


ربما تكون واحدًا من ملايين مستخدمي ChatGPT وCopilot؛ ولكن هل تعرف بالضبط كيف تعمل روبوتات الدردشة هذه المستندة إلى نماذج اللغة الكبيرة (LLM)؟ تعرف معنا.
في الخريف من عام ٢٠٢٢، انتشرت تكنولوجيا ChatGPT وأثارت دهشة العالم. منذ فترة، باحثو التعلم الآلي يختبرون النماذج اللغوية الكبيرة، لكن الناس العاديين لم يكترثوا كثيراً لهذا الأمر ولم يدركوا قوة هذه النماذج. في الوقت الحالي، سمع الجميع عن مولدات النصوص وروبوتات الدردشة المعتمدة على الذكاء الاصطناعي، وجرب الملايين من الأشخاص، بما في ذلك أنت، هذه الأدوات؛ ومع ذلك، فإننا لا نفهم تمامًا كيفية عمل النماذج اللغوية الكبيرة.
ربما سمعت أن نماذج الذكاء الاصطناعي تعتمد على كميات كبيرة من النصوص لتوقع “الكلمات التالية”. لكن التفاصيل حول كيفية توقع تلك الكلمات لا تزال غامضة. أحد الأسباب الرئيسية هو أسلوب تطوير هذه الأنظمة. فبدلاً من برمجتها بشكل تقليدي، تعتمد تطبيقات مثل ChatGPT على شبكات عصبية وتدرب باستخدام كميات هائلة من النصوص العادية.
نتيجة لذلك، لا أحد يفهم بشكل كامل كيفية عمل النماذج اللغوية الكبيرة. وعلى الرغم من أن الخبراء يملكون معرفة وافية في هذا المجال، فإنهم لا يزالون يسعون للحصول على مزيد من التفاصيل، وهذه العملية تستغرق وقتًا طويلاً، ربما سنوات أو عقودًا حتى تتم.
في هذه المقالة، سنحاول شرح كيفية عمل نماذج اللغة (LLM) بطريقة بسيطة وسلسة، بحيث يمكن للمبتدئين فهم الأساسيات. سنتحدث عن متجهات الكلمات ومدى أهميتها، وكيفية عمل المحولات التي تشكل جوهر أنظمة مثل ChatGPT، وأخيراً، سنناقش كيفية تدريب هذه النماذج والسبب وراء حاجتها لكميات هائلة من البيانات.
ما هو نموذج اللغة الكبير (LLM)؟
نموذج اللغة الكبيرة (Large Language Models – LLM) هو نوع من النماذج الذكية وأدوات الذكاء الاصطناعي التي تستخدم في توليد وفهم النصوص بشكل شبه طبيعي باستخدام التعلم الآلي. يعتمد هذا النموذج على تقنيات التعلم العميق، ويتم تدريبه على مجموعة كبيرة من البيانات اللغوية ليصبح قادراً على فهم اللغة وإنتاج نصوص مفهومة. تاريخيًا، ظهرت أولى النماذج الكبيرة للغة مثل GPT-1 التي طورتها شركة OpenAI في عام 2018. ومنذ ذلك الحين، تطورت هذه النماذج بشكل مستمر، مع ظهور إصدارات متقدمة مثل GPT-3.
مثال على استخدام نموذج اللغة الكبير هو إنشاء المحتوى الإعلامي، حيث يمكن للنماذج الكبيرة أن تولد مقالات أو قصص بناءً على البيانات المتاحة. وتستخدم أيضًا في تطبيقات المساعدة الذكية مثل Siri وGoogle Assistant لفهم أوامر المستخدمين وتقديم الإجابات السليمة.
أمثلة على LLMs
فيما يلي قائمة بأفضل 10 نماذج لغة LLMs على الويب::
- GPT-3
- BERT
- T5
- XLNet
- RoBERTa
- ALBERT
- ELECTRA
- DistilBERT
- GPT-4
- BART
كيفية عمل ناقلات الكلمات (Word Vectors)
لفهم كيفية عمل نماذج اللغة، نحتاج أولاً إلى معرفة كيفية تمثيل الكلمات. نحن البشر نستخدم سلسلة من الحروف لكتابة كل كلمة؛ مثل C-A-T لـ Cat. لكن النماذج اللغوية تفعل الشيء نفسه باستخدام قائمة طويلة من الأرقام تسمى “متجه الكلمات”. يمكن تمثيل كلمة Vector Cat على النحو التالي:
[0.0074، 0.0030، -0.0105، 0.0742، 0.0765، -0.0011، 0.0265، 0.0106، 0.0191، 0.0038، -0.0468، 0.0212-، 0.0091، 0.0030، -0.0563، -0 .0396، -0.0998، -0.0796،… ، 0.0002]لماذا نستخدم مثل هذه القائمة الغريبة؟ دعونا نلقي نظرة على الإحداثيات الجغرافية لبعض المدن. عندما نقول أن واشنطن العاصمة تقع عند 38.9 درجة شمالاً و77 درجة غربًا، فيمكننا تمثيلها كمتجه:
- واشنطن [38.9، 77]
- نيويورك [40.7، 74]
- لندن [0.1، 51.5]
- باريس [2.4- ، 48.9]
وهكذا يمكننا أن نفسر العلاقات المكانية. وبحسب أرقام الإحداثيات الجغرافية فإن مدينة واشنطن قريبة من نيويورك ومدينة لندن قريبة من باريس، لكن باريس وواشنطن متباعدتان.
الكلمات معقدة جدًا بحيث لا يمكن تمثيلها في مساحة ثنائية الأبعاد
نماذج اللغة لها نهج مماثل. يمثل كل متجه كلمة نقطة في الفضاء التخيلي للكلمات، ويتم وضع الكلمات ذات المعاني المتشابهة بالقرب من بعضها البعض (من الناحية الفنية تعمل LLMs على أجزاء من الكلمات تسمى الرموز المميزة، لكننا سنتجاهل هذا التنفيذ في الوقت الحالي). على سبيل المثال، الكلمات الأقرب إلى قطة في مساحة المتجه تشمل كلب، قطة، وحيوان أليف. إحدى المزايا الرئيسية لمتجهات الكلمات مقارنة بسلاسل الحروف هي أنها تسمح بإجراء عمليات على الأرقام لا تستطيع الحروف القيام بها.
