLG لتُقدّم ردًّا طبيعيًا. → هما وجهان متكاملان لعملة NLP. |
|
يمكن توضيح الفرق بينهما بشكل مبسّط كالتالي:
فهم معالجة اللغة الطبيعية (NLP)
- يهتم بعملية قراءة وفهم وتفسير اللغة
- يأخذ لغة طبيعية كمدخل (Input)
- ينتج مخرجات غير لغوية (مثل: أرقام، تصنيفات، نوايا، علاقات)
- يركز على: التحليل والفهم والاستنتاج
توليد اللغة الطبيعية (NLG)
- يهتم بعملية إنشاء وكتابة اللغة
- يأخذ مدخلات غير لغوية (بيانات، نتائج، رموز)
- ينتج لغة طبيعية كخَرْج (Output)
- يركز على: الصياغة، التعبير، الإبداع اللغوي
✅ ملاحظة مهمة جدًا: يعد NLU أكثر تعقيدًا من NLG، لأن “فهم المعنى” أصعب بكثير من “تكوين جملة صحيحة”.
تحديات معالجة اللغة الطبيعية (NLP)
| اسم التحدي | الوصف والتحليل | أمثلة واقعية / بيانات داعمة |
|---|---|---|
| السخرية والتلميح (Sarcasm & Irony) | من أعقد التحديات في NLP؛ لأنها تعتمد على: • نبرة الصوت (مفقودة في النص المكتوب). • السياق الثقافي والاجتماعي. • الإشارات غير اللفظية (إيماءات، تعابير وجه). النماذج تُخطئ غالبًا لأنها تفسّر النص حرفيًّا دون استيعاب القصد المعاكس. | جملة: "هذا رائع حقًّا!" — قد تعني عكسها تمامًا في سياق ساخر (مثل: بعد فشل نظام تشغيل). في اللغة العربية: "بارك الله فيك... ما قصرت!" بعد خطأ فادح. |
| الغموض الدلالي أو اللغوي (Semantic & Lexical Ambiguity) | وجود كلمات أو جمل تحمل أكثر من تفسير ممكن. يتطلب فهم النية الحقيقية: • تحليل السياق المباشر. • الربط بالسياق العام (النص، المجال، المتحدث). • الاستعانة بقواعد معرفية (Ontologies). | كلمة "عين" في العربية: • عضو البصر. • نبع ماء. • جاسوس. • وحدة في الشطرنج. تشير دراسات لغوية إلى أن أكثر من 40% من الكلمات في اللغات الطبيعية متعددة المعاني. |
| اللهجات العامية واللغة الدارجة (Slang & Colloquialisms) | اللغة اليومية تتطور بسرعة — خصوصًا على منصات التواصل. التحديات: • غياب التوحيد الإملائي والنحوي. • اختصار الكلمات (مثل: "مش" بدل "ليس"). • مزج بين الفصحى والعامية (Code-Switching). • مفردات جديدة لا تظهر في قواميس أو بيانات تدريب قياسية. | كلمات دارجة: • "ياخو" (نداء ودي في الخليج). • "متهكر" (شخص يستخدم الهكر بطريقة فكاهية أو سطحية). • "يابس" (جاف/متعب/مُحبَط — حسب السياق). • "زفت" (قد تعني "سيء" أو "فاشل"). |
| لغات المجالات المتخصصة (Domain-Specific Languages) | كل تخصص (طب، قانون، هندسة، برمجة) له: • مصطلحات فنية فريدة. • هياكل جملية غير شائعة. • اختصارات ومعادلات رمزية. النموذج المدرّب على لغة عامة (مثل الأخبار) يُنتج أخطاء خطيرة عند تطبيقه على سياقات متخصصة. | في الطب: • "المرضى المصابون بـ DKA يحتاجون إلى معالجة بالأنسولين الوريدي." — DKA = الحماض الكيتوني السكري (Diabetic Ketoacidosis). في البرمجة: • "الـ callback يُنفَّذ بعد انتهاء الـ promise." — مصطلحات غير مفهومة خارج السياق التقني. |
| التحيّز في بيانات التدريب (Bias in Training Data) | النماذج تُعيد إنتاج التحيّزات الموجودة في البيانات: • تحيّز جندري (ربط "مهندس" بالذكور، و"ممرضة" بالإناث). • تحيّز عرقي أو لغوي (تمييز ضد لهجات أو أسماء غير غربية). • تحيّز ثقافي (اعتبار بعض القيم "طبيعية" دون وعي). | • نموذج يقترح: "الممرضة تُعدّ القهوة، والطبيب يوقع على القرار." • وفق أبحاث معهد ماساتشوستس للتكنولوجيا (MIT): بعض أنظمة التعرف على الوجوه كانت أقل دقة بنسبة تصل إلى 35% في تحديد جنس الأشخاص ذوي البشرة الداكنة. • في العربية: تحيّز ضد اللهجات غير الخليجية أو المغربية في بعض النماذج. |
