
ما هو Qwen 3؟ دليل شامل لنموذج الذكاء الاصطناعي الجديد من Alibaba (لعام 2026)

شهدت شركة Alibaba Cloud تقدما كبيرا في مجال الذكاء الاصطناعي مع إطلاق النموذج الجديد Qwen 3، الذي يمثل جيلا متطورا من نماذج اللغة الكبيرة. تم تصميم هذا النموذج لدعم تقنيات الاستدلال الهجين الحديثة، ومن المتوقع إطلاقه رسميا في أبريل 2025. ويهدف كوين 3 إلى تقديم أداء مرن وقابل للتكيف في مختلف القطاعات، من خلال الجمع بين قدرات الفهم العميق وسرعة الاستجابة العالية.
يتميز Qwen3 عن النماذج السابقة بأنه لا يركز فقط على الحجم أو الأداء، بل يدعم أوضاع استدلال متعددة، ويتيح نافذة سياق ضخمة تصل إلى 128 ألف رمز (Token). كما يمكن نشره بمرونة من بيئات السحابة إلى الحافة (Cloud to Edge). ويعد Qwen 3 من النماذج الواعدة في سباق الذكاء الاصطناعي العالمي، خاصة بعد طرحه كمصدر مفتوح بموجب ترخيص Apache 2.0، واعتماده السريع من قبل الباحثين والشركات.
في هذا المقال، نستعرض أبرز ميزات Qwen 3 التي تجعله منافسا قويا لنماذج شهيرة مثل GPT-3 وGPT-4 Small وGrok 3، إلى جانب تحليل معماريته المتقدمة التي تعيد تعريف مفاهيم الكفاءة والأداء.
جدول المحتويات
ما هو Qwen 3؟
Qwen 3 هو أحدث إصدار من سلسلة النماذج اللغوية الكبيرة (LLMs) التي طورتها فريق Qwen التابع لـ Alibaba Cloud، وتم إطلاقه رسميًا في نهاية أبريل 2025. يُعد Qwen 3 نموذجًا قويًا ومتعدد الاستخدامات، حيث يشمل مجموعة واسعة من النماذج تبدأ من 0.6 مليار وتصل حتى 235 مليار معامل، بما في ذلك إصدارات Dense وإصدارات Mixture-of-Experts (MoE)، مثل النموذج Qwen3-235B-A22B الذي يحتوي على 22 مليار معامل نشط.
النموذج مرخص بموجب ترخيص Apache 2.0 ومتاح مجانيًا بالكامل، ورغم ذلك يتفوق على العديد من النماذج المدفوعة في اختبارات الأداء المعيارية.
وفقًا للموقع الرسمي qwen3.org، ينافس Qwen 3 أبرز النماذج العالمية مثل DeepSeek-R1، وOpenAI o1 وo3-mini، وGrok-3، وGemini-2.5-Pro في مجالات الترميز والرياضيات والمهام العامة. أما النموذج الأصغر Qwen3-30B-A3B، فقد تفوق حتى على نموذج QwQ-32B، رغم أنه يحتوي على عدد معاملات نشطة أقل بعشر مرات – وهذا يُعد إنجازًا مذهلًا.
مقالة ذات صلة: كل ما تود معرفته عن Qwen AI وكيفية إستخدامه: منافس قوي لـ ChatGPT
ميزات مبتكرة في Qwen 3
من أبرز الميزات التي تميز Qwen 3 هي دعمه لبروتوكول MCP (Model-Context-Protocol)، الذي يتيح له التفاعل المباشر مع أدوات خارجية مثل قواعد بيانات SQLite، والذاكرة، وأنظمة الملفات. يسمح MCP للنموذج بالاتصال بأدوات خوادم خارجية، مما يمكنه من تنفيذ مهام وكيلة (Agentic Workflows)، مثل جلب البيانات، تنفيذ الأوامر، وأكثر من ذلك. وقد لاقت هذه الميزة اهتماما واسعا على منصة X (تويتر سابقا)، حيث أشاد المستخدمون بقدرات النموذج المتقدمة في تنفيذ الوظائف واستدعاء الأدوات.