لكن الكلمات معقدة للغاية بحيث لا يمكن تمثيلها في مساحة ثنائية الأبعاد. لهذا السبب، تستخدم النماذج اللغوية مسافات متجهة بمئات أو حتى آلاف الأبعاد. لا يمكن للعقل البشري أن يتخيل مساحة بهذه الأبعاد، لكن أجهزة الكمبيوتر يمكنها القيام بذلك بشكل جيد وتقديم نتائج مفيدة عنها.
لقد عمل الباحثون على ناقلات الكلمات لعقود من الزمن، لكن هذا المفهوم أصبح أكثر أهمية في عام 2013 مع تقديم مشروع (word2vec). قامت جوجل بجمع وتحليل ملايين الملفات والمستندات من صفحات الأخبار لمعرفة الكلمات التي تظهر في الجمل المتشابهة. مع مرور الوقت، تم تدريب الشبكة العصبية على التنبؤ بالكلمات القريبة من بعضها البعض في الفضاء المتجه.
كان لدى Google Word Vector ميزة أخرى مثيرة للاهتمام؛ يمكنك “الاستدلال” على الكلمات ذات الحسابات المتجهة. على سبيل المثال، أخذ باحثو Google المتجه “الأكبر”، وطرحوا منه “كبيرًا”، وأضافوا “صغيرًا”. وكانت الكلمة الأقرب إلى المتجه الناتج هي كلمة “أصغر”.
لذلك يمكن لمتجهات الكلمات في Google فهم القياس والتناسب:
- نسبة السويسريين إلى سويسرا تعادل نسبة كمبوديا إلى كمبوديا (الجنسية)
- نسبة باريس إلى فرنسا تعادل برلين إلى ألمانيا (العاصمة)
- نسبة الكلمتين غير أخلاقية ومعنوية، شبيهة بالممكن والمستحيل (العكس)
- نسبة الذكور والإناث مماثلة للملك والملكة (أدوار الجنسين)
لبناء الشبكة العصبية، قامت جوجل بجمع وتحليل ملايين المستندات من صفحات الأخبار
وبما أن هذه المتجهات مبنية على الطريقة التي يستخدم بها البشر الكلمات، فإنها في نهاية المطاف تعكس العديد من التحيزات في اللغة البشرية. على سبيل المثال، في بعض نماذج متجهات الكلمات، يأتي عبارة “طبيب ناقص رجل زائد امرأة” إلى كلمة “ممرضة”. يتم إجراء الكثير من الأبحاث للحد من مثل هذه التحيزات.
ومع ذلك، تلعب ناقلات الكلمات دورًا مهمًا ومفيدًا جدًا في نماذج اللغة؛ لأنها تشفر معلومات دقيقة ولكنها مهمة حول العلاقات بين الكلمات. إذا تعلم نموذج اللغة شيئًا ما عن قطة (على سبيل المثال، يتم أخذها أحيانًا إلى العيادة البيطرية)، فمن المرجح أن ينطبق الشيء نفسه على قطة صغيرة أو كلب. أو إذا كانت هناك علاقة خاصة بين باريس وفرنسا (لغة مشتركة)، فعلى الأرجح أن هذه العلاقة تنطبق أيضًا على برلين وألمانيا أو روما وإيطاليا.
معنى الكلمات يعتمد على السياق
إن رسمًا بسيطًا لمتجه الكلمات لا يجسد حقيقة مهمة حول اللغات الطبيعية: وهي أن الكلمات غالبًا ما يكون لها معانٍ متعددة. انتبه إلى الجملتين التاليتين:
- التقط جون مجلة.
- سوزان تعمل في مجلة.
هنا يرتبط معنى كلمة “مجلة”، ولكن هناك فرق دقيق بينهما. يلتقط جون مجلة مادية، بينما تعمل سوزان في منظمة تنشر المجلات المادية. في المقابل، كلمة مثل هدف يمكن أن يكون لها معنى مختلف تمامًا: وردة أو هدف كرة قدم.
يمكن لنماذج اللغات الكبيرة مثل GPT-4، والتي تم تطوير ChatGPT عليها، أن تمثل نفس الكلمة مع ناقلات مختلفة اعتمادًا على السياق الذي تظهر فيه تلك الكلمة. في هذه النماذج يوجد متجه للزهرة (النبات) ومتجه مختلف للزهرة (كرة القدم)، بالإضافة إلى متجه للمجلة (جسدي) ومتجه للمجلة (المنظمة). كما هو متوقع، يستخدم نموذج اللغة LLM نواقل تشابه للكلمات ذات المعنى المرتبط أكثر من الكلمات الغامضة.
حتى هذه اللحظة لم نقل أي شيء عن كيفية عمل النماذج اللغوية الكبيرة، لكن هذه المقدمة ضرورية لفهم غرضنا.
تم تصميم البرامج التقليدية للعمل على البيانات غير الغامضة. إذا طلبت من جهاز الكمبيوتر الخاص بك حساب 2+3، فليس هناك أي غموض حول معنى 2 أو + أو 3. لكن اللغة الطبيعية مليئة بالغموض الذي يتجاوز الكلمات ذات المعاني المرتبطة أو الكلمات ذات المعاني المختلفة. خذ بعين الاعتبار الأمثلة البسيطة التالية:
- في جملة “طلب العميل من الميكانيكي إصلاح سيارته”، هل كلمة “هو” تشير إلى العميل أم الميكانيكي؟
- في جملة “طلب المعلم من الطالب أن يحل واجبه”، هل كلمة “نفسه” تشير إلى المعلم أم إلى الطالب؟
يمكننا أن نفهم مثل هذه الالتباسات حسب سياق الحديث، لكن لا توجد قاعدة محددة وبسيطة لذلك. علينا أن نفهم أن الميكانيكيين عادةً ما يقومون بإصلاح سيارات العملاء ويقوم الطلاب بواجباتهم المدرسية. توفر متجهات الكلمات طريقة مرنة لنماذج اللغة لفهم معنى الكلمات في أي سياق معين. ولكن كيف؟ سنجيب على هذا السؤال أدناه.
تحويل ناقلات الكلمات إلى التنبؤ بالكلمات
يتم تنظيم نماذج GPT-3 وGPT-4 ونماذج اللغة الأخرى التي تدعم روبوتات الدردشة المدعومة بالذكاء الاصطناعي في عشرات المستويات. تقبل كل طبقة سلسلة من المتجهات كمدخلات (ناقل واحد لكل كلمة في النص المُدخل) وتضيف معلومات للمساعدة في شرح معنى تلك الكلمة وتوقع الكلمة التالية. لنبدأ بمثال أساسي:
كل طبقة من نماذج اللغة LLM عبارة عن محول: بنية شبكة عصبية تم تقديمها لأول مرة في عام 2017 بواسطة Google في ورقة بحثية تاريخية.
