
البيانات الضخمة: تعرف على الابتكار والتطور المستمر في مجال Big Data

في عصر التحول الرقمي المتسارع، تشكل البيانات الضخمة العمود الفقري لاتخاذ القرارات الذكية. لم تعد المعلومات مجرد أرقام مخزنة داخل خوادم تقليدية، بل أصبحت القوة التي تقود الاقتصاد الرقمي الحديث. فاليوم تعتمد الشركات والمؤسسات على تحليل مليارات البيانات لفهم سلوك المستخدمين، والتنبؤ بالاتجاهات المستقبلية، واتخاذ قرارات أكثر دقة وذكاء، مما جعل البيانات توصف بأنها الوقود الحقيقي للعالم الرقمي.
ومع التطور المتسارع في الذكاء الاصطناعي، والحوسبة السحابية، وإنترنت الأشياء (IoT)، أصبحت البيانات الضخمة حجر الأساس لمعظم التقنيات الحديثة. فكل عملية بحث على الإنترنت، وكل عملية شراء إلكترونية، وحتى الأجهزة الذكية المتصلة بالشبكة، تساهم يوميا في إنتاج كميات هائلة من البيانات التي تحتاج إلى تقنيات متقدمة لتخزينها ومعالجتها وتحليلها بكفاءة عالية.
وتكمن أهمية البيانات الضخمة Big Data في قدرتها على تحويل الكم الهائل من المعلومات إلى رؤى استراتيجية تساعد الشركات، والمستشفيات، والحكومات، والمؤسسات التعليمية على تحسين الأداء واتخاذ قرارات أكثر فعالية. لذلك، لم يعد هذا المجال مجرد مفهوم تقني معقد، بل أصبح عنصرا أساسيا في بناء الأنظمة الذكية وصناعة مستقبل التكنولوجيا الحديثة.
وفي هذا الدليل الشامل، سنستكشف رحلة البيانات منذ لحظة توليدها وحتى تحويلها إلى قرارات ذكية، كما سنتعرف على أبرز أنواع البيانات الضخمة، والبنية التقنية التي تعتمد عليها، وأهم أدوات تحليلها، واستخداماتها الواقعية في مختلف القطاعات، إضافة إلى التحديات الأمنية والأخلاقية التي ترافق هذا التطور المتسارع. والأهم من ذلك، سنفهم كيف أصبحت البيانات الضخمة حجر الأساس الذي ترتكز عليه الثورة الرقمية الحديثة، ولماذا تتسابق كبرى الشركات العالمية للاستثمار فيها بوصفها المورد الأكثر قيمة في القرن الحادي والعشرين.
جدول المحتويات
- ما هي البيانات الضخمة؟
- تاريخ البيانات الكبيرة
- كيف تعمل البيانات الضخمة؟
- الهدف الأساسي للبيانات الضخمة
- ما فائدة البيانات الضخمة؟
- كيف تستفيد الشركات فعلياً من البيج داتا؟
- كيفية يتم تحليل البيانات الكبيرة
- خطوات تحليل البيانات الضخمة
- أنواع البيانات الضخمة
- ما هي خصائص البيانات الضخمة الخمس الرئيسية؟
- ما هي الرؤية والموثوقية في البيانات الضخمة؟
- ما هي استخدامات البيانات الضخمة؟
- فوائد استخدام البيانات الضخمة في الأعمال التجارية
- أمثلة على استخدام البيانات الضخمة في الصناعات المختلفة
- الربط بين البيانات الضخمة والذكاء الاصطناعي وعلم البيانات
- الحوسبة السحابية والبيانات الضخمة
- تأثير البيانات الضخمة على التسويق الرقمي
- تأثير الـ Big data على التسويق الرقمي
- استنتاج
ما هي البيانات الضخمة؟

يشير مصطلح البيانات الضخمة (Big Data) إلى كميات هائلة ومتنوعة وسريعة التدفق من البيانات الرقمية، يتم إنتاجها يوميا من مصادر متعددة مثل شبكات التواصل الاجتماعي، وأجهزة الاستشعار، والأجهزة الذكية المتصلة بالإنترنت، والتطبيقات الرقمية، والمعاملات الإلكترونية. وتمتاز هذه البيانات بأنها معقدة للغاية، إلى درجة تجعل أدوات إدارة البيانات التقليدية غير قادرة على تخزينها أو معالجتها أو تحليلها بكفاءة.
ولا تقتصر أهمية البيانات الضخمة على حجمها فقط، بل تشمل أيضا سرعة توليدها وتنوع أشكالها، حيث قد تكون بيانات نصية، أو صورا، أو مقاطع فيديو، أو إشارات حساسات، أو سجلات طبية، أو بيانات مالية. ولهذا السبب تعتمد المؤسسات الحديثة على تقنيات متقدمة لتحليل هذه البيانات واستخراج معلومات دقيقة تساعد في تحسين الأداء واتخاذ القرارات الاستراتيجية.
ويمكن توليد كميات ضخمة من البيانات عبر تقنيات مثل إنترنت الأشياء (IoT)، والأجهزة الطبية الذكية، وأنظمة الاتصالات، والسيارات المتصلة، والكاميرات الذكية، ثم يتم تخزينها داخل قواعد بيانات ضخمة أو مستودعات بيانات مخصصة لمعالجة الأحجام الهائلة من المعلومات.
كما يساهم دمج تقنيات مثل الذكاء الاصطناعي (AI)، والتعلم الآلي (Machine Learning)، والشبكات العصبية (Neural Networks) في تحليل البيانات الضخمة واكتشاف الأنماط والعلاقات المخفية داخلها، مما يساعد الشركات والحكومات والمؤسسات الطبية على اتخاذ قرارات أكثر دقة وكفاءة.