التحكم في ميزانية التفكير
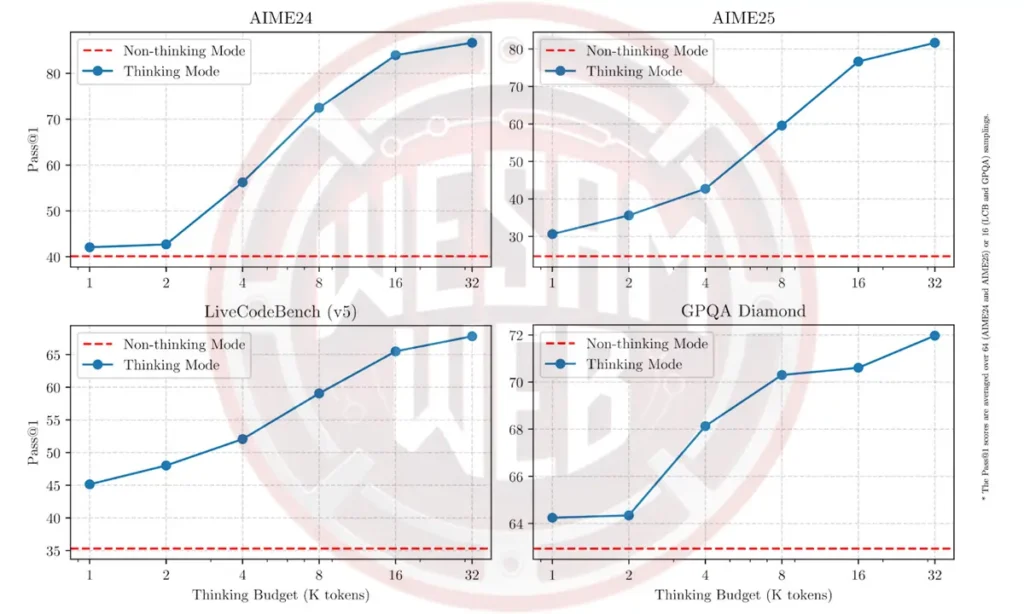
أحد الابتكارات اللافتة هو إدخال ميزة “ميزانية التفكير” (Thinking Budget)، التي يمكن للمستخدمين التحكم بها مباشرة من خلال تطبيق Qwen. هذه الميزة تمنح المستخدم العادي القدرة على ضبط مقدار الموارد المخصصة لعملية الاستدلال، وهي قدرة كانت تقتصر سابقا على المطورين من خلال البرمجة فقط.
وتظهر الرسوم البيانية أن زيادة ميزانية التفكير تؤدي إلى تحسين كبير في الأداء، خاصة في المهام المتعلقة بالرياضيات والبرمجة والعلوم.
أداء Qwen 3 في اختبارات المعايير
في اختبارات الأداء المعيارية، أثبت النموذج الرئيسي Qwen3-235B-A22B تفوقه على نماذج قوية مثل DeepSeek-R1 في مجالات البرمجة، الرياضيات، والتفكير المنطقي العام. ويوضح هذا مدى تقدم Qwen 3 مقارنة بأحدث نماذج الذكاء الاصطناعي المتوفرة حاليا. لنستكشف كل نموذج بسرعة ونفهم وظيفته.
Qwen 3-235B-A22B
يعد Qwen3-235B-A22B أكبر نموذج في سلسلة Qwen 3. يعتمد على بنية خليط الخبراء (Mixture of Experts – MoE)، ويحتوي على 235 مليار معامل إجمالي، منها 22 مليار معامل نشط في كل خطوة توليد.
في نموذج MoE، يتم تفعيل جزء صغير فقط من المعاملات في كل خطوة، مما يجعله أسرع وأقل تكلفة في التنفيذ مقارنة بالنماذج الكثيفة (Dense Models) مثل GPT-4o، والتي تستخدم جميع المعاملات بشكل دائم في كل خطوة.