المدخلات إلى النموذج الذي تراه في الصورة أعلاه عبارة عن جملة جزئية: “John wants his bank to cash the-” هذه الكلمات، الممثلة كمتجهات نمط word2vec، هي مدخلات للمحول الأول.
يدرك المحول الأول أن wants و cash كلاهما أفعال (يمكن أن تكون كلتا الكلمتين أسماء أيضًا). وقد سلطنا الضوء على هذا المفهوم المضاف باللون الأحمر، ولكن في الواقع، يقوم نموذج اللغة بتخزين الكلمات عن طريق تغيير متجهات الكلمة بطريقة يصعب على البشر تفسيرها. يتم تمرير هذه المتجهات الجديدة، المعروفة باسم “الحالات المخفية”، إلى المحول التالي.
توفر متجهات الكلمات طريقة مرنة لنماذج اللغة لفهم معنى الكلمات في أي سياق معين.
يضيف المحول الثاني نقطتين إضافيتين من موضوع الجملة: أولا، يوضح أن “bank” يشير إلى مؤسسة مالية، وثانيا؛ “his” هو ضمير يشير إلى يوحنا. الآن ينتج المحول الثاني مجموعة من ناقلات الحالة المخفية التي تعكس كل ما تعلمه نموذج اللغة حتى الآن.
الصورة أعلاه توضح نماذج اللغة افتراضية تمامًا. من المؤكد أن برامج نموذج اللغة LLM الحقيقية تتضمن طبقات أكثر؛ على سبيل المثال، يحتوي Transformer وهو أقوى إصدار GPT-3 على 96 طبقة.
تظهر الأبحاث أن الطبقات القليلة الأولى من المحول تركز على فهم تكوين الجملة أو تركيبها وحل نقاط الغموض التي ذكرناها سابقًا. تعمل الطبقات اللاحقة على فهم أعمق وأوسع للنص بأكمله. لا تظهر هذه الطبقات في الصورة حتى لا يكون حجم الرسم التخطيطي كبيرًا جدًا ومربكًا.
على سبيل المثال، عندما يقرأ نموذج اللغة LLM قصة قصيرة، يبدو أنه يتتبع مجموعة متنوعة من المعلومات حول الشخصيات في القصة: الجنس والعمر، والعلاقات مع الشخصيات الأخرى، والمواقع الماضية والحالية، والخصائص الشخصية، والأهداف، والمزيد.
لا يعرف الباحثون بالضبط كيف يتتبع LLMs هذه المعلومات، لكن النموذج يجب أن يفعل ذلك عن طريق تغيير ناقلات الحالة المخفية عند الانتقال من طبقة إلى أخرى. في نماذج اللغة الحديثة، تصبح المتجهات كبيرة جدًا. على سبيل المثال، تحتوي متجهات الكلمات في أفضل إصدار من GPT-3 على 12288 بُعدًا؛ أي أن كل كلمة يتم تمثيلها بقائمة مكونة من 12288 رقمًا.
يمكنك التفكير في كل هذه الأبعاد الإضافية كنوع من مساحة المسودة التي يستخدمها نموذج اللغة لكتابة ملاحظات حول سياق وموضوع كل كلمة. يمكن لكل طبقة أعلى قراءة الملاحظات من الطبقات السابقة وتعديلها. وبالتالي، يحصل النموذج تدريجيًا على فهم أفضل وأكثر دقة للنص الأصلي.
لنفترض أنه لتفسير قصة مكونة من ألف كلمة، لدينا مخطط مشابه للمخطط الموجود في الصورة أعلاه، ولكن مع 96 طبقة. قد تحتوي الطبقة 60 على نواقل تمثل خصائص أخرى لجون؛ على سبيل المثال: الشخصية الرئيسية، رجل متزوج من شيريل، ابنة عم دونالد، مولود في مينيسوتا، وهو الآن مقيم في بويز، يحاول العثور على محفظته المفقودة.
كل هذه الحقائق (وربما غيرها الكثير) تم ترميزها بطريقة ما ضمن قائمة تضم 12288 رقمًا مرتبطًا بكلمة يوحنا. قد يتم أيضًا تشفير بعض هذه المعلومات في 12288 متجهًا ذو أبعاد مرتبطة بكلمات “Sherrill” أو “Donald” أو “wallet” أو “Boys” أو كلمات أخرى في القصة.
الهدف هو أن تقوم الطبقة 96، أو الطبقة الأخيرة من الشبكة، بإنتاج حالة مخفية للكلمة الأخيرة التي يجب أن تحتوي على جميع المعلومات اللازمة للتنبؤ بالكلمة التالية.
عملية عمل المحولات
الآن دعونا نتحدث عما يحدث داخل كل محول. يستخدم المحول عملية من خطوتين لتحديث الحالة المخفية لكل كلمة يتم استلامها من مسار الإدخال.
- في مرحلة الانتباه (Attention)، تنظر كل كلمة حولها وتشارك معلوماتها مع الكلمات التي لها سياق وموضوع مرتبطان.
- في مرحلة التغذية الأمامية (Feed-Forward)، “تفكر” كل كلمة في المعلومات التي تم جمعها في المراحل السابقة وتحاول التنبؤ بالكلمة التالية.
وبطبيعة الحال، الشبكة هي التي تقوم بالخطوات المذكورة أعلاه، وليس الكلمات الفردية. نفسر الأشياء بهذه الطريقة من أجل البساطة للتأكيد على أن المحولات تحلل الكلمات باعتبارها الوحدة الأساسية، بدلا من الجمل أو العبارات الكاملة.
يستخدم المحول عملية من خطوتين لتحديث الحالة المخفية لكل كلمة
يمكّن هذا النهج طلاب LLM من الاستفادة الكاملة من قوة المعالجة المتوازية الهائلة لوحدات معالجة الرسومات الحديثة. بالإضافة إلى ذلك، بهذه الطريقة يمكن لـ LLM التوسع والتوسع إلى مستوى النصوص التي تحتوي على آلاف الكلمات. وهذان المجالان هما بالضبط نفس التحديات التي كانت موجودة في طريق نماذج اللغة القديمة.
يمكنك التفكير في آلية الانتباه كخدمة مطابقة الكلمات. تنظم كل كلمة قائمة مرجعية تسمى متجه الاستعلام (Query Vector) والتي يتم فيها وصف خصائص الكلمات المطلوبة. كما يقوم أيضًا بإعداد قائمة مرجعية أخرى تسمى Key Vector والتي تصف فيها ميزاته.