مثال على البيانات الضخمة:
عندما يستخدم ملايين الأشخاص تطبيقات مثل خرائط جوجل أو منصات التواصل الاجتماعي في الوقت نفسه، يتم جمع كميات هائلة من البيانات المتعلقة بالموقع الجغرافي، وعمليات البحث، وسلوك المستخدم، والاهتمامات، وسرعة الحركة. تقوم الأنظمة الذكية بتحليل هذه البيانات لحظيا لتقديم اقتراحات دقيقة، مثل تحديد أسرع الطرق لتجنب الازدحام المروري، أو عرض محتوى وإعلانات تتناسب مع اهتمامات كل مستخدم.
تاريخ البيانات الكبيرة
هذا الجدول يلخص بشكل مبسط تطور تاريخ البيانات الضخمة، حيث بدأ الاهتمام بالمفهوم في أواخر القرن العشرين وتطور بشكل كبير مع تقدم التكنولوجيا وزيادة حجم البيانات الرقمية في العقد الأول والثاني من القرن الواحد والعشرين.
| الحقبة الزمنية | الحدث المحوري | التقنية أو المفهوم الرئيسي | الأثر على تطور البيانات الضخمة |
|---|---|---|---|
| 1940 - 1960 | عصر الحوسبة التأسيسية | الحواسيب التناظرية والرقمية الأولى | الانتقال من المعالجة اليدوية إلى التخزين الرقمي المركزي |
| 1965 | إنشاء أول أنظمة إدارة البيانات | قواعد البيانات الهرمية والشبكية | ظهور هيكلية منظمة لحفظ السجلات المؤسسية |
| 1970 | ثورة النماذج العلائقية | لغة SQL وقواعد البيانات العلائقية | توحيد معايير الاستعلام وتمكين التحليل الهيكلي |
| 1980 - 1990 | عصر مخازن البيانات | Data Warehousing و ETL | دمج المصادر المتفرقة لدعم الذكاء التجاري التاريخي |
| 2005 | صياغة المفهوم رسمياً | أطر Hadoop و MapReduce | تمكين المعالجة الموزعة على عناقيد خوادم منخفضة التكلفة |
| 2008- 2010 | انفجار المحتوى الرقمي | منصات التواصل والهواتف الذكية | ظهور تدفقات غير مهيكلة ومتنوعة الوسائط |
| 2012 - 2015 | عصر التحليلات السريعة | Apache Spark والحوسبة السحابية | تقليل زمن المعالجة إلى ثوانٍ وتمكين النماذج التنبؤية |
| 2016 - 2020 | إنترنت الأشياء والحدودية | أجهزة الاستشعار المتصلة و Edge Computing | معالجة التدفقات الحية بالقرب من المصدر وتقليل الاعتماد على السحابة |
| 2021 - 2026 | الذكاء التوليدي والنماذج الضخمة | نماذج اللغات الكبيرة و MLOps | تكامل الوسائط المتعددة وأتمتة استخلاص الرؤى المعقدة |
كيف تعمل البيانات الضخمة؟
تعتمد البيانات الضخمة Big Data على مجموعة متقدمة من التقنيات التي تهدف إلى جمع كميات هائلة من البيانات، ثم تخزينها ومعالجتها وتحليلها لاستخراج معلومات دقيقة تساعد المؤسسات على اتخاذ قرارات أكثر ذكاء. وتبدأ هذه العملية من مصادر متعددة مثل مواقع التواصل الاجتماعي، والأجهزة الذكية، وأنظمة الدفع الإلكتروني، ومحركات البحث، وأجهزة الاستشعار المتصلة بـ إنترنت الأشياء (IoT)، حيث يتم توليد ملايين البيانات كل ثانية.
وبعد جمع البيانات، تأتي مرحلة التخزين والمعالجة، وهي من أكثر المراحل تعقيدا بسبب الحجم الضخم والتدفق السريع للمعلومات. ولهذا لا يمكن الاعتماد على الطرق التقليدية أو المراجعة اليدوية، بل يتم استخدام أنظمة حوسبة متقدمة قادرة على التعامل مع البيانات بسرعة وكفاءة عالية. ومن أشهر هذه التقنيات منصة Apache Hadoop، وهي إطار عمل مفتوح المصدر يسمح بتوزيع البيانات على عدد كبير من أجهزة الكمبيوتر لمعالجتها بالتوازي، مما يسرع عمليات التحليل بشكل هائل.
وبعد ذلك، يتم تحليل البيانات عبر خوارزميات تعتمد على الذكاء الاصطناعي والتعلم الآلي لاكتشاف الأنماط والعلاقات المهمة، مما يساعد الشركات والمؤسسات على اتخاذ قرارات دقيقة، وتحسين الخدمات، والتنبؤ بالسلوك والاتجاهات المستقبلية بكفاءة أكبر.
وتستخدم كبرى الشركات العالمية مثل Google وYahoo أنظمة تحليل بيانات متطورة تعتمد على مبادئ مشابهة لمعالجة الكم الهائل من المعلومات الناتجة عن المستخدمين والخدمات الرقمية. كما أصبحت الحوسبة السحابية جزءا أساسيا من بنية البيانات الضخمة، لأنها توفر قدرة مرنة على التخزين والمعالجة دون الحاجة إلى بنية تحتية محلية مكلفة.
الهدف الأساسي للبيانات الضخمة
الهدف الأساسي للبيانات الضخمة ليس مجرد جمع المعلومات، بل تحليلها وفحصها بعمق لاستخراج الكنوز المخفية داخلها. ببساطة، بعد جمع البيانات من قواعد البيانات ومصادرها المختلفة، يبدأ التحدي الحقيقي. فكما تعلم، الحجم الهائل والسرعة الفائقة يجعلان من المستحيل على أي إنسان أن يتحقق من هذه المعلومات يدوياً. ونتيجة لذلك، أصبح الاعتماد على أنظمة الكمبيوتر والأدوات المتخصصة ضرورة لا غنى عنها.