يؤدي هذا النموذج أداءً متميزًا في المهام الرياضية، والاستدلال المنطقي، والبرمجة، وقد تفوق في اختبارات المقارنة على نماذج قوية مثل DeepSeek-R1.
Qwen 3-30B-A3B
نموذج Qwen3-30B-A3B هو إصدار MoE أصغر، يحتوي على 30 مليار معامل إجمالي، ولكن فقط 3 مليارات معامل نشطة في كل خطوة. ورغم هذا العدد المنخفض من المعاملات النشطة، فإنه يقدم أداءً مقاربًا لنماذج أكثر كثافة مثل QwQ-32B.
يعد خيارًا عمليًا للمستخدمين الذين يبحثون عن توازن بين القدرة على الاستدلال وتقليل تكلفة الاستدلال. وتمامًا مثل النموذج 235B، يدعم هذا النموذج نافذة سياق ضخمة تصل إلى 128 ألف رمز (Token)، ويتوفر أيضًا بترخيص Apache 2.0.
النماذج الكثيفة: 32B، 14B، 8B، 4B، 1.7B، 0.6B
تشمل سلسلة Qwen3 أيضًا ستة نماذج كثيفة تعتمد على بنية تقليدية، حيث يتم تفعيل جميع المعاملات في كل خطوة دون استثناء. وتغطي هذه النماذج مجموعة واسعة من حالات الاستخدام:
- Qwen3-32B، 14B، 8B تدعم نافذة سياق تصل إلى 128 ألف رمز.
- Qwen3-4B، 1.7B، 0.6B تدعم نافذة سياق تصل إلى 32 ألف رمز.
- جميع هذه النماذج متاحة كمصدر مفتوح، وموزعة بموجب ترخيص Apache 2.0.
تعد النماذج الصغيرة في هذه المجموعة مناسبة للاستخدامات الخفيفة، بينما النماذج الأكبر مثل Qwen3-32B تقارب أداء النماذج اللغوية الشاملة.
أي نموذج يجب عليك اختياره؟
يقدم Qwen3 نماذج مختلفة اعتمادًا على عمق التفكير والسرعة والتكلفة الحسابية التي تحتاجها. فيما يلي ملخص سريع:
| النموذج | النوع | طول السياق | أفضل استخدام |
|---|---|---|---|
| Qwen3-235B-A22B | خليط خبراء (MoE) | 128K | مهام البحث، سير عمل الوكلاء، سلاسل استدلال طويلة |
| Qwen3-30B-A3B | خليط خبراء (MoE) | 128K | استدلال متوازن مع تكلفة استدلال منخفضة |
| Qwen3-32B | كثيف | 128K | عمليات نشر عامة عالية المستوى |
| Qwen3-14B | كثيف | 128K | تطبيقات متوسطة المستوى تحتاج إلى استدلال قوي |
| Qwen3-8B | كثيف | 128K | مهام استدلال خفيفة |
| Qwen3-4B | كثيف | 32K | تطبيقات صغيرة، استدلال أسرع |
| Qwen3-1.7B | كثيف | 32K | حالات استخدام محمولة ومضمنة |
| Qwen3-0.6B | كثيف | 32K | سيناريوهات خفيفة أو مقيدة للغاية |
إذا كنت تعمل على مهام تتطلب تفكيرًا أعمق، أو استخدام أدوات الوكيل، أو التعامل مع سياقات طويلة، فإن Qwen3-235B-A22B سيوفر لك أقصى قدر من المرونة.
في الحالات التي ترغب فيها في الحفاظ على استدلال أسرع وأقل تكلفة مع الاستمرار في التعامل مع مهام متوسطة التعقيد، يُعد Qwen3-30B-A3B خيارًا ممتازًا.
توفر النماذج الكثيفة عمليات نشر أبسط وزمن وصول متوقع، مما يجعلها أكثر ملاءمة للتطبيقات ذات النطاق الأصغر.
كيف تم تطوير Qwen3
تم بناء نماذج Qwen3 من خلال مرحلة ما قبل التدريب المكونة من ثلاث مراحل، تلتها عملية ما بعد التدريب المكونة من أربع مراحل.