تقوم الشبكة بمقارنة كل متجه رئيسي بمتجهات الاستعلام للعثور على أفضل الكلمات المطابقة. عند اكتمال تفاصيل المطابقة، تقوم الشبكة بنقل المعلومات من الكلمة التي قامت بإنشاء متجه المفتاح إلى الكلمة التي قامت بإنشاء متجه الاستعلام.
في الفقرات السابقة، أظهرنا محولًا افتراضيًا أدرك أن كلمة “his” تشير إلى جون في الجملة النسبية “John wants his bank to cash the-“. ويمكننا أن نتعمق قليلاً في التوضيحات التالية:
يقول متجه الاستعلام الخاص به his: “أنا أبحث عن اسم يصف شخصًا ذكرًا.” يقول المتجه الرئيسي “John”: “أنا؛ اسم يصف شخصًا ذكرًا. تتعرف الشبكة على تطابق هذين المتجهين وتنقل المعلومات حول ناقل John إلى ناقله his.
تحتوي كل طبقة على عدة رؤوس انتباه، مما يعني أن عملية تبادل المعلومات تحدث عدة مرات بالتوازي في كل طبقة. يركز كل رأس اهتمام على مهمة مختلفة:
- قد يقوم رأس الانتباه بمطابقة الضمائر مع الأسماء، مثل his مع John.
- وقد يسعى طرف آخر إلى إيجاد المعنى الأصلي لكلمة ذات معاني متعددة ومختلفة.
- قد يربط الرأس الثالث عبارات من كلمتين مثل “بيل جيتس”.
- بنفس الطريقة الرؤوس الرابعة والخامسة والأخيرة.
غالبًا ما تعمل هذه الرؤوس بشكل تسلسلي، وتصبح نتائج عمليات طبقة واحدة بمثابة مدخلات لرأس آخر في الطبقة التالية. وبطبيعة الحال، قد تتطلب كل مهمة من هذه المهام العديد من الاهتمامات. قلنا سابقًا أن النسخة الأكبر من GPT-3 تحتوي على 96 طبقة مع 96 رأس انتباه، لذلك في كل مرة يتنبأ هذا النموذج بكلمة ما، فإنه ينفذ 9,216 عملية انتباه.
آلية الاهتمام مثال العالم الحقيقي
تعتمد نماذج اللغات LLMs القائمة على المحولات بشكل كبير على آلية الاهتمام متعدد الرؤوس، والتي تسمح لهم بتسجيل العلاقات طويلة المدى والتمثيلات السياقية. ومع ذلك، فإن عملية الانتباه هذه مكلفة من الناحية الحسابية لإنشاء نص الانحدار التلقائي لأنها تتطلب إعادة حساب العديد من نفس المتغيرات مع كل رمز مميز جديد.
وفي عام 2022، قام الباحثون بتحسين نتائج أحد تنبؤات GPT-2. بدأت القصة حيث أكمل هذا النموذج اللغوي الجملة “-When Mary and John went to the store, John gave a drink to” بكلمة Mary. ووجد الباحثون أن ثلاثة أنواع من رؤوس الانتباه لعبت دورًا في هذا التنبؤ:
- كانت المجموعة الأولى هي الرؤساء الذين نسخوا المعلومات من ناقل Mary إلى المتجه النهائي. المتجه النهائي هو متجه الكلمة الأخيرة على اليمين، والتي من خلالها يتم التنبؤ بالكلمة التالية (هنا الكلمة to)
- المجموعة الثانية كانت الرؤوس التي منعت المتجه الثاني لكلمة John ومنعت نسخ معلوماتها إلى المتجه النهائي.
- كانت المجموعة الثالثة عبارة عن رؤساء تعرفوا على متجهات كلمات John وقاموا بوضع علامة عليها كمعلومات مكررة، مما ساعد الرؤساء السابقين على عدم تكرار معلومات John.
- معًا، تخبر هذه الرؤوس GPT-2 أن الجملة John gave a drink to John لا معنى لها وأنه يجب اختيار John gave a drink to Mary.
ولكن كيف عرف النموذج اللغوي أن الكلمة المتوقعة يجب أن تكون اسم إنسان وليس كلمة أخرى؟ يمكننا أن نفكر في العديد من الجمل المشابهة التي لا تكون فيها كلمة “مريم” اختيارًا جيدًا. على سبيل المثال، في الجملة “عندما ذهب ماري وجون إلى المطعم، أعطى جون مفاتيحه لـ -” الكلمة المنطقية التالية ستكون “نادل”. من المحتمل، من خلال البحث الكافي، أن يتمكن علماء الكمبيوتر من اكتشاف وشرح خطوات أخرى في عملية التفكير GPT-2.
آلية التغذية إلى الأمام
بعد أن تقوم رؤوس الانتباه بنقل المعلومات بين متجهات الكلمات، فإن شبكة التغذية الأمامية “تفكر” في كل متجه كلمة وتحاول التنبؤ بالكلمة التالية. في هذه المرحلة، لا يتم تبادل أي معلومات بين الكلمات وتقوم طبقة التغذية الأمامية بتحليل كل كلمة على حدة. ومع ذلك، تتمتع هذه الطبقة بإمكانية الوصول إلى جميع المعلومات التي تم نسخها مسبقًا بواسطة رأس الانتباه.
توضح الصورة أدناه بنية طبقة التغذية في الإصدار الأكبر من GPT-3:
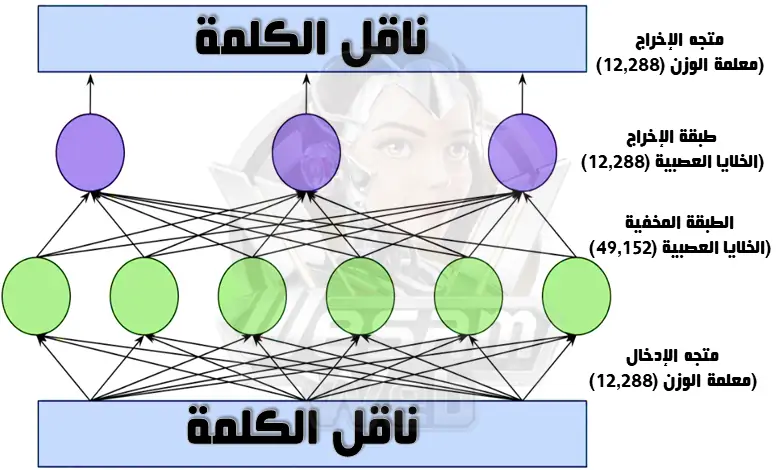
الخلايا العصبية الموضحة في الصورة بدوائر خضراء وأرجوانية هي في الواقع وظائف رياضية تحسب المجموع المرجح لمدخلات الطبقات. يتم تمرير هذا المبلغ إلى وظيفة التنشيط، والتي تحتاج إلى أن تكون على دراية بالشبكات العصبية لفهمها بالكامل.