| نقص البيانات للغات قليلة الموارد (Low-Resource Languages) | الفجوة الرقمية اللغوية: • تركيز تطوير النماذج على اللغات "الغنية" (الإنجليزية، الصينية، الإسبانية). • غياب مجموعات بيانات ضخمة (نصوص، صوت، تسميات يدوية) للغات أخرى. • صعوبة في تطبيق تقنيات النقل (Transfer Learning) دون وجود نموذج أساسي (Base Model). | لغات تعاني من نقص حاد: • الدارية (الدارجة المغربية). • الأمهرية (إثيوبيا). • الكُردية (خاصة اللهجات غير المدعومة). • اللغات الأمازيغية. مثال: لا يوجد نموذج توليدي دقيق للترجمة من/إلى الدارجة المدعوم تجاريًّا. |
| فهم السياق طويل المدى والمرجعية (Long-range Context & Coreference Resolution) | صعوبة في: • تتبع الضمائر عبر فقرات (من هو "هو"؟ "هي"؟ "هم"؟). • ربط الكيانات المتشابهة (مثل: "أبل" → "الشركة" → "المقر في كوبرتينو"). • فهم التحوّلات الدلالية في النص الطويل. النماذج القصيرة السياق (مثل: Windowed Attention) تفشل هنا. | في مقالة مكوّنة من 10 فقرات: > "بعد أن غادر محمد المكتب، أرسل أحمد رسالة إلى علي. ثم اتصل به بعد ساعة." — من هو "به"؟ محمد؟ أحمد؟ علي؟ أو: > "اشتريتُ أبل جديدة. شاشتها رائعة، ومُعالجها سريع." — "أبل" = فاكهة؟ (مستبعد بسبب "معالج") → الشركة. لكن النموذج قد يخطئ لو كانت الجملة منفصلة. |
✓ ملاحظة تكاملية: رغم هذه التحديات، فإن التطورات في فهم اللغة الطبيعية (NLU)، والتعلم العميق، وتوفر مجموعات بيانات ضخمة، قد مكّنت النماذج من تجاوز عقبات كثيرة. لكن الفهم البشري الكامل — مع التعاطف، والذكاء السياقي، والقدرة على التفسير — لا يزال هدفًا بعيد المدى. |
||
ما هي مميزات وعيوب معالجة اللغة الطبيعية؟
نستعرض في ما يلي بعض المزايا والعيوب التي يمكن ذكرها لمعالجة اللغة الطبيعية.
مميزات معالجة اللغة الطبيعية
- تمكين تحليل البيانات المهيكلة وغير المهيكلة: تسمح لنا NLP بتحليل البيانات من مصادر منظمة (قواعد البيانات) وغير منظمة (وسائل التواصل الاجتماعي، رسائل البريد الإلكتروني، التسجيلات الصوتية)، وهو ما يشكل أكثر من 80% من البيانات العالمية وفقاً لشركة IDC.
- السرعة والكفاءة: يمكن لخوارزميات NLP معالجة ملايين المستندات أو المحادثات في وقت قصير جداً، مما يوفر وقتاً وجهداً هائلاً مقارنة بالمراجعة البشرية.
- أتمتة المهام الروتينية وتحسين الدقة: توفير إجابات دقيقة وشاملة للاستفسارات، وأتمتة مهام مثل التصنيف وتلخيص النصوص والرد على الاستفسارات الشائعة، مما يوفر ما يصل إلى 30% من وقت الموظفين في بعض المهام الإدارية حسب بعض التقديرات.
- التواصل الديمقراطي والوصول الفوري: تتيح للمستخدمين طرح أسئلة بلغتهم الطبيعية في مواضيع متنوعة والحصول على إجابات فورية (مثل محركات البحث، المساعدات الذكية)، مما يجعل المعلومات والخدمات أكثر سهولة.
- الرؤى الاستباقية: تساعد في اكتشاف اتجاهات الرأي والمشاعر (تحليل المشاعر) والأنماط الخفية في كميات هائلة من النصوص، مما يدعم اتخاذ القرار في الأعمال والأبحاث.
عيوب معالجة اللغة الطبيعية
- متطلبات موارد هائلة: تتطلب عملية تدريب النماذج المتقدمة كميات هائلة من البيانات الحاسوبية (Compute Power) وبيانات التدريب، مما يجعلها مكلفة وبصمة كربونية عالية. تدريب نموذج كبير مثل GPT-3 يقدر أنه استهلك طاقة تعادل انبعاثات 552 طنًا من ثاني أكسيد الكربون.
- صعوبة التعامل مع التعقيدات اللغوية: لا تزال تواجه صعوبات كبيرة مع السخرية، واللهجات، والتعابير المجازية، واللغة غير الرسمية، والسياق الثقافي الخاص.
- اعتماد الدقة على جودة البيانات: “القمامة تدخل، قمامة تخرج”. إذا كانت بيانات التدريب غير دقيقة أو منحازة، ستكون مخرجات النموذج كذلك. دقتها ترتبط ارتباطاً مباشراً بدقة وتمثيلية البيانات المُدخلة.