مرحلة ما قبل التدريب (Pretraining) هي المرحلة التي يتعلم فيها النموذج أنماطًا عامة من كميات ضخمة من البيانات (مثل اللغة، والمنطق، والرياضيات، والبرمجة) دون أن يطلب منه أداء مهام معينة بشكل مباشر. أما مرحلة ما بعد التدريب (Posttraining)، فهي المرحلة التي يتم فيها تحسين أداء النموذج ليصبح قادرًا على تنفيذ مهام محددة مثل التفكير المتسلسل أو اتباع التعليمات بدقة.
سأقوم بشرح كلا المرحلتين بلغة مبسطة دون الدخول في تفاصيل تقنية عميقة.
المرحلة الأولى: ما قبل التدريب
مقارنة بإصدار Qwen2.5، تم توسيع مجموعة بيانات التدريب بشكل كبير في Qwen3. حيث تم استخدام حوالي 36 تريليون وحدة (tokens)، أي ضعف ما تم استخدامه في الإصدار السابق. وشملت البيانات المحتوى من الإنترنت، ونصوصًا مأخوذة من وثائق، وأمثلة رياضية ومعلومات برمجية تم توليدها باستخدام نماذج Qwen2.5 السابقة.
تضمن ما قبل التدريب ثلاث مراحل رئيسية:
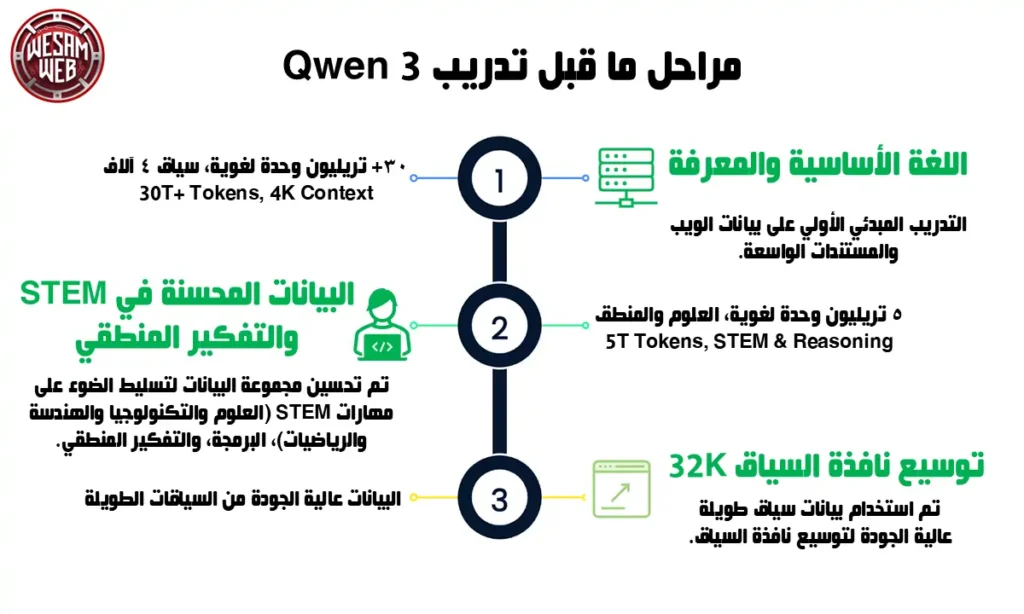
- المرحلة الأولى: تم تدريب النموذج على المهارات اللغوية والمعرفة العامة باستخدام أكثر من 30 تريليون وحدة، بطول سياقي يبلغ 4 آلاف رمز.
- المرحلة الثانية: تم تحسين نوعية البيانات، بحيث تم رفع نسبة بيانات المجالات العلمية (STEM) والبرمجة والتفكير المنطقي، مع إضافة 5 تريليون وحدة إضافية.
- المرحلة الثالثة: تم إدخال بيانات عالية الجودة بطول سياقي طويل، مما سمح للنموذج بالتعامل مع سياقات يصل طولها إلى 32 ألف رمز.