لماذا لا نستطيع استخدام البرامج العادية؟
لأن الكميات التي نتعامل معها تقاس الآن بـ البيتابايت وليس الغيغابايت، وهذا يتطلب أدوات ثورية وليست تقليدية. هنا يأتي دور مجموعة أدوات Apache Hadoop، التي تعتبر بحق أشهر هذه البرامج على الإطلاق.
ما سر قوة Hadoop؟
في الواقع، Hadoop ليس برنامجاً واحداً بل منصة متكاملة تضم مجموعة من الأدوات التي تعمل بتناغم تام. الفكرة العبقرية تكمن في توزيع عبء العمل: بدلاً من كمبيوتر عملاق واحد (وهو حل خيالي التكلفة)، يقوم Hadoop بتوزيع المهمة على مئات أو آلاف الأجهزة العادية التي تعمل معاً كجهاز واحد خارق.
آلية العمل الأهم داخل Hadoop تعتمد على نموذج برمجي ذكي اسمه MapReduce، والذي يعمل على مرحلتين: الأولى (Map) لتقسيم البيانات وتوزيعها، والثانية (Reduce) لجمع النتائج وتجميعها. وبفضل هذه الآلية، وبمساعدة الخوارزميات والمعادلات الحساسة، يصبح تحليل بيانات بحجم بيتابايت مهمة ممكنة وسريعة.
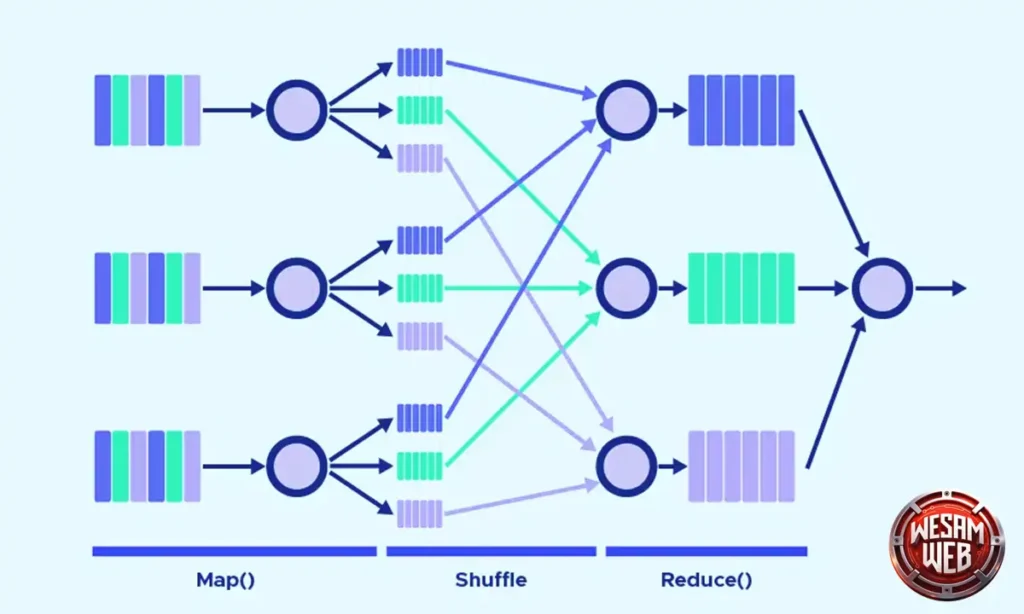
للمعلومية، كبرى شركات الإنترنت مثل Yahoo تستخدم هذه التقنية وتدعمها، بينما تمتلك Google نظاماً مشابهاً لكن حصرياً لاستخداماتها التجارية فقط.
البيانات الضخمة ليست للجميع… بسهولة
بشكل عام، ينطوي هذا المجال على تعقيدات كبيرة تجعل من الصعب على المؤسسات الصغيرة والمتوسطة خوضه بمفردها دون مساعدة خارجية. ونتيجة لذلك، ظهرت شركات متخصصة تقدم “البيانات الضخمة كخدمة” لتوفير البنية والخبرات المطلوبة.
ماذا عن العالم العربي؟
على الرغم أن الموضوع لا يزال أقل انتشاراً مما يجب، إلا أن السعودية والإمارات تشهدان ظهور مواقع وشركات رائدة في هذا المجال. من أبرز الأمثلة، شركة “بريسايت” (Presight) التي دخلت بقوة لتقديم خدمات البيانات الضخمة للشركات الإماراتية.
خلاصة العوامل الثلاثة
للإفادة الحقيقية من البيانات الضخمة، يجب توفر ثلاثة عوامل رئيسية: أولاً، سعة تخزين هائلة لاستيعاب الكميات المتدفقة، ثانياً، أدوات تحليل متطورة (مثل Hadoop والذكاء الاصطناعي)، وثالثاً آلية حكيمة لتطبيق النتائج على أرض الواقع. والأهم، أن مرحلة التطبيق تتطلب تكتيكات فريدة، لأن البيانات الضخمة أداة قوية تعكس بقدر ما تحسن طريقة استخدامها.
ما فائدة البيانات الضخمة؟
الحقيقة المذهلة أنك تستخدم فوائد البيانات الضخمة يومياً دون أن تشعر. ففي كل مرة تزور فيها موقعاً إلكترونياً، أو تبحث عن منتج معين، أو حتى تتجول في الشارع، فإنك تترك خلفك بصمة رقمية تتحول لاحقاً إلى قرارات ذكية وقيم مضافة تخدمك أنت أولاً. على سبيل المثال، عندما تتصفح متجراً إلكترونياً وترى منتجات “موصى بها” تناسب ذوقك تماماً، فهذه ليست صدفة بل نتيجة مباشرة لتحليل البيانات الضخمة لسلوكك السابق.