- نقص المرونة والتعميم: العديد من النماذج مصممة لمهام محدودة، وقد لا تتكيف بشكل جيد مع مجالات أو مهام جديدة لم تتدرب عليها بشكل صريح، مما يتطلب جولات إضافية من التدريب الدقيق (Fine-tuning).
- تحديات الخصوصية والأخلاقيات: تحليل النصوص والكلام على نطاق واسع يثير مخاوف جدية حول خصوصية الأفراد وإمكانية استخدام التقنية في المراقبة الجماعية أو التضليل.
توقعاتنا من مستقبل معالجة اللغة الطبيعية (NLP)
معالجة اللغة الطبيعية (NLP)، باعتبارها فرعاً من فروع الذكاء الاصطناعي، تمنح الآلات القدرة على فهم وفك تشفير وتفسير اللغة البشرية. يمكن تدريب نماذج NLP على فهم البيانات النصية والصوتية. اليوم، تُستخدم تكنولوجيا NLP في العديد من الصناعات.
بسبب التطورات في مجال تصميم الرقائق الدقيقة والمعالجات المتخصصة للذكاء الاصطناعي، والتي تؤثر إيجابياً على الاستثمارات ومعدلات تبني التكنولوجيا، تستطيع الشركات الآن إنشاء نماذج NLP أكثر تعقيداً. بفضل نماذج NLP الأكثر كفاءة، قد تتغير حالات الاستخدام الشائعة لهذه التكنولوجيا. نقدم فيما يلي بعضاً من أفضل التوقعات حول مستقبل NLP لتكون عوناً لمديري الأعمال في مختلف القطاعات، حتى يتمكنوا من اتخاذ قرارات استثمارية سليمة بثقة أكبر.
1. النمو المستمر للاستثمار في مجال معالجة اللغة الطبيعية
تشير التقارير إلى أن حجم سوق NLP سيشهد نمواً هائلاً خلال السنوات القادمة. وفقاً للتحليلات، تمتلك أمريكا الشمالية أكبر سوق لـ NLP، بينما تستثمر شرق آسيا بشكل كبير في تطبيقات NLP. يرتبط النمو السريع لسوق NLP بثلاثة عوامل رئيسية:
- تقدم تقنيات تعلم الآلة: يمكن اعتبار رقائق الذكاء الاصطناعي بمثابة العقل لنماذج NLP. بالتالي، توفر الرقائق الأقوى قدرة حاسوبية أعلى للآلات، مما يمكنها من إجراء تفاعلات أكثر شبهاً بالإنسان. تقوم شركات تصنيع رقائق الذكاء الاصطناعي بتصميم معالجات يمكنها معالجة عدد أكبر من المعلمات وزيادة حجم نماذج أنظمة معالجة اللغة الطبيعية. من المتوقع أن يتجاوز حجم سوق الذكاء الاصطناعي التوليدي وحده 1.3 تريليون دولار بحلول عام 2032، مع كون NLP محركاً أساسياً لهذا النمو.
- تحسن جودة وإتاحة البيانات: يمكن اعتبار إتاحة وجودة البيانات عاملاً آخر يعزز قدرات أنظمة معالجة اللغة الطبيعية. لتحسين جودة بيانات التدريب، توجد أدوات متعددة لوضع العلامات على البيانات يمكنها شرح البيانات الصوتية أو النصية. هاتان الخاصيتان تتحدان معاً لتوسيع سوق NLP.
- تزايد توقعات العملاء: وفقاً للبحوث، يرغب العديد من مديري الأعمال في تغيير طريقة إدارتهم لعلاقات العملاء بالكامل لمواكبة الاحتياجات المتغيرة للعملاء. تجبر توقعات العملاء للتفاعل السريع مع العلامات التجارية الشركات على تنفيذ نماذج NLP. أظهر استطلاع أن 72% من العملاء يتوقعون تفاعلاً فورياً عند التواصل مع خدمة العملاء.
2. زيادة ذكاء أدوات الذكاء الاصطناعي المحادثاتية (Conversational AI)
أحد الفروع الفرعية لـ NLP هو الذكاء الاصطناعي المحادثاتي، الذي يفهم قصد المستخدم من خلال المدخلات ويقدم له رداً. من المهم معرفة أن هذه التكنولوجيا تعمل خلف الكواليس في:
- روبوتات الدردشة (Chatbots)
- المساعدين الافتراضيين الأذكياء (IVAs)
- الروبوتات الصوتية أو المساعدين الصوتيين
- الموظفين الرقميين (Digital Workers)
بفضل التطورات في نماذج NLP، أصبحت أدوات الذكاء الاصطناعي المحادثاتي قادرة على تمييز تعقيدات اللغة البشرية بشكل أفضل. بالإضافة إلى ذلك، بسبب التحسينات في فهم اللغة الطبيعية (NLU)، ستتواصل هذه الأدوات مع الأشخاص بشكل أكثر فعالية. مع هذه التطورات، من المتوقع أن تكتسب العناصر التالية أهمية أكبر للشركات في المستقبل القريب:
- التجارة المحادثاتية (Conversational Commerce): كاستراتيجية تسويقية جديدة تهدف إلى زيادة راحة العملاء. تستخدم الشركات التي تشارك في التجارة المحادثاتية منصات شاملة، حيث تتواصل روبوتات الدردشة وأدوات المراسلة الجماعية والوكلاء المباشرين مع العملاء عبر قنوات مختلفة مثل واتساب للأعمال، ومسنجر فيسبوك، وتطبيقات الهواتف المحمولة التابعة للشركة، ومواقع الويب، ومراكز الاتصال. تُعد استراتيجية مناسبة لتجارة التجزئة والتجارة الإلكترونية والقطاع الفندقي والسياحي. تشمل حالات الاستخدام: توصية المنتجات باستخدام NLP، ودعم العملاء، وتقييم أهلية التأشيرات.