والنتيجة هي أن نماذج Qwen3 الأساسية والكثيفة أصبحت تساوي أو حتى تتفوق على نماذج Qwen2.5 الأكبر حجمًا، مع استخدام عدد أقل من المعاملات (parameters)، خصوصًا في المهام المتعلقة بالعلوم والبرمجة والتفكير المنطقي.
المرحلة الثانية: ما بعد التدريب
تركزت عملية ما بعد التدريب في Qwen3 على دمج التفكير العميق والقدرة على الاستجابة السريعة في نموذج واحد. دعونا نتناول هذه العملية خطوة بخطوة بطريقة مبسطة:
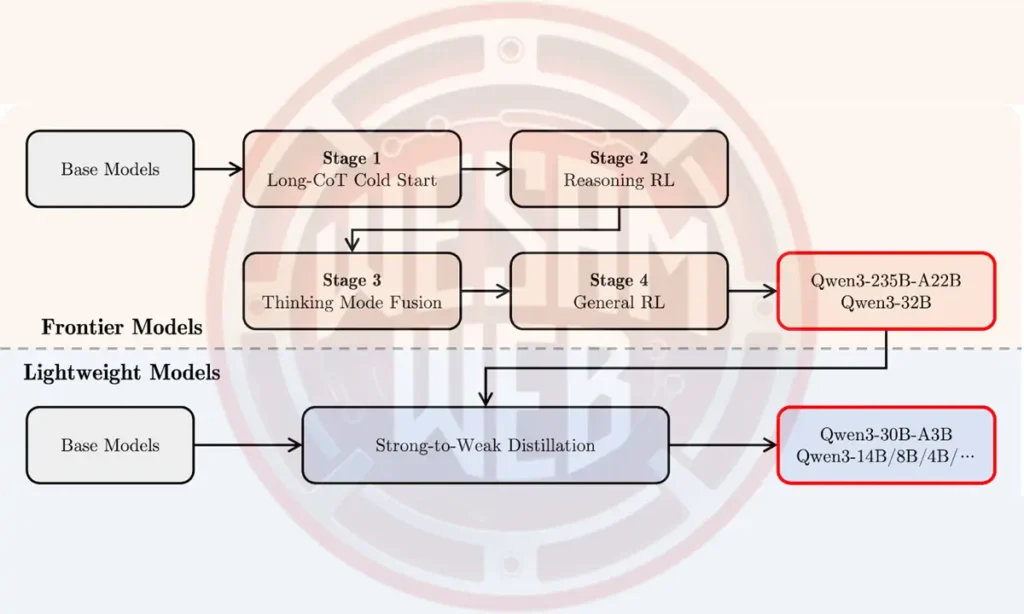
في الجزء العلوي من مراحل التطوير، هناك ما يعرف بمسار النماذج المتقدمة مثل Qwen3-235B-A22B وQwen3-32B، وتشمل مراحل ما بعد التدريب الآتية:
- المرحلة الأولى: استخدام ما يسمى بـ “سلسلة تفكير طويلة” (Long Chain of Thought) كنقطة انطلاق، وهي تهدف إلى تدريب النموذج على التفكير خطوة بخطوة في المسائل المعقدة.
- المرحلة الثانية: تم تطبيق تقنيات التعلم المعزز عبر التفكير المنطقي (Reinforcement Learning for Reasoning) لتحسين استراتيجيات حل المشكلات.
- المرحلة الثالثة: تعرف باسم دمج أنماط التفكير، وهي المرحلة التي يتعلم فيها النموذج موازنة التفكير البطيء والدقيق مع الإجابات السريعة حسب نوع المهمة.
- المرحلة الرابعة: تطبيق تقنيات التعلم المعزز العام (General RL) لتحسين أداء النموذج في مجموعة واسعة من المهام مثل اتباع التعليمات بدقة والتعامل مع الحالات التفاعلية.