في الخطوة الأمامية، لا يتم تبادل أي معلومات بين الكلمات ويتم تحليل كل كلمة على حدة.
ما يجعل طبقة التغذية الأمامية قوية هو العدد الكبير من الاتصالات. من أجل التبسيط، قمنا برسم هذه الشبكة بثلاث خلايا عصبية في طبقة الإخراج وستة خلايا عصبية في الطبقة المخفية. يشتمل نموذج GPT-3 على 12,288 خلية عصبية في طبقة الإخراج (المقابلة لعدد متجهات الكلمات) و49,152 خلية عصبية في الطبقة المخفية.
لذا، يوجد في الطبقة المخفية 49,152 خلية عصبية مع 12,288 مدخلًا (وبطبيعة الحال 12,288 معلمة وزن). هناك أيضًا 12,288 خلية عصبية مخرجة مع 49,152 قيمة إدخال (و49,152 معلمة وزن) لكل خلية عصبية. لذلك، سيكون لكل طبقة تغذية أمامية 1.2 مليار معلمة وزن:
- 12,288 × 49,152 + 49,152 × 12,288 = 1.2 مليار
قلنا أنه في هذا النموذج، لدينا 96 طبقة تغذية؛ وهذا يعني أن إجمالي 96 × 1.2 مليار يساوي 116 مليار معلمة، والتي تشكل ما يقرب من ثلثي إجمالي 175 مليار معلمة لـ GPT-3. تظهر الأبحاث أن طبقات التغذية الأمامية تعمل عن طريق مطابقة الأنماط: حيث تتطابق كل خلية عصبية في الطبقة المخفية مع نمط معين في نص الإدخال. تركز الطبقات الأولى على مطابقة كلمات محددة، وتصبح الطبقات اللاحقة أكثر تجريدًا بشكل تدريجي، حيث تتطابق، على سبيل المثال، مع الفواصل الزمنية أو المجموعات الدلالية الأوسع.
كما قلنا من قبل، يتحقق المتصفح من كلمة واحدة فقط في كل مرة. لذلك عندما يصنف عبارة أو تسلسل كلمات “تحديث نسخة من وسام ويب، المؤرشفة” بعنوان متعلق بـ “أدوات الذكاء الاصطناعي”، فإنه في الواقع يصل فقط إلى متجه الكلمة “مؤرشفة” وليس كلمات أخرى مثل الإصدار، وسام ويب، والتحديث. لذلك من المفترض أن طبقة التغذية الأمامية يمكنها أن تقول أن “المؤرشفة” هي جزء من تسلسل مرتبط بالوسائط، لأن رؤوس الانتباه قد نقلت بالفعل المعلومات النصية الضرورية إلى المتجه المؤرشف.
عندما تتطابق الخلية العصبية مع أحد الأنماط، فإنها تضيف معلومات إلى ناقل الكلمات. على الرغم من أن هذه المعلومات ليس من السهل دائمًا تفسيرها، إلا أنه في كثير من الحالات يمكنك اعتبارها بمثابة توقع مبدئي للكلمة التالية.
تعتمد شبكات التغذية الأمامية على المتجهات الرياضية
تقدم الأبحاث الحديثة التي أجرتها جامعة براون مثالاً مثيرًا للاهتمام لكيفية مساعدة طبقات التغذية الأمامية في التنبؤ بالكلمات التالية. في الأقسام السابقة، ذكرنا بحث Google word2vec، والذي استخدم الحسابات المتجهة للاستدلال التناظري. على سبيل المثال، من خلال حساب نسبة برلين إلى ألمانيا، نسب باريس إلى فرنسا. يبدو أن طبقات Feedforward تستخدم نفس الطريقة تمامًا للتنبؤ بالكلمة التالية. طرح الباحثون سؤالاً حول نموذج GPT-2 المكون من 24 طبقة، ثم قاموا بدراسة أداء الطبقات.
- سؤال: أين عاصمة فرنسا؟ الإجابة: باريس. سؤال: أين عاصمة بولندا؟ إجابة:؟
في أول 15 طبقة، كان أفضل تخمين لنموذج اللغة هو كلمة عشوائية. بين الطبقتين 16 و19، توقع النموذج أن الكلمة التالية كانت بولندية. إجابة لم تكن صحيحة، ولكن على الأقل كانت لها علاقة بسيطة بالموضوع. ثم، في الطبقة العشرين، تغير أفضل تخمين إلى “وارسو” وبقي دون تغيير في الطبقات الأربع الأخيرة. وفي الواقع، فقد أضافت طبقة متجهة رقم 20 تربط البلدان بعواصمها المقابلة. في نفس النموذج، استخدمت طبقات التغذية الأمامية حسابات متجهة لتحويل الكلمات الصغيرة إلى كلمات كبيرة وكلمات زمن المضارع إلى زمن الماضي.
لطبقات الانتباه والتغذية الأمامية مهام مختلفة
لقد قمنا حتى الآن بفحص مثالين حقيقيين للتنبؤ بالكلمات بواسطة GPT-2: إكمال الجملة التي قدم فيها جون لماري شرابًا، بمساعدة رؤوس الانتباه، ودور طبقة التغذية الأمامية في أن وارسو هي عاصمة بولندا.
في المثال الأول، تم استخراج كلمة ماري من الموجه أو الأمر النصي المقدم من قبل المستخدم، ولكن في المثال الثاني، لم يتم العثور على كلمة وارسو في الأمر النصي. وكان على النموذج اللغوي أن “يتذكر” حقيقة أن وارسو هي عاصمة بولندا، أي من المعلومات التي حصل عليها من بيانات التدريب.
عندما قام باحثو جامعة براون بتعطيل الطبقة المسبقة التي تربط وارسو ببولندا، لم يعد نموذج اللغة يتوقع وارسو باعتبارها الكلمة التالية. ولكن عندما أضافوا جملة “وارسو عاصمة بولندا” إلى بداية المطالبة، قدم النموذج التنبؤ الصحيح مرة أخرى؛ ربما لأن نموذج اللغة استحوذ على انتباه الانتباه لنسخ “وارسو”.