- الخدمات المصرفية المحادثاتية (Conversational Banking): يمكن اعتبارها تطبيقاً للتجارة المحادثاتية في مجال الخدمات المالية. تستخدم المؤسسات المالية روبوتات الدردشة المصرفية وروبوتات التسهيلات الائتمانية وروبوتات إدارة الأصول للتفاعل مع عملائها. تمكن الخدمات المصرفية المحادثاتية الشركات المالية من أتمتة استقبال العملاء، وعمليات جمع وتقييم المستندات لمنح القروض، وتقديم توصيات بشأن الأسهم.
- الأتمتة الذكية (Intelligent Automation): يمكن للموظفين التفاعل مع تكنولوجيا الأتمتة الذكية مثل “الموظفين الرقميين”، وبفضل الذكاء الاصطناعي المحادثاتي، إصدار أوامر لهم لأداء مهام متنوعة. توفر الأتمتة الذكية أتمتة شاملة. يمكنهم العمل باستمرار وبشكل مستقل، مما يجعلهم أدوات فعالة لتمكين الموظفين وزيادة إنتاجيتهم. تشمل حالات الاستخدام: كتابة وإرسال رسائل البريد الإلكتروني، واستخراج البيانات من أدوات ERP والمحاسبة وCRM، وتفسير وتصور البيانات، والتوظيف، وإعداد التقارير.
3. اتجاهات مستقبلية متقدمة في معالجة اللغة الطبيعية (ما بعد 2025)
- النماذج متعددة الوسائط المتكاملة: سيتجه مستقبل NLP نحو الاندماج الكامل مع الرؤية الحاسوبية والصوت في نماذج موحدة (Multimodal Foundation Models). لن تترجم النماذج النص فحسب، بل ستفسر الصور والفيديو في سياق لغوي، مما يمكن إنشاء مساعدين ذكيين قادرين على فهم العالم كما يفعل الإنسان.
- اللغات قليلة الموارد والنماذج الخفيفة: مع تزايد الوعي بأهمية الشمولية الرقمية، ستشهد استثمارات أكبر في تطوير نماذج NLP فعالة للغات قليلة الموارد، ونماذج خفيفة (Small Language Models) يمكن تشغيلها على الأجهزة المحلية (On-Device AI)، مما يقلل التكاليف ويحسن الخصوصية.
- الذكاء الاصطناعي المسؤول والشفاف: سيصبح تطوير آليات للكشف عن التحيز وضمان الشفافية (Explainable AI for NLP) ومراعاة الأخلاقيات أولوية قصوى. ستتطلب الأنظمة استخداماً مسؤولاً لتجنب نشر المعلومات المضللة أو التعزيز غير المقصود للصور النمطية.
- التوليد الإبداعي والتفاعلي: ستتجاوز قدرات توليد النصوص (مثل ChatGPT) مجرد الرد على الأسئلة إلى إنشاء محتوى إبداعي ومعقد بالتعاون مع الإنسان، مثل كتابة السيناريوهات، وتصميم خطط التسويق، والبرمجة بمساعدة الذكاء الاصطناعي (AI-Paired Programming).
- التخصيص الفائق (Hyper-Personalization): ستمكن نماذج NLP من تحليل بيانات المستخدم الفردية (بشكل أخلاقي وآمن) لتقديم تجارب مخصصة للغاية في التعليم (معلم افتراضي شخصي)، والرعاية الصحية (نصائح صحية مخصصة)، والترفيه (خلق قصص تفاعلية حسب ذوق المستخدم).
4. استخدام الشركات لتوليد اللغة الطبيعية (NLG) لإنشاء النصوص
يعد توليد اللغة الطبيعية (NLG)، باعتباره أحد فروع معالجة اللغة الطبيعية (NLP)، تطبيقاً مفيداً للذكاء الاصطناعي لمنتجي المحتوى ومسوقي المحتوى. ومع ذلك، يبدو أن المزيد من الشركات سوف تستخدم أدوات إنشاء النصوص التلقائية والمحررات المدعومة بـ NLP. نذكر فيما يلي الأسباب في هذا الصدد.