ولكن هل تقتصر الفائدة على عالم الإنترنت فقط؟ بالطبع لا. فحتى عندما نسير في الشارع، فإن أجهزة تحديد المواقع الجغرافية في هواتفنا، وشبكات WiFi المحيطة، وكاميرات المراقبة المنتشرة، تقوم جميعها بجمع بيانات ضخمة عن حركتنا وسلوكنا. وهنا يأتي السؤال الجوهري: هل نشعر بالخطر من هذا التجسس الرقمي؟ في الواقع، الفكرة القديمة بأننا “معرضون للخطر فقط” عندما نملأ نموذجاً أو نسجل بياناتنا الشخصية لم تعد صحيحة تماماً، لأن البيانات تُجمع عنا حتى دون أن نقدمها طواعية. ولكن، الجانب المشرق أن هذه العملية يستفيد منها غالبية المستخدمين، وتستخدمها الشركات الذكية للحصول على فرص عمل جديدة وتحسين تجاربنا اليومية.
كيف تستفيد الشركات فعلياً من البيج داتا؟
باختصار، أصبحت البيانات الضخمة قناة أعمال حيوية لا غنى عنها لأي مؤسسة تبحث عن البقاء والريادة. فالسبب الرئيسي أن الشركات في جميع المجالات (الطب، اللياقة البدنية، الرياضة، التجارة الإلكترونية، وحتى الحكومات) تلجأ إليها هو أنها تسمح لها بفهم عملائها بشكل أعمق مما كان ممكناً في أي وقت مضى. بمعنى أدق، يمكن للشركة الآن أن تعرف ليس فقط “ماذا اشترى العميل؟” بل “لماذا اشترى؟ وكيف يريد أن يتفاعل مع المنتج؟ ومتى سيكون مستعداً لشراء المزيد؟”
من أروع الأمثلة العملية، ما يحدث في قطاعي الطب والرياضة. تخيل معي مستشفى يمتلك مجموعة ضخمة ومتنوعة من بيانات المرضى (التشخيصات السابقة، الاستجابات للعلاج، العوامل الوراثية، نمط الحياة). عندما تُحلل هذه البيانات الضخمة باستخدام تقنيات الذكاء الاصطناعي، تصبح النتيجة قدرة حقيقية على تحسين نوعية الحياة من خلال الوقاية من الأمراض قبل ظهورها، ومكافحتها بخطط علاجية مخصصة لكل مريض على حدة. ونتيجة لذلك، تستطيع شركات التأمين الصحي ومراكز اللياقة البدنية تقديم خدمات دقيقة تعكس احتياجات كل فرد، مما يزيد من عائد الاستثمار لحملاتها ويحسن في نفس الوقت من جودة حياة المستفيدين.
كيفية يتم تحليل البيانات الكبيرة

قبل البدء، من الضروري أن ندرك أن تحليل البيانات الضخمة يختلف تماماً عن تحليل البيانات التقليدية. فالأدوات المعتادة مثل Excel تصبح عاجزة تماماً عندما نواجه ملايين أو مليارات السجلات. لذلك، تعتمد عملية التحليل على منهجية متكاملة وخطوات منظمة يمكن تلخيصها في النقاط التالية:
خطوات تحليل البيانات الضخمة
تحليل البيانات الضخمة ليس سحراً، بل هو عملية منظمة تمر بسبع خطوات متتالية. فهم هذه الخطوات يمنحك خريطة طريق واضحة لأي مشروع تحليل بيانات، بغض النظر عن حجمه أو تعقيده.
أولاً: جمع البيانات
تأتي البيانات من كل مكان: مواقع التواصل، أجهزة الاستشعار، كاميرات المراقبة، الأجهزة الطبية، وحتى ساعتك الذكية. في هذه المرحلة، يتم استيراد كل هذه البيانات إلى نظام تخزين مركزي أو موزع.
ثانياً: تنظيف البيانات
البيانات الخام تشبه الذهب المخلوط بالتراب، فلا بد من تنقيتها. هنا، يتم إزالة التكرارات، وتصحيح الأخطاء، ومعالجة القيم المفقودة. تذكر: بيانات قذرة تعني نتائج قذرة.
ثالثاً: تخزين موزع
بدلاً من قرص صلب واحد (وهو مستحيل عملياً)، تستخدم أنظمة تخزين موزعة مثل HDFS. ببساطة، يتم تقسيم الملف الضخم إلى أجزاء صغيرة وتوزيعها على آلاف الخوادم.
رابعاً: اختيار نموذج المعالجة
- معالجة دفعية (Batch): للبيانات التاريخية المخزنة مسبقاً، مثل تقارير المبيعات السنوية
- معالجة تدفقية (Stream): للتحليل الفوري أثناء تدفق البيانات، مثل اكتشاف الاحتيال المصرفي
خامساً: تطبيق الخوارزميات
- للتجميع والتصنيف: خوارزميات K-means
- للتوقع: الانحدار والشبكات العصبية
- للأنماط الخفية: قواعد الارتباط
- للصور والكلام: التعلم العميق
سادساً: عرض النتائج
النتائج الخام لا تفيد صانع القرار، لذلك تحول إلى لوحات تحكم تفاعلية ورسوم بيانية باستخدام Tableau أو Power BI.
سابعاً: التطبيق وإعادة التقييم
التحليل ليس لمرة واحدة، بل دورة مستمرة من التطبيق والقياس والتغذية الراجعة والتحسين المستمر.
خلاصة سريعة بالخطوات
| الخطوة | المهمة الأساسية | مثال على الأداة |
|---|---|---|
| 1 | جمع البيانات | Apache NiFi، Kafka |
| 2 | تنظيف البيانات | Python (Pandas)، Spark SQL |
| 3 | تخزين موزع | HDFS، Amazon S3 |
| 4 | معالجة (دفعية أو تدفقية) | Hadoop MapReduce، Spark Streaming |
| 5 | تحليل بخوارزميات | Scikit-learn، TensorFlow |
| 6 | تصور النتائج | Tableau، Power BI |
| 7 | تطبيق وإعادة تقييم | أنظمة التشغيل الذكية |
ملاحظة مهمة: هذه الخطوات ليست دائماً متسلسلة بشكل صارم. في الواقع، قد تعود إلى الوراء عدة مرات (مثلاً تكتشف أثناء التحليل أن بياناتك لا تزال غير نظيفة بما يكفي). ولكن، فهم هذا الهيكل العام يمنحك خريطة طريق واضحة لأي مشروع تحليل بيانات ضخمة تخطط له.