لذلك نحن نواجه “تقسيمًا واضحًا للعمل”: يقوم رؤساء الانتباه باسترجاع المعلومات من الكلمات السابقة للموجه، بينما تسمح طبقات التغذية الأمامية لنماذج اللغة “بتذكر” المعلومات غير الموجودة في الأمر النصي.
تستمر آلية “Note” عن طريق نسخ الكلمات من الأمر النصي، لكن آلية التغذية الأمامية تتذكر المعلومات غير الموجودة في الأمر النصي.
يمكننا أن نفكر في طبقات التغذية الأمامية كقاعدة بيانات حيث يتم جمع المعلومات من بيانات التدريب السابقة لنموذج اللغة. من المفترض أن طبقات التغذية الأولية تقوم بتشفير الحقائق البسيطة المرتبطة بكلمات محددة، مثل “الوظائف تأتي بعد ستيف”، وتتعامل الطبقات العليا مع العلاقات الأكثر تعقيدًا؛ مثل إضافة ناقل لجعل الدولة عاصمتها.
كيفية تدريس نماذج اللغة
تطلبت العديد من خوارزميات التعلم الآلي المبكرة أمثلة تدريب ذات علامات بشرية. على سبيل المثال، يمكن أن تكون بيانات التدريب عبارة عن صور للكلاب أو القطط مع التسميات “كلب” و”قطة” لكل صورة. أحد الأسباب التي جعلت إنشاء مجموعات بيانات كبيرة لتدريب خوارزميات قوية أمراً مكلفاً وصعباً هو الحاجة إلى العمالة البشرية لتسمية البيانات.
أحد الابتكارات الرئيسية في LLMs هو أنها لا تتطلب بيانات مصنفة بشكل واضح. يتم تدريبهم من خلال محاولة التنبؤ بالكلمة التالية. تعتبر أي مادة مكتوبة تقريبًا، بدءًا من صفحات ويكيبيديا إلى المقالات الإخبارية وحتى أكواد الكمبيوتر، مناسبة لتدريب هذه النماذج.
على سبيل المثال، قد يتنبأ LLM بكلمة “سكر” باعتبارها الكلمة التالية بالنظر إلى الإدخال “أتناول قهوتي مع الكريمة و-“. نموذج اللغة الذي تمت تهيئته حديثًا يكون أداءه سيئًا حقًا في هذا السياق؛ لأن كل معلمة من معلمات الوزن الخاصة بها تبدأ العمل تحت رقم عشوائي تمامًا. ولكن عندما يرصد نفس النموذج عينات أكثر بكثير (مئات المليارات من الكلمات)، يتم تعديل هذه الأوزان تدريجيًا ويتم الحصول على تنبؤات أكثر دقة وأفضل.
سحر LLM هو أنه لا يتطلب بيانات مصنفة
لفهم ذلك بشكل أفضل، تخيل أنك تستحم بماء فاتر. لم تستخدم هذا الصنبور من قبل ولا ترى أي علامات عليه. لذلك تقوم بإدارة المقبض بشكل عشوائي إلى جانب واحد وتشعر بدرجة الحرارة. إذا كان الماء ساخنًا جدًا، قلبته إلى جانب واحد، وإذا كان الماء باردًا جدًا، قلبته إلى الجانب الآخر. كلما اقتربت من درجة الحرارة المناسبة، كلما كانت التغييرات أصغر.
الآن دعونا نجري بعض التغييرات على هذا المثال. أولا، تخيل أنه بدلا من صنبور واحد، هناك 50257 صنبورا. يتوافق كل صنبور مع كلمة مختلفة مثل “كريم” أو “قهوة” أو “سكر” وهدفك هو إطلاق الماء تباعًا من الحنفيات المرتبطة بالكلمات التالية.
وبطبيعة الحال، خلف الحنفيات توجد شبكة متعرجة ولولبية من الأنابيب المتصلة، كما تحتوي الأنابيب أيضًا على العديد من الصمامات. لهذا السبب، إذا خرج الماء من رأس الدش الخطأ، فلن يتم حل مشكلتك بمجرد ضبط مقبض الصنبور. تقوم بإرسال جيش من السناجب الذكية لتتبع الأنابيب إلى الخلف وضبط أي صمامات يرونها على طول الطريق. نظرًا لأن أنبوبًا واحدًا يوفر الماء لعدة حمامات، يصبح العمل أكثر تعقيدًا بعض الشيء. علينا أن نفكر مليًا لفهم الصمامات التي يجب تخفيفها أو تشديدها إلى أي مدى.
لا يمكننا تطبيق هذا المثال على العالم الحقيقي، لأن بناء شبكة من الأنابيب الحلزونية تحتوي على 175 مليار صمام ليس واقعيا أو حتى مفيدا على الإطلاق. ولكن يمكن لأجهزة الكمبيوتر أن تعمل على هذا النطاق بفضل قانون مور.
جميع أجزاء LLM التي ناقشناها حتى الآن، أي الخلايا العصبية في طبقات التغذية الأمامية ورؤوس الانتباه التي تنقل المعلومات النصية بين الكلمات، تعمل كسلاسل من الوظائف الرياضية البسيطة (مضاعفات المصفوفات بشكل أساسي) ويتم تحديد سلوكها من خلال معلمات الوزن القابلة للتعديل . عندما فتحت السناجب في قصتنا الصمامات وأغلقتها للتحكم في تدفق المياه، تتحكم خوارزمية التعلم في تدفق المعلومات في الشبكة العصبية عن طريق زيادة أو تقليل معلمات الوزن.
تتم عملية تدريب النماذج على خطوتين: أولا خطوة “الانتشار الأمامي”، حيث يتم تشغيل الصنبور والتأكد من خروج الماء من الصنبور أم لا. ثم يتم قطع المياه وتحدث مرحلة “الانتشار الخلفي”، مثلما يحدث عندما تقوم السناجب الذكية بفحص الأنابيب وفتح الصمامات أو إغلاقها. في الشبكات العصبية الرقمية، يتم لعب دور السناجب بواسطة خوارزمية تسمى Backpropagation، والتي تقدر التغير في كل معلمة وزن باستخدام الحسابات الرياضية وتتحرك للخلف على طول الشبكة.
إن إكمال عملية الانتشار الأمامي هذه باستخدام عينة ثم الانتشار العكسي لتحسين أداء الشبكة من خلال العينة المذكورة أعلاه يتطلب مئات المليارات من العمليات الحسابية. يتطلب تدريب النماذج اللغوية الكبيرة أيضًا تكرار هذه العملية في العديد من الأمثلة.