1. ترجمة وإعادة صياغة وتحرير المحتوى على نطاق واسع
تقوم الشركات باستثمارات أكبر في التسويق. حيث أن حوالي 60٪ من الشركات تدين بجذب عملاء جدد إلى تسويق المحتوى.
تمتلك NLP القدرة على تسهيل مهام المسوقين للأسباب التالية:
- ترجمة المحتوى: تمكين الترجمة السريعة والدقيقة للمحتوى إلى لغات متعددة، مما يوسع النطاق الجغرافي. تستخدم شركات مثل Airbnb وBooking.com NLG لترجمة آلاف أوصاف العقارات والتعليقات تلقائياً.
- إعادة صياغة المحتوى (Paraphrasing): إنتاج نسخ متعددة من نفس الرسالة التسويقية أو المقال لاستهداف قنوات أو جماهير مختلفة، مع الحفاظ على المعنى الأساسي وتحسين التنوع.
- تحرير المحتوى: اكتشاف الأخطاء النحوية والإملائية وتحسين جودة الكتابة ووضوحها ونبرتها تلقائياً. تدمج منصات مثل Grammarly وWriter.com تقنيات NLP متقدمة لهذا الغرض.
- توليد المحتوى: إنشاء محتوى مبدئي أو مسودات لأغراض مثل وصف المنتجات، وتقارير الأداء، وأخبار الشركات، ومنشورات المدونات البسيطة، مما يوفر الوقت والموارد. تشير التقديرات إلى أن استخدام NLG يمكن أن يقلل وقت إنشاء تقارير الأعمال الروتينية بنسبة تصل إلى 90٪.
- تقديم مشورة ملائمة لمحركات البحث (SEO-friendly): اقتراح الكلمات المفتاحية وتحسين كثافتها وتحسين قابلية القراءة لتحسين ترتيب المحتوى في نتائج محركات البحث.
2. تنفيذ تحليل المشاعر من قبل شركات أكثر في قطاعات مختلفة
أحد تطبيقات NLP هو “تحليل المشاعر”، الذي يستخدم البيانات الضخمة كمصدر لاكتشاف الرؤى. في هذا التطبيق، يتم تحليل رضا المستهلك من خلال قياس اتجاه الكلام أو النص (سلبي، محايد، أو إيجابي).
تكتسب أبحاث المشاعر أهمية كبيرة للشركات في مختلف الصناعات. وذلك لأن دراسة سلوك المستهلك تظهر أن هناك رابطة قوية بين رضا العملاء والإيرادات وولائهم. من الصعب جداً قياس مدى رضا المستهلك بدقة دون تنفيذ تحليل المشاعر. يبدو أن القطاعات الثلاثة التالية ستستفيد بشكل كبير من تحليل المشاعر:
- القطاع المالي: مراقبة آراء العملاء حول المنتجات والخدمات المصرفية عبر وسائل التواصل الاجتماعي ومنصات المراجعات، والكشف المبكر عن المخاطر السمعة. تستخدم البنوك تحليل المشاعر لتقييم ردود الفعل على إطلاق منتج جديد أو لفهم أسباب شكاوى العملاء.
- التجارة الإلكترونية: تحليل مراجعات المنتجات لفهم نقاط القوة والضعف تلقائياً، وتصنيف المراجعات، وتوجيه جهود تطوير المنتج. يمكن لخوارزميات NLG حتى تلخيص الآراء الإيجابية والسلبية من آلاف المراجعات لعرضها للمشترين المحتملين.
- الموارد البشرية: تحليل التعليقات في استطلاعات الرأي الداخلية، ومقابلات الخروج، ومراجعات الأداء لفهم معنويات الموظفين واكتشاف مشاكل ثقافة الشركة مبكراً. يمكن أن يساعد ذلك في تقليل معدل دوران الموظفين بنسبة تصل إلى 15٪ وفقاً لبعض الدراسات.
3. زيادة شيوع استخدام المقاييس الحيوية الصوتية (Voice Biometrics)
يوجد للتعرف على الكلام العديد من التطبيقات في الأعمال. ومع ذلك، يبدو أن تطبيقه المحدد المعروف باسم المقاييس الحيوية الصوتية قد يصبح أكثر شيوعاً في المستقبل بسبب تعزيز أمان التحقق من الهوية باستخدام “بصمات الصوت” للمستخدمين كمصدر للتحديد. فيما يلي بعض مزايا المقاييس الحيوية الصوتية:
- الصوت، ونطق الكلمات، ونبرة وطبقة صوت الأفراد هي سمات فريدة من نوعها وتقليدها شبه مستحيل. لذلك، قد توفر المقاييس الحيوية الصوتية أماناً أكبر من كلمات المرور الشائعة. تبلغ دقة بعض أنظمة التحقق من الهوية الصوتية الحديثة أكثر من 99٪.
- كثيراً ما ينسى الأشخاص كلمات مرورهم، وهذا شعور غير سار. توفر المصادقة الصوتية تجربة مستخدم سلسة وخالية من المتاعب.