أنواع البيانات الضخمة
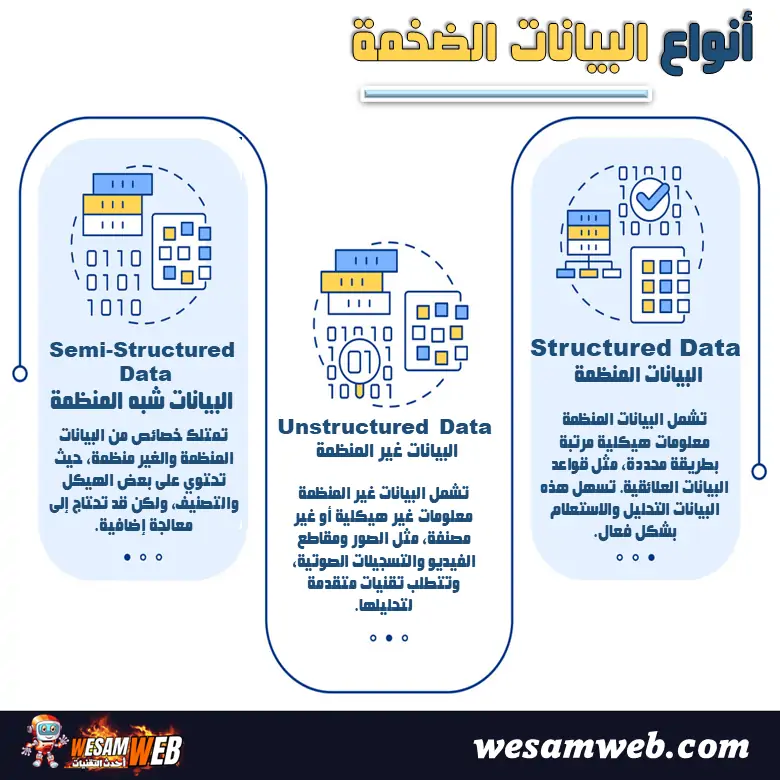
تنقسم البيانات الضخمة إلى عدة أنواع رئيسية تختلف بحسب طريقة التنظيم، وآلية التخزين، وأساليب المعالجة والتحليل. ويساعد فهم هذه الأنواع على اختيار التقنيات المناسبة لتحليل البيانات واستخراج المعلومات الدقيقة، خاصة مع التوسع الكبير في استخدام الذكاء الاصطناعي والحوسبة السحابية وتحليلات البيانات الحديثة.
وتكمن أهمية تصنيف البيانات في تسهيل إدارة المعلومات وتحسين كفاءة المعالجة، إذ إن لكل نوع خصائص تقنية مختلفة تتطلب أدوات وأساليب متخصصة. وتنقسم البيانات الضخمة بشكل أساسي إلى البيانات المنظمة، والبيانات غير المنظمة، والبيانات شبه المنظمة.
البيانات المنظمة Structured Data
تشير البيانات المنظمة إلى البيانات التي يتم تخزينها داخل بنية واضحة وثابتة، مثل الصفوف والأعمدة الموجودة في قواعد البيانات التقليدية. ويتميز هذا النوع بسهولة البحث والتحليل والمعالجة، لذلك يعد الأكثر استخداما داخل المؤسسات المالية والطبية والإدارية.
وتعتبر البيانات المنظمة من أكثر أنواع البيانات ملاءمة للتحليل السريع، لأنها تعتمد على تنسيق موحد يسهل على أنظمة الكمبيوتر قراءته وفهمه. وغالبا ما يتم تخزينها داخل قواعد البيانات العلائقية وتعتمد على لغة SQL لإجراء العمليات والاستعلامات المختلفة.
أبرز أمثلة البيانات المنظمة:
• قواعد البيانات العلاقية Relational Databases
• ملفات Excel وCSV
• بيانات العملاء والحسابات البنكية
• السجلات الطبية المنظمة
• بيانات المبيعات والمخزون
• السلاسل الزمنية مثل أسعار الأسهم
البيانات غير المنظمة Unstructured Data
تمثل البيانات غير المنظمة النوع الأكثر انتشارا ضمن عالم البيانات الحديثة، وهي بيانات لا تمتلك بنية ثابتة أو تنسيقا محددا يسهل تخزينه داخل الجداول التقليدية. ولهذا السبب تحتاج إلى تقنيات متقدمة تعتمد على التعلم الآلي والذكاء الاصطناعي لفهمها وتحليلها.
وتكمن قوة هذا النوع في احتوائه على كم هائل من المعلومات التي تعكس سلوك المستخدمين والتفاعلات الرقمية. ورغم صعوبة معالجتها مقارنة بالبيانات المنظمة، إلا أنها أصبحت مصدرا أساسيا لفهم الأنماط والتنبؤ بالاتجاهات المستقبلية.
أبرز أمثلة البيانات غير المنظمة:
• النصوص والمقالات والتعليقات
• الصور ومقاطع الفيديو
• الملفات الصوتية والمكالمات
• منشورات وسائل التواصل الاجتماعي
• رسائل البريد الإلكتروني
• بيانات البث المباشر Streaming Data
• البيانات الجينية والحمض النووي
البيانات شبه المنظمة Semi Structured Data
تجمع البيانات شبه المنظمة بين خصائص البيانات المنظمة والبيانات غير المنظمة، إذ تحتوي على قدر جزئي من التنظيم دون الالتزام ببنية ثابتة بالكامل. ويمنحها ذلك مرونة عالية في التخزين والمعالجة مقارنة بقواعد البيانات التقليدية.