أما في الجزء السفلي، فيتم تطوير النماذج الخفيفة مثل Qwen3-30B-A3B والنماذج الكثيفة الأصغر حجمًا من خلال أسلوب يُعرف بـ التقطير المعرفي (Knowledge Distillation)، وهو عملية يتم فيها استخلاص المعرفة من النماذج الكبيرة وضغطها في نماذج أصغر وأسرع، دون فقدان الكثير من قدرات التفكير أو الفهم.
بكلمات أبسط: تم تدريب النماذج الكبيرة أولًا، ثم تم اشتقاق النماذج الأصغر منها. بهذه الطريقة، تحتفظ جميع نماذج Qwen3 بنفس نمط التفكير والمنطق، حتى وإن اختلفت في الحجم.
المعايير المرجعية لأداء Qwen 3
تم تقييم نماذج Qwen3 باستخدام مجموعة من الاختبارات في مجالات الاستدلال المنطقي، البرمجة، والمعرفة العامة. أظهرت النتائج أن النموذج الأكبر Qwen3-235B-A22B يتصدر معظم المهام، لكن النماذج الأصغر مثل Qwen3-30B-A3B وQwen3-4B أظهرت أداءً جيدًا أيضًا بالنسبة لحجمها.
Qwen3-235B-A22B و Qwen3-32B
في أغلب اختبارات المقارنة، يعتبر Qwen3-235B-A22B من بين النماذج الأفضل أداءً، وإن لم يكن دائمًا في الصدارة. فيما يلي نظرة سريعة على نتائجه:
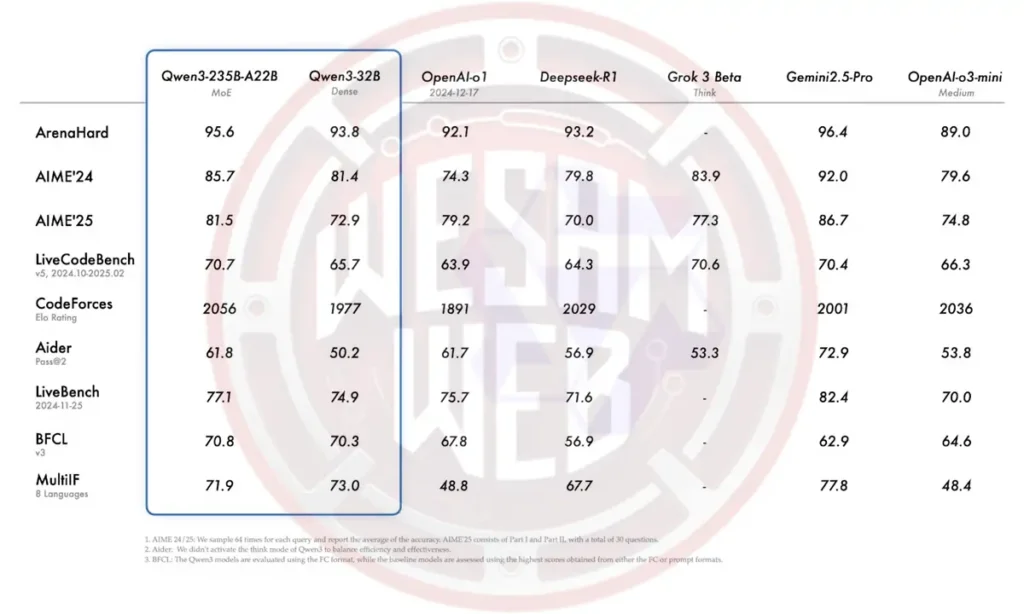
- ArenaHard (الاستدلال العام): جاء Gemini 2.5 Pro في المركز الأول بنتيجة 96.4، يليه Qwen3-235B بنتيجة 95.6، متفوقًا على o1 وDeepSeek-R1.
- AIME’24 / AIME’25 (الرياضيات): سجل النموذج 85.7 و81.4. وعلى الرغم من أن Gemini 2.5 Pro لا يزال أعلى، فإن Qwen3-235B تفوق على نماذج مثل DeepSeek-R1 وGrok 3 وo3-mini.
- LiveCodeBench (توليد الكود): سجل 70.7، وهو أفضل من معظم النماذج باستثناء Gemini.