- تطبيقات عملية: تستخدم البنوك والخدمات المالية (مثل HSBC) بصمات الصوت للتحقق من هوية العملاء عبر الهاتف، مما يقلل الاحتيال ويحسن الأمان. تُستخدم أيضاً في أنظمة التحكم في الوصول الآمنة وفي الأجهزة الذكية المنزلية.
اتجاهات إضافية مستقبلية لاستخدام معالجة اللغة الطبيعية NLP في الشركات
- التواصل الشخصي الفائق (Hyper-Personalized Communication): ستستخدم الشركات NLG لتوليد رسائل بريد إلكتروني وعروض تسويقية وتوصيات منتجات مخصصة للغاية لكل عميل على حدة، بناءً على تاريخ مشترياته وسلوكه وتفضيلاته. يمكن أن يؤدي هذا إلى زيادة معدلات التحويل بنسبة 10-15٪.
- التقارير الآلية والذكية: ستولد الأنظمة تلقائياً تقارير أداء مفصلة وملخصات تنفيذية وشرائح عرض من البيانات الخام، بلغة طبيعية وبتفسيرات ذات صلة. ستصبح هذه ميزة قياسية في أدوات ذكاء الأعمال (BI) مثل Power BI وTableau.
- دعم العملاء المتقدم: لن تقتصر روبوتات الدردشة على الردود المعدة مسبقاً، بل ستستخدم NLG لتوليد ردود ديناميكية ومفصلة ومنطقية على استفسارات معقدة، مما يحسن بشكل كبير تجربة العملاء ويقلل التصعيد إلى وكلاء بشريين.
- إنشاء محتوى تفاعلي وديناميكي: ستستخدم منصات الألعاب والتعليم الإلكتروني NLG لإنشاء حبكات قصصية تفاعلية، وأسئلة، وتفسيرات، وملاحظات شخصية في الوقت الفعلي، مما يجعل التجارب أكثر جاذبية وتكيفاً.
- التواصل الداخلي والإداري: ستساعد NLG في كتابة محاضر الاجتماعات الآلية، وتوليد مذكرات الشركة، وصياغة سياسات الموارد البشرية، وحتى المساعدة في كتابة تقييمات أداء الموظفين.
مستقبل NLP ليس مجرد استمرار للاتجاهات الحالية، بل هو تحول جذري نحو أنظمة أكثر تكاملاً وذكاءً ومسؤولية. ستصبح التفاعلات مع التكنولوجيا طبيعية وشبيهة بالإنسان إلى حد كبير، وستتخلل قدرات فهم اللغة وتوليدها كل جانب من جوانب حياتنا الرقمية والعملية. النجاح سيكون لمن يستطيعون تبني هذه التقنيات مع الحفاظ على القيم الإنسانية والأخلاقية في صميم تطبيقاتها.
التطورات الحديثة والمستقبلية في معالجة اللغة الطبيعية (NLP) من واقع تجربتنا

تشهد نماذج اللغة المتقدمة مثل GPT-4 (المطور من قبل أوبن أيه آي) تقدماً هائلاً، حيث تضم هذه النماذج عدداً هائلاً من المعلمات (1.7 تريليون) وتتعامل مع وحدات الإدخال (Tokens) لمعالجتها عبر الشبكات العصبية. يعد GPT-4 نقلة نوعية بارزة كونه أحد أوائل النماذج واسعة النطاق التي تستطيع تنفيذ مهام معقدة مثل البرمجة وحل مسائل رياضيات بمستوى المرحلة الثانوية.
أما النسخة الأحدث، InstructGPT، فقد تم تحسينها بواسطة البشر لتوليد ردود أكثر اتساقاً مع القيم البشرية ونوايا المستخدمين. في الجهة المقابلة، يقدم نموذج جوجل الجديد “جيمناي” (3 Gemini) تطورات مذهلة في قدرات التفكير واللغة.
أداة Codex، المعتمدة على نموذج GPT-4، تعمل كمساعد للمبرمجين من خلال توليد الأكواد البرمجية بناءً على أوامر نصية طبيعية. وقد تم دمجها بالفعل في منتجات مثل GitHub Copilot التابع لشركة مايكروسوفت، وهي قادرة حتى على إنشاء ألعاب فيديو بسيطة من خلال كتابة تعليمات نصية فقط. كما أظهرت أحدث إبداعات معمل DeepMind التابع لجوجل قدرات في التفكير النقدي والمنطقي تؤهلها لتتفوق على معظم البشر في مسابقات البرمجة.
يمكن تدريب نماذج مثل GPT-4 على أشكال متعددة من البيانات في وقت واحد. على سبيل المثال، تم تدريب نموذج DALL-E 3 من أوبن أيه آي على النصوص والصور معاً ليتمكن من توليد مشاهد أو عناصر خيالية بدقة عالية بناءً على أوامر نصية فقط. كما ظهرت منافسات أخرى مثل Midjourney v6 و Stable Diffusion XL، التي أصبحت متاحة كأدوات رقمية للمجتمع.