ويستخدم هذا النوع بكثرة في تطبيقات الويب الحديثة والحوسبة السحابية وأنظمة NoSQL، لأنه يسمح بتخزين بيانات متنوعة وقابلة للتطوير بسهولة. كما يساعد على تبادل البيانات بين الأنظمة المختلفة بكفاءة أكبر.
أبرز أمثلة البيانات شبه المنظمة:
• ملفات JSON
• ملفات XML
• قواعد بيانات NoSQL
• بيانات التطبيقات السحابية
• سجلات الويب Web Logs
• البيانات الوصفية Metadata
• خدمات التخزين السحابي مثل Amazon S3 وGoogle Cloud Storage
ما هي خصائص البيانات الضخمة الخمس الرئيسية؟

ققبل أن نبدأ، دعني أخبرك بحقيقة ستغير نظرتك بالكامل إلى عالم التقنية الحديثة. كل ما تسمعه اليوم عن الذكاء الاصطناعي، والتنبؤ بالسلوك البشري، والأنظمة الذكية التي تعرف ما تريده قبل أن تبحث عنه، يعتمد في جوهره على خمس خصائص أساسية فقط. نعم، خمس ركائز هي التي تفصل بين البيانات التقليدية المحدودة وبين عالم البيانات الضخمة القادر على إعادة تشكيل الاقتصاد، والطب، والأمن، والتعليم، والتجارة الرقمية.
هذه الخصائص لا تمثل مجرد مصطلحات أكاديمية معقدة، بل تشكل البنية الحقيقية التي تعتمد عليها كبرى شركات التكنولوجيا في العالم لتحويل مليارات السجلات الرقمية إلى قرارات دقيقة ورؤى استراتيجية وتوقعات مستقبلية مذهلة. وكلما فهمت هذه الخصائص بعمق، أصبحت أكثر قدرة على استيعاب الطريقة التي تعمل بها الأنظمة الرقمية الحديثة خلف الكواليس.
الخاصية الأولى: الحجم Volume
هي الخاصية الأكثر وضوحاً والأسهل فهماً، فالحجم يعني ببساطة الكميات الهائلة من البيانات التي تفوق بكثير قدرة أي نظام تقليدي على تخزينها أو معالجتها. لم نعد نتحدث بالميغابايت أو الغيغابايت، بل أصبحت المقاييس الآن البيتابايت والإكسابايت والزيتابايت، حيث يتجاوز حجم البيانات المنتجة عالمياً يومياً 2.5 كوينتيليون بايت، وهو رقم يصعب تخيله.
ولكن الحجم ليس مجرد رقم ضخم، بل هو تحدٍ حقيقي لهندسة الأنظمة. فلو حاولت تخزين كل بيانات فيسبوك (أكثر من 300 بيتابايت) على أقراص صلبة سعة 1 تيرابايت، فستحتاج إلى 300 ألف قرص، ولو رصفتها بجانب بعضها لامتدت لعدة كيلومترات. ولهذا السبب، ظهرت أنظمة التخزين الموزعة التي توزع البيانات على آلاف الخوادم.
ولا يتمثل التحدي الحقيقي في حجم البيانات فقط، بل في القدرة على تخزينها وإدارتها ومعالجتها بكفاءة عالية. ولهذا ظهرت أنظمة التخزين الموزعة مثل HDFS وخدمات التخزين السحابي مثل Amazon S3، والتي تسمح بتوزيع البيانات على آلاف الخوادم بدلا من الاعتماد على جهاز واحد محدود الإمكانيات.
أبرز النقاط المتعلقة بالحجم:
- يتم إنتاج مليارات البيانات يوميا من المستخدمين والأجهزة الذكية
- التخزين التقليدي لم يعد كافيا للتعامل مع هذا الحجم الهائل
- كلما زادت البيانات، زادت دقة التحليلات والتوقعات
- تعتمد الشركات الكبرى على التخزين الموزع والحوسبة السحابية
- بيانات مستخدمي وسائل التواصل الاجتماعي
- سجلات التجارة الإلكترونية
- بيانات الكاميرات الذكية
- بيانات البنوك والمعاملات المالية
- قواعد البيانات الطبية الضخمة
الخاصية الثانية: السرعة Velocity
تشير السرعة إلى معدل تدفق البيانات إلى النظام، وهذا المعدل في عالمنا اليوم يفوق الخيال. تخيل أن تويتر يستقبل أكثر من 500 مليون تغريدة يوميًا، أي 6000 تغريدة في الثانية. أو تخيل أن مستشعرات محرك طائرة حديثة تنتج 10 غيغابايت من البيانات كل ثانية أثناء الطيران. هذه الأرقام تدفعنا إلى إعادة النظر في مفهوم “المعالجة الآنية”.
لكن السؤال الأساسي هنا هو: هل يمكننا تخزين كل هذه البيانات أولاً ثم تحليلها لاحقاً؟ في كثير من الحالات، الإجابة هي “لا”، لأن البيانات تفقد قيمتها إذا لم تحلل فوراً. ففي تطبيقات كشف الاحتيال المصرفي، على سبيل المثال، يجب تحليل المعاملة فور حدوثها، وليس بعد ساعة؛ وإلا فسيكون الاحتيال قد اكتمل. ومن هنا، برزت تقنيات المعالجة التدفقية (Stream Processing) كحل أساسي لهذا التحدي.