- CodeForces Elo (البرمجة التنافسية): حقق نتيجة 2056، متفوقًا على جميع النماذج الأخرى المدرجة، بما في ذلك DeepSeek-R1 وGemini 2.5 Pro.
- LiveBench (مهام واقعية متنوعة): سجل 77.1، وجاء في المركز الثاني بعد Gemini 2.5 Pro.
- MultiIF (الاستدلال متعدد اللغات): سجل Qwen3-32B نتيجة 73.0، وهو أداء جيد لكنه لا يزال أقل من Gemini الذي حصل على 77.8.
Qwen3-30B-A3B و Qwen 3-4B
يعد Qwen3-30B-A3B (وهو أصغر نموذج من نوع MoE) من أفضل النماذج في معظم الاختبارات، وقد تفوق أو تساوى مع نماذج كثيفة من نفس الفئة الحجمية:
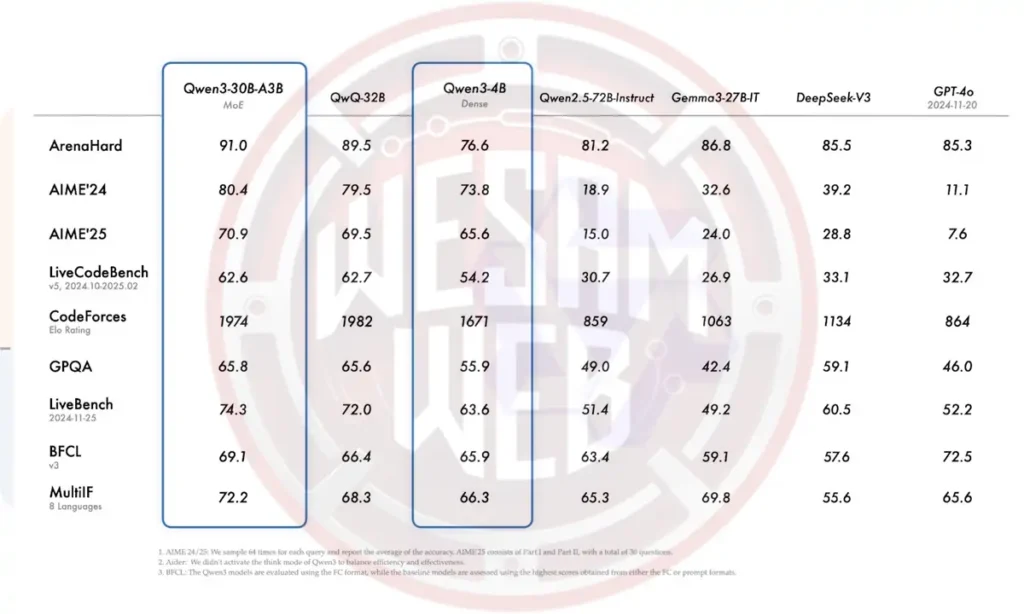
- ArenaHard: سجل 91.0، متفوقًا على QwQ-32B (89.5)، وDeepSeek-V3 (85.5)، وGPT-4o (85.3).
- AIME’24 / AIME’25: حصل على 80.4، متفوقًا قليلاً على QwQ-32B وبفارق كبير عن بقية النماذج.
- CodeForces Elo: سجل 1974، أي أقل قليلاً من QwQ-32B (1982).
- GPQA (ضمان الجودة على مستوى الدراسات العليا): سجل 65.8، متقاربًا مع QwQ-32B.
- MultiIF: سجل 72.2، وهو أعلى من QwQ-32B (68.3).
أما Qwen3-4B، فقد أظهر أداءً قويًا بالنسبة لحجمه الصغير:
- ArenaHard: سجل 76.6.
- AIME’24 / AIME’25: سجل 73.8 و65.6، وهي نتائج تفوق بكثير تلك التي سجلتها نماذج Qwen2.5 الأكبر حجمًا، وأفضل من نماذج مثل Gemma-27B-IT.
- CodeForces Elo: حصل على 1671، وهو رقم لا يُنافس النماذج الأكبر، لكنه جيد بالنسبة لفئته.