فيما يلي مثال على نتيجة تعليمات تمت معالجتها بواسطة خوارزميات مختلفة: “تخيل مشهداً يجسد جوهر الذكاء الاصطناعي والإبداع لمقال عن تطورات معالجة اللغة الطبيعية. صوّر دماغاً رقمياً محاطاً بشبكات عصبية، مع شاشة تعرض صوراً متنوعة تتراوح بين السريالية والمناظر المستقبلية، لتعكس الإمكانات الإبداعية لـ (اسم النموذج). استخدم خلفية تثير شعور المصفوفة الرقمية، كرمز للتكنولوجيا الأساسية.”
التطبيقات الجديدة المحتملة لمعالجة اللغة الطبيعية
ظهرت مؤخراً تطبيقات جديدة لتحليل المستندات من نوع PDF. على سبيل المثال، تتيح أداة ChatPDF رفع ملف PDF وإجراء محادثة مع المستند مباشرة. تُستخدم هذه الأداة لتصفح الأوراق العلمية والمقالات الأكاديمية والكتب للحصول على المعلومات بسرعة.
هناك أيضاً أدوات تسهّل البحث الببليوغرافي، منها:
- Consensus: أداة ذكاء اصطناعي لتحليل الأبحاث المنشورة في مجلات محكمة واستخلاص الاستنتاجات الرئيسية منها.
- Scite: أداة ذكاء اصطناعي تساعد في العثور على المصادر المناسبة لكتابة الأوراق العلمية.
- Elicit: أداة قادرة على تحديد المقالات ذات الصلة واستخراج المعلومات دون الحاجة لمطابقة كلمات محددة في الاستعلام. يمكنها المساعدة في تمارين استكشافية متنوعة، including التصور والتركيب وترتيب النصوص، وكذلك صياغة الأسئلة المحورية لكتابة التقارير.
- ResearchRabbit: التي يصفها مؤسسوها بـ “سبوتيفاي البحث”، تتيح للمستخدمين إضافة مقالات أكاديمية إلى “مجموعات” تساعد البرنامج على فهم اهتماماتهم وتقديم توصيات جديدة ذات صلة. كما تتيح تصوير شبكة المقالات حسب المؤلفين والمشتركين في شكل رسوم بيانية.
- Scholarcy و PaperDigest: أدوات لتلخيص المقالات الأكاديمية وإبراز الأجزاء الأكثر أهمية، مما يساعد في تحديد مدى ملاءمة المقال بسرعة وسهولة.
كما تظهر تطبيقات جديدة مثل أنظمة الوكلاء المتعددة (Multi-Agent Systems)، التي تتكون من مجموعة من الوكلاء المستقلين الذين يتفاعلون مع بعضهم لتحقيق أهداف محددة. لكل وكيل في هذه الأنظمة قدرته الخاصة على الإدراك واتخاذ القرارات والتنفيذ.
من أنظمة الذكاء الاصطناعي الحالية من هذا النوع:
- AutoGen من مايكروسوفت: يبسّط تنسيق وتحسين وأتمتة سير العمل للنماذج اللغوية الكبيرة. ويوفر وكلاء محادثة قابلة للتخصيص تستفيد من أقوى قدرات النماذج اللغوية مثل GPT-4، مع معالجة قيودها عبر التفاعل مع البشر والأدوات وإجراء المحادثات بين وكلاء متعددين عبر الدردشة الآلية.
- Mixtral (خليط متفرق من الخبراء): نموذج يعتمد فقط على جزء فك التشفير، حيث يختار جهاز التوجيه في كل طبقة ولكل وحدة إدخال (Token) مجموعتين من ثماني مجموعات معلمات (تسمى “خبراء”) لتحليل الوحدة ودمج النتائج. هذه التقنية تتيح تقليل عدد المعلمات في النموذج مع التحكم في التكلفة وزمن الاستجابة. فعلى سبيل المثال، يمتلك Mixtral 46.7 مليار معلمة إجمالية، لكنه يستخدم فقط 12.9 مليار معلمة لكل وحدة إدخال.
بالإضافة إلى ذلك، تظهر نماذج متعددة الوسائط (Multimodal Models) مثل GPT-4 و Gemini Pro. هذه النماذج قادرة على فهم ومعالجة ودمج أنواع متعددة من البيانات أو إشارات الإدخال (نص، صوت، صورة، فيديو، كود برمجي).
من حالات الاستخدام:
- من نص إلى صورة (Text to Image): توليد صورة من وصف نصي.
- من نص إلى موسيقى (Text to Music): توليد مقطوعة موسيقية من وصف نصي.
- من صورة إلى نص (Image to Text): تقديم وصف لعناصر الصورة.
أخيراً، يجري تطوير نماذج معالجة اللغة الطبيعية لمجالات متخصصة (قانونية، تنظيمية، طبية، علمية، إلخ). توجد مواقع توفر قوائم بهذه النماذج المتخصصة، مثل HuggingFace، وبشكل حديث جداً GPT Store.