أبرز النقاط المتعلقة بالسرعة:
- البيانات تتدفق بشكل لحظي ومستمر
- المعالجة الفورية أصبحت ضرورة في الأنظمة الحديثة
- تستخدم تقنيات مثل Apache Kafka وSpark Streaming للتحليل المباشر
- الاستجابة السريعة قد تكون أهم من الدقة المطلقة أحيانا
- تحديثات وسائل التواصل الاجتماعي الفورية
- أنظمة التداول المالي المباشر
- بيانات أجهزة الاستشعار الذكية
- تطبيقات الملاحة والخرائط
- منصات البث المباشر Streaming
الخاصية الثالثة: التنوع Variety
ليست كل البيانات متشابهة الشكل أو البنية، وهذه الخاصية تمثل التحدي الأكثر تعقيداً في كثير من الأحيان. ففي الماضي، كنا نتعامل بشكل أساسي مع البيانات المنظمة (Structured) المرتبة في جداول وأنساب محددة مثل قواعد البيانات التقليدية (SQL). أما اليوم، فإن الغالبية العظمى من البيانات (تقدر بنحو 80%) تأتي على شكل بيانات غير منظمة (Unstructured) مثل النصوص الطويلة، الصور، مقاطع الفيديو، التسجيلات الصوتية، وملفات PDF.
وبين هذا وذاك، هناك فئة ثالثة هي البيانات شبه المنظمة (Semi-structured) مثل ملفات JSON و XML و CSV، التي تحتوي على هيكل مرن وغير صارم. على سبيل المثال، منصة فيسبوك تتعامل في وقت واحد مع بيانات منظمة (الملف الشخصي للمستخدم)، وبيانات غير منظمة (الصور والتعليقات النصية)، وبيانات شبه منظمة (سجلات التفاعلات والـ logs). التحدي الأكبر هو كيفية الجمع بين كل هذه الأنواع المتنوعة في تحليل واحد متكامل.
ويعد هذا التنوع من أكبر التحديات التقنية في عالم البيانات الضخمة، لأن كل نوع من البيانات يحتاج إلى أدوات وأساليب تحليل مختلفة. فمعالجة النصوص تعتمد على معالجة اللغة الطبيعية (NLP)، بينما يعتمد تحليل الصور والفيديوهات على الشبكات العصبية التلافيفية (CNN) وتقنيات الرؤية الحاسوبية الحديثة.
أبرز النقاط المتعلقة بالتنوع:
• البيانات قد تكون منظمة أو غير منظمة أو شبه منظمة
• الصور والفيديوهات تمثل جزءا ضخما من البيانات الحديثة
• تحليل كل نوع من البيانات يحتاج إلى تقنيات مختلفة
• توحيد البيانات القادمة من مصادر متعددة يعد تحديا معقدا
الخاصية الرابعة: المصداقية Veracity
ماذا لو كانت البيانات التي تحللها غير دقيقة أو مضللة؟ هنا تأتي الخاصية الرابعة، وهي جودة البيانات ومدى مصداقيتها وثقتنا بها. فالصدق (Veracity) يعني ببساطة درجة الثقة التي يمكن أن نضعها في البيانات التي نجمعها، ومدى خلوها من الأخطاء والتحيزات والتناقضات والضجيج الإحصائي. وهذه الخاصية هي التي تفرق بين تحليل ناجح يغير قواعد اللعبة، وتحليل فاشل يؤدي إلى قرارات كارثية مكلفة.
ولكن من أين تأتي مشكلات المصداقية؟ مصادر عدم الصدق متعددة ومتنوعة: أخطاء بشرية أثناء إدخال البيانات، أعطال تقنية في أجهزة الاستشعار، معلومات مضللة يتم نشرها عمداً، أو تحيزات خفية وغير مقصودة في طريقة تصميم عملية جمع البيانات. على سبيل المثال، إذا قمت بتدريب نموذج ذكاء اصطناعي للتعرف على الوجوه، وكانت بيانات التدريب تحتوي على وجوه شابة فقط، فإن النموذج سيفشل تماماً عند التعامل مع كبار السن. هذا ليس خطأ في الخوارزمية، بل خطأ في صدق تمثيل البيانات للمجتمع الحقيقي.
- الحل يكمن في مراحل التنظيف والتحقق الصارمة، وفهم سياق البيانات، واستخدام تقنيات إحصائية لاكتشاف الشذوذ والتأكد من أن ما نحلله يعكس الحقيقة قدر الإمكان.
- مصادر عدم الصدق تشمل: أخطاء بشرية، أعطال أجهزة الاستشعار، معلومات مضللة متعمدة، وتحيزات خفية في تصميم جمع البيانات.
- البيانات غير الموثوقة تؤدي إلى قرارات خاطئة مكلفة، وفي مجالات مثل التشخيص الطبي أو القيادة الذاتية قد تكلف الأرواح.
وتعد المصداقية من أخطر التحديات في مشاريع البيانات الضخمة، لأن أي خلل في جودة البيانات قد يؤدي إلى قرارات خاطئة أو نتائج مضللة. ولهذا تعتمد المؤسسات الحديثة على تقنيات تنظيف البيانات والتحقق من صحتها قبل استخدامها في التحليلات أو تدريب نماذج الذكاء الاصطناعي.
أبرز النقاط المتعلقة بالمصداقية:
• البيانات الخاطئة تؤدي إلى نتائج وتحليلات مضللة
• الأخطاء البشرية من أبرز أسباب ضعف جودة البيانات
• تنظيف البيانات مرحلة أساسية قبل التحليل
• التحيز في البيانات قد يؤثر على قرارات الذكاء الاصطناعي
الخاصية الخامسة: القيمة Value
وهذه هي الخاصية الأهم على الإطلاق، بل هي الهدف النهائي والمبرر الوحيد لكل ما سبق. فالحجم الضخم، والسرعة الفائقة، والتنوع الكبير، والصدق العالي، كلها مجرد أدوات ووسائل، أما القيمة (Value) فهي الثمرة الحقيقية التي تجنيها من استثمارك في البيانات الضخمة. باختصار شديد، يمكنك أن تمتلك أكبر كمية من البيانات في العالم، وأسرع أنظمة المعالجة، وأدق المصادر، ولكن إذا لم تستخرج منها رؤى قابلة للتنفيذ تؤدي إلى تحسين منتج، أو زيادة أرباح، أو إنقاذ حياة، فأنت ببساطة قد أهدرت كل هذه الإمكانات دون عائد.