أداء مذهل تقدمه نماذج اللغات الكبيرة
ربما تتساءل كيف تسير عملية تدريب نماذج اللغة في الذكاء الاصطناعي بشكل جيد على الرغم من الحسابات التي لا تعد ولا تحصى. في هذه الأيام، يقوم الذكاء الاصطناعي التوليدي بمهام مختلفة لنا، مثل كتابة المقالات أو إنتاج الصور أو البرمجة. كيف يمكن لآلية التعلم هذه إنشاء مثل هذه النماذج القوية؟
أحد أهم الأسباب لذلك هو نطاق بيانات التدريب. لا يمكننا أن نتخيل عدد العينات أو معدلات البيانات التي تتلقاها النماذج اللغوية الكبيرة كمدخلات تدريبية. قبل عامين، تم تدريب GPT-3 على مجموعة من 500 مليار كلمة. ضع في اعتبارك أن الأطفال يتعرضون لحوالي 100 مليون كلمة بحلول سن العاشرة.
على مدى السنوات الست الماضية، قامت شركة OpenAI، مطور ChatGPT، بزيادة حجم نماذجها اللغوية بشكل مستمر. ومع زيادة حجم النماذج، فمن الطبيعي أن تؤدي بشكل أفضل في المهام المتعلقة باللغة. يتم تحقيق ذلك إذا قاموا بزيادة كمية بيانات التدريب بعامل مماثل. لتدريب نماذج لغوية أكبر باستخدام المزيد من البيانات، من الواضح أننا نحتاج إلى قوة معالجة وحوسبة أعلى.
تم إصدار نموذج اللغة الأول لـ OpenAI في عام 2018 تحت اسم GPT-1، والذي استخدم متجهات كلمات ذات 768 بُعدًا وكان يحتوي على 12 طبقة لإجمالي 117 مليون معلمة. وبعد ذلك بعامين، تم تقديم نموذج GPT-3 مع 12288 متجهًا للكلمات ذات أبعاد في 96 طبقة و175 مليار معلمة.
كان عام 2023 هو عام إصدار GPT-4، والذي كان على نطاق أوسع بكثير من سابقه. لم يتعلم كل نموذج حقائق أكثر من سابقاته الأصغر فحسب، بل كان أداؤه أفضل أيضًا في المهام التي تتطلب شكلاً من أشكال التفكير المجرد.
تأمل القصة التالية:
يوجد كيس مليء بالفشار بدون أي شوكولاتة بداخله. ومع ذلك، مكتوب “شوكولاتة” على الكيس. تجد سارة هذه الحقيبة. لم يسبق له أن رأى هذه الحقيبة من قبل ولا يرى ما بداخلها. يقرأ الملصق.
ربما يمكنك تخمين أن سارة تعتقد أنها في كيس من الشوكولاتة وتتفاجأ عندما ترى الفشار. يطلق علماء النفس على قدرة البشر على التفكير في الحالات العقلية للآخرين اسم “نظرية العقل” (ToM). يمتلك معظم الناس هذه القدرة منذ سن المدرسة الابتدائية، ووفقًا للأبحاث، فإن هذه القدرة مهمة للإدراك الاجتماعي البشري.
أحدث إصدار من GPT-3 يؤدي أداء طفل يبلغ من العمر 7 سنوات عند التعامل مع مشكلات “نظرية العقل”
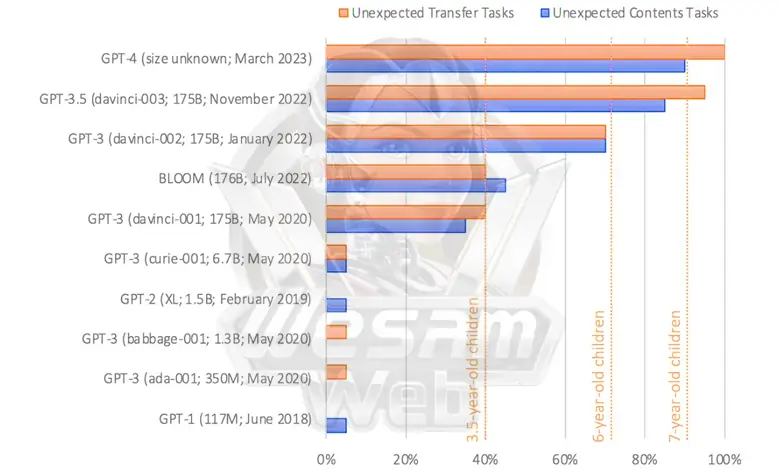
في العام الماضي، نشر عالم النفس في جامعة ستانفورد، ميشال كوسينسكي، بحثًا يدرس قدرة النماذج اللغوية المختلفة على حل مشكلات نظرية العقل. لقد أعطى نصوصًا لل LLMs مثل القصة أعلاه وطلب منهم إكمال الجملة “يعتقد أن الحقيبة مليئة بـ…”. نحن نعلم أن الإجابة الصحيحة هي الشوكولاتة، ولكن من المرجح أن تُكمل النماذج اللغوية الأبسط الجملة بكلمة “الفشار”.
فشل النموذجان اللغويان GPT-1 وGPT-2 في الاختبار، لكن الإصدار الأول من GPT-3 أجاب على أربعين بالمائة من الأسئلة بشكل صحيح. أحدث إصدار من GPT-3 رفع هذا المعدل إلى 90%، وهو مثل طفل عمره 7 سنوات. أجاب GPT-4 بشكل صحيح على حوالي 95% من أسئلة نظرية العقل.
كتب ميشال كوسينسكي في مقالته:
ليس هناك ما يشير إلى أن القدرة على نظرية العقل قد تم تصميمها عمدًا في نماذج لغوية. كما أنه لم يتم إجراء أي بحث حول كيفية تحقيق العلماء لهذا الهدف. ولذلك فمن المحتمل أن هذه القدرة ظهرت بشكل عفوي ومستقل وهي نتيجة ثانوية لزيادة القدرة اللغوية للنماذج.
وبطبيعة الحال، لا يتفق جميع الباحثين في هذا المجال ولا يعتبرون نتائج التجارب دليلا موثوقا على قدرة نظرية العقل على النماذج اللغوية. ربما لأن بعض التغييرات الصغيرة في النصوص المقدمة لاختبار المعتقدات الصحيحة والكاذبة تؤدي إلى نتائج أسوأ بكثير لـGPT-3، ومن حيث المبدأ يُظهر GPT-3 أداءً أكثر تنوعًا في المهام الأخرى التي تقيس نظرية العقل.
كما يرى البعض أن الأداء الناجح لنماذج اللغة هو ظاهرة مشابهة لقصة “هانز الذكي”، هذه المرة بدلا من الحصان، حدث ذلك في نماذج اللغة.