أهم المصادر للتدريب على معالجة اللغة الطبيعية (NLP) للمبتدئين والمتقدمين
إذا كنت تبحث عن مصادر عالية الجودة لتعلّم معالجة اللغة الطبيعية (Natural Language Processing – NLP)، فهناك مجموعة متنوعة من الدورات، الكتب، والمستودعات مفتوحة المصدر التي تساعدك على الانتقال من مستوى المبتدئين إلى المتقدمين. فيما يلي قائمة بأبرز هذه المصادر:
| اسم المصدر | الوصف | المستوى | الرابط |
|---|---|---|---|
| دورة «معالجة اللغة الطبيعية باستخدام Python» – أكاديمية بيان | دورة شاملة تبدأ من الأساسيات مثل تنظيف النصوص وتجسيدها وتحليلها وصولاً لبناء نماذج أولية لفهم المحتوى أو تصنيفه | مبتدئ إلى متوسط | انتقل إلى الدورة |
| دروس «Python NLP NLTK بالعربي» – منصة معارف | سلسلة فيديوهات باللغة العربية تشرح خطوات معالجة النصوص باستخدام بايثون ومكتبة NLTK | مبتدئ | شاهد الدروس |
| مقالات وأوراق بحثية – قسم AWS حول NLP | تقدم شرحًا نظريًا وتقنيًا لكيفية عمل NLP من منظور الذكاء الاصطناعي واللغويات الحاسوبية | متوسط إلى متقدم | اقرأ المقالات |
| كتاب «Speech and Language Processing» – Daniel Jurafsky & James H. Martin | مرجع أساسي في مجال NLP يغطي مفاهيم نظرية وتقنيات حديثة | متقدم / أكاديمي | حمل الكتاب (PDF مجاني) |
| مستودع GitHub لمشاريع NLP مفتوحة المصدر | يحتوي على أمثلة عملية ومشاريع تعليمية ونماذج جاهزة يمكن تجربتها وتطويرها | متوسط إلى متقدم | تصفح المستودعات |
| دورة «Deep Learning Specialization» – منصة Coursera | قسم خاص بتطبيقات NLP باستخدام الشبكات العصبية العميقة مثل RNN وTransformer | متوسط إلى متقدم | انضم إلى الدورة |
| كتاب «Natural Language Processing with Python» – Steven Bird وآخرون | مرجع عملي لتعلم NLP باستخدام Python ومكتبة NLTK مع أمثلة وتمارين | مبتدئ إلى متوسط | اقرأ الكتاب (مجانًا عبر NLTK) |
| مستودع Hugging Face Transformers | يوفر مكتبة ضخمة من نماذج NLP الجاهزة للتطبيقات المختلفة مثل الترجمة والتحليل الدلالي وتوليد النصوص | متوسط إلى متقدم | استكشف المكتبة |
| دورة «Applied Natural Language Processing» – جامعة ديلاوير عبر edX | تركز على التطبيقات العملية مثل تحليل المشاعر وتصنيف النصوص واستخراج المعلومات | متوسط | ابدأ الدورة |
| مدونة Analytics Vidhya – قسم NLP | تقدم شروحات ومقالات عملية لأحدث تقنيات NLP مع أمثلة كود وتطبيقات حقيقية | مبتدئ إلى متقدم | تصفح المقالات |
الخاتمة
في ختام هذا المقال حول معالجة اللغة الطبيعية (Natural Language Processing – NLP)، يتضح أنها لم تعد مجرد فرع تقني في علوم الحاسوب، بل أصبحت حجر الأساس في تفاعل الإنسان مع الآلة في العصر الرقمي. فقد تناولنا مفهومها، ومراحل عملها الرئيسة، وتطبيقاتها المتعددة مثل الترجمة الآلية، والتحقق من القواعد، وتكملة الجمل، وروبوتات المحادثة، وصولًا إلى دورها المتقدم في تحليل البيانات الضخمة وفهم المشاعر والنوايا البشرية.
كما أكّد المقال أن قوة NLP لا تكمن فقط في قدرتها على معالجة النصوص والأصوات، بل في قدرتها على محاكاة الفهم البشري للغة وتحويله إلى قيمة حقيقية تخدم مجالات التعليم، والطب، والتجارة، وخدمة العملاء، والبحث العلمي. ومع اعتمادها المتزايد على تقنيات التعلّم العميق (Deep Learning) ونماذج الذكاء الاصطناعي المتقدمة مثل Transformers وGPT، فإن مستقبل هذه التقنية يبدو أكثر دقة ومرونة وتأثيرًا من أي وقت مضى.
وفي ضوء هذا التطور المتسارع، يبقى التساؤل قائمًا: كيف يمكن توجيه قوة معالجة اللغة الطبيعية نحو استخدامات أكثر أخلاقية وإنسانية؟ وهل سيكون المستقبل قائمًا على تعاون أعمق بين العقل البشري والآلة في فهم اللغة والتفكير والتواصل؟
إن الإجابة عن هذه الأسئلة لا تمثل نهاية الحديث عن NLP، بل هي بداية لمرحلة جديدة تتطلب منا الوعي، والمسؤولية، والاستعداد لمواكبة ما هو قادم.