- MultiIF: سجل 66.3، وهو أداء محترم جدًا بالنسبة لنموذج كثيف بحجم 4B، وأعلى بكثير من العديد من النماذج المرجعية من نفس الفئة.
كيفية الوصول إلى Qwen 3
نماذج Qwen3 متاحة للجمهور ويمكن استخدامها عبر تطبيق الدردشة، من خلال واجهة API، أو تنزيلها لتشغيلها محليًا أو دمجها في إعدادات مخصصة.
واجهة الدردشة
يمكنك تجربة Qwen3 مباشرة عبر chat.qwen.ai.
سيكون لديك الوصول فقط إلى ثلاثة نماذج من عائلة Qwen3 في تطبيق الدردشة:
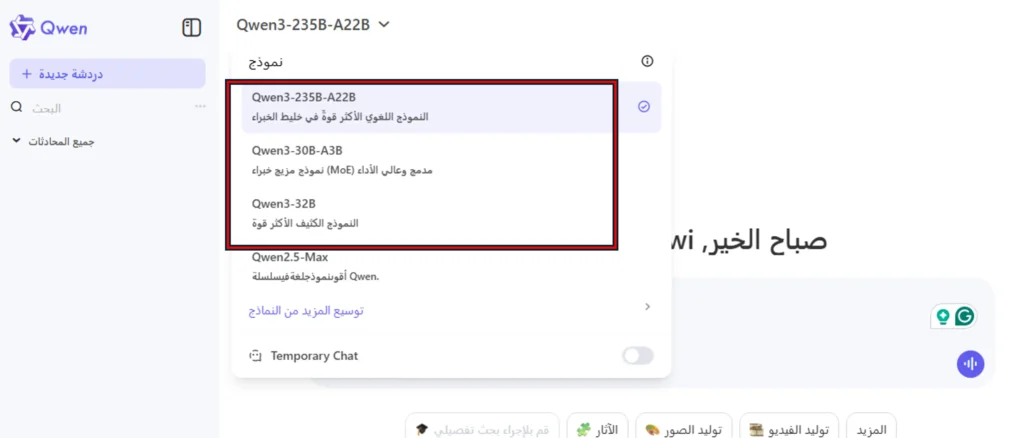
- Qwen3-235B
- Qwen3-30B
- Qwen3-32B
الوصول إلى واجهة API لـ Qwen 3
يعمل Qwen3 مع تنسيقات API المتوافقة مع OpenAI من خلال مزودين مثل ModelScope أو DashScope. توفر أدوات مثل vLLM و SGLang خدمة فعالة للتنفيذ المحلي أو الاستضافة الذاتية. يحتوي المدونة الرسمية لـ Qwen 3 على مزيد من التفاصيل حول هذا الموضوع.
نماذج مفتوحة المصدر
جميع نماذج Qwen3 – سواء كانت MoE أو كثيفة – تم نشرها بموجب رخصة Apache 2.0. وهي متاحة على:
- Hugging Face
- ModelScope
- Kaggle
التنفيذ المحلي
يمكنك أيضًا تشغيل Qwen3 محليًا باستخدام الأدوات التالية:
- Ollama
- LM Studio
- llama.cpp
- KTransformers
الخلاصة
يعد Qwen3 واحدًا من أكثر مجموعات النماذج ذات الوزن المفتوح تكاملاً التي تم نشرها حتى الآن.
- النموذج الرائد 235B MoE يؤدي بشكل جيد في مهام الاستدلال المنطقي، الرياضيات، والبرمجة.
- النسخ 30B و 4B توفر بدائل عملية للنشر على نطاق أصغر أو مع ميزانية محدودة.
- إضافة إمكانية تعديل ميزانية التفكير للنموذج توفر طبقة إضافية من المرونة للمستخدمين العاديين.
في حالته الحالية، يعد Qwen3 إصدارًا متكاملًا يغطي مجموعة واسعة من حالات الاستخدام وجاهز للاستخدام سواء في بيئات البحث أو الإنتاج.