على أية حال، لا يمكننا أن ننكر أنه حتى سنوات قليلة مضت، كان الأداء شبه البشري لنماذج اللغة الجديدة في أشياء مثل اختبارات نظرية العقل غير وارد. بالإضافة إلى ذلك، يتوافق البحث المذكور أعلاه مع فكرة أن النماذج الأكبر تكون أفضل بشكل عام في المهام التي تتطلب تفكيرًا عالي المستوى. في أبريل الماضي، نشر باحثون من مايكروسوفت ورقة بحثية تظهر أن GPT-4 يُظهر علامات مبكرة ومذهلة على “الذكاء الاصطناعي القوي” المعروف باسم AGI؛ ويعني القدرة على التفكير بطريقة معقدة وشبيهة بالإنسان.
على سبيل المثال، طلب أحد الباحثين من GPT-4 رسم وحيد القرن باستخدام لغة برمجة رسومية غير معروفة تسمى TiKZ. استجاب GPT-4 لهذا الطلب ببضعة أسطر من التعليمات البرمجية التي تم استيرادها إلى برنامج TiKZ. وكانت الصور الناتجة بدائية، لكنها أعطت مؤشرات واضحة على أن GPT4 يفهم شكل وحيدات القرن.
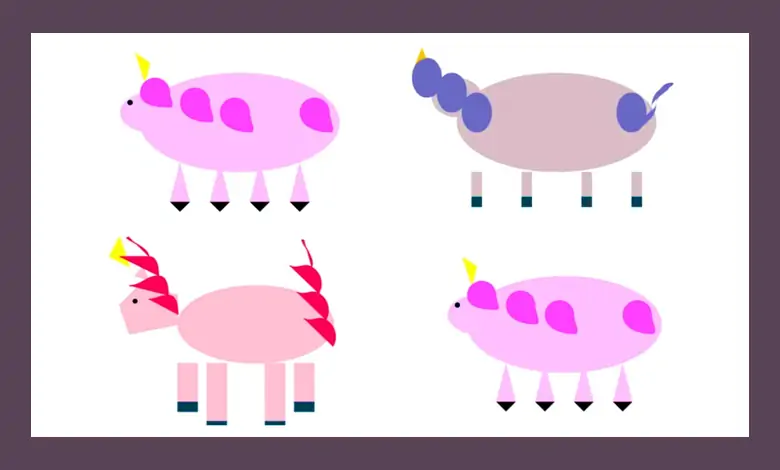
اعتقد الباحثون أنه ربما يكون GPT-4 قد حفظ بطريقة ما رمز رسم وحيد القرن من بيانات التدريب الخاصة به، لذلك طرحوا التحدي التالي: قاموا بتعديل رمز وحيد القرن لإزالة القرن واستبداله ببعض أجزاء الجسم الأخرى. لقد تغيروا أيضًا. ثم طلبوا من هذا النموذج اللغوي أن يعيد القرن إلى الصورة. أجاب GPT-4 على الباحثين بوضع البوق في المكان المناسب.
النقطة المثيرة للاهتمام هي أن بيانات التدريب الخاصة بالإصدار أعلاه من نموذج اللغة كانت مستندة إلى نص بحت ولم تكن هناك صور في مجموعة التدريب. لكن يبدو أن GPT-4 تعلم التفكير بشكل صحيح حول شكل جسم وحيد القرن من خلال تدريبه من خلال كميات هائلة من البيانات النصية.
حتى الآن ليس لدينا أي فكرة عن كيفية قيام LLMs بمثل هذه الأشياء. يعتقد البعض أن نماذج اللغة تحقق فهمًا حقيقيًا للكلمات الموجودة في مجموعة التدريب الخاصة بها. لا يزال آخرون يصرون على أن النماذج اللغوية هي “ببغاوات عشوائية” وتقوم فقط بتكرار تسلسلات معقدة من الكلمات دون فهمها فعليًا.
وبغض النظر عن هذا النقاش، الذي يدخل في توتر فلسفي عميق، فمن المهم التركيز على الأداء التجريبي للنماذج اللغوية. إذا كان النموذج يعطي باستمرار الإجابات المناسبة لنوع من الأسئلة وكنا واثقين من أن النموذج اللغوي لم يتعرض لهذه الأسئلة أثناء التدريب، فقد وصلنا إلى نقطة تحول مهمة للغاية.
ومن خلال فهم العلاقات بين الكلمات، تتعلم نماذج اللغة أيضًا عن العلاقات في الكون
سبب آخر محتمل لنجاح التدريب مع التنبؤ الرمزي اللاحق هو أن اللغة نفسها يمكن التنبؤ بها. ترتبط انتظامات اللغة في كثير من الأحيان (وإن لم يكن دائمًا) بالانتظام في العالم المادي. لذلك، عندما يتعلم النموذج اللغوي العلاقات بين الكلمات، فإنه يتعلم أيضًا ضمنيًا عن العلاقات في الكون.
علاوة على ذلك، قد يكون التنبؤ أساسًا أساسيًا للذكاء البيولوجي وكذلك الذكاء الاصطناعي. وفقا لفلاسفة مثل آندي كلارك، يمكن اعتبار الدماغ البشري بمثابة “آلة التنبؤ” التي تتمثل مهمتها الرئيسية في فهم البيئة المحيطة والتنبؤ بها ويمكن استخدامها للتنقل في العالم بنجاح.
بديهيًا، تتطلب التنبؤات الجيدة معاينات وأمثلة جيدة. سوف تجد طريقك بشكل أفضل باستخدام خريطة دقيقة بدلاً من خريطة غير دقيقة. يساعد الترقب الكائنات الحية على التوجيه والتكيف بشكل أكثر فعالية مع التعقيدات المقبلة.
كان أحد التحديات التقليدية لبناء نماذج لغوية كبيرة هو إيجاد أفضل طريقة لتمثيل وتمثيل كلمات مختلفة، خاصة عندما تعتمد معاني العديد من الكلمات بشكل كبير على السياق. يساعد أسلوب التنبؤ بالكلمة التالية الباحثين على تحويل هذا اللغز النظري الصعب إلى مشكلة تجريبية.
نحن نعلم الآن أن نماذج اللغات التي تحتوي على كميات كبيرة من البيانات وقدرة حاسوبية كافية تفهم كيفية التنبؤ بشكل أفضل بالكلمة التالية الصحيحة، وفي هذه العملية تتعلم الكثير عن كيفية عمل اللغة البشرية.