ولكن كيف نضمن تحقيق القيمة؟ القيمة نسبية بامتياز، فما يعتبر قيماً لشركة تجارة إلكترونية قد يكون عديم الفائدة تماماً لمستشفى أو جامعة. مثال توضيحي: موقع أمازون يستخرج قيمة من بيانات تصفح العملاء ليوصي بمنتجات مشابهة ويزيد المبيعات، أما المستشفى فيستخرج قيمة من بيانات المرضى التاريخية ليحسن خطط العلاج ويقلل نسبة الوفيات. لذلك، تحقيق القيمة يتطلب أن نبدأ دائماً بالسؤال الأهم: “ما المشكلة التي نحاول حلها؟” قبل أن ننفق المليارات على جمع البيانات وتخزينها.
- القيمة هي ما يحول تكلفة البيانات الضخمة (وهي ضخمة بلا شك) إلى عائد استثماري ملموس، وهي وحدها التي تبرر دخول أي مؤسسة لهذا العالم.
- القيمة نسبية وتعتمد على السياق: ما هو كنز لشركة قد يكون نفاية لأخرى، لذلك ابدأ دائماً بتحديد المشكلة قبل جمع البيانات.
- أمثلة على القيمة: زيادة المبيعات بالتوصيات الذكية، تقليل التكاليف بتحسين سلاسل التوريد، إنقاذ الأرواح بالتشخيص المبكر للأمراض.
ولهذا تستثمر الشركات العالمية مليارات الدولارات في تحليل البيانات، لأنها تدرك أن القدرة على استخراج رؤى قابلة للتنفيذ تمنحها ميزة تنافسية هائلة. فقد تستخدم شركات التجارة الإلكترونية البيانات لتحسين التوصيات وزيادة المبيعات، بينما تعتمد المستشفيات عليها للتنبؤ بالأمراض وتحسين جودة الرعاية الصحية.
أبرز النقاط المتعلقة بالقيمة:
• القيمة هي الهدف النهائي من تحليل البيانات
• البيانات بلا فائدة إذا لم تتحول إلى قرارات عملية
• تساعد البيانات على زيادة الأرباح وتحسين الخدمات
• تختلف قيمة البيانات بحسب طبيعة كل مؤسسة واحتياجاتها
وفي النهاية، يجب فهم أن هذه الخصائص الخمس لا تعمل بشكل منفصل، بل تشكل منظومة مترابطة تحدد قوة وكفاءة أي نظام بيانات حديث. فالحجم الضخم يحتاج إلى سرعة عالية، والسرعة تحتاج إلى بيانات موثوقة، والتنوع يتطلب تقنيات تحليل متقدمة، بينما تبقى القيمة هي النتيجة النهائية التي تسعى إليها جميع المؤسسات في عصر الاقتصاد الرقمي.
ما هي الرؤية والموثوقية في البيانات الضخمة؟
هل تعلم أن أغنى شركات العالم لا تملك بالضرورة أكبر كمية من البيانات؟ بل تمتلك القدرة على تصديق ما تراه (الموثوقية) ثم رؤية ما لا يراه الآخرون (الرؤية). فبدون هذين العنصرين، تتحول البيتابايتات الهائلة إلى مجرد فوضى رقمية مكلفة، وبدونهما، تصبح قراراتك مجرد تكهنات جميلة لكنها فارغة. لنكتشف معاً الفرق العميق بينهما ولماذا هما مفتاح النجاح أو الفشل في عالم البيانات.
توضيح مهم قبل أن نبدأ: أحياناً يخلط البعض بين مفهومين متكاملين لكنهما مختلفين تماماً. الموثوقية (Veracity) هي صفة في البيانات نفسها، وتتعلق بدرجة دقتها ونظافتها وخلوها من الأخطاء. أما الرؤية (Vision) فهي صفة في قدراتنا التحليلية، وتتعلق بقدرتنا على استخراج الأنماط الخفية والاتجاهات المستقبلية من هذه البيانات بعد أن أصبحت موثوقة. ببساطة، الموثوقية تسأل “هل هذه البيانات صحيحة؟” بينما الرؤية تسأل “ماذا تخبرنا هذه البيانات عن المستقبل؟”
جدول المقارنة: الموثوقية مقابل الرؤية في البيانات الضخمة
| الجانب | الموثوقية (Veracity) | الرؤية (Vision) |
|---|---|---|
| التعريف البسيط | درجة دقة وموثوقية البيانات وخلوها من الأخطاء والتشوهات | القدرة على استخراج الأنماط والاتجاهات واتخاذ قرارات استراتيجية |
| السؤال الأساسي | هل هذه البيانات صحيحة وتعكس الواقع؟ | ماذا تخبرنا هذه البيانات عن المستقبل؟ |
| مجال التركيز | جودة البيانات وتنقيتها والتحقق من صحتها | تحليل البيانات وفهم العلاقات والتنبؤ |
| التحدي الرئيسي | التعامل مع بيانات متنوعة ومتناقضة تحتوي على أخطاء أو تشوهات | تحويل الكم الهائل من المعلومات إلى حكم استراتيجي واضح |
| الحلول والتقنيات | تقنيات التنظيف (Data Cleansing)، التحقق الإملائي، توحيد التنسيقات، التحليل الإحصائي لاكتشاف الشذوذ | خوارزميات التعلم الآلي، تحليل الأنماط، نماذج التنبؤ، أدوات التصور البياني |
| مثال عملي (طب) | التأكد من أن سجلات المرضى خالية من الأخطاء الإملائية والتكرارات | تحليل البيانات الطبية لتوقع انتشار الأمراض وتحديد المناطق التي تحتاج للعلاج |
| مثال عملي (تجارة إلكترونية) | التأكد من أن أرقام المبيعات تعكس المعاملات الحقيقية دون ازدواجية | تحليل عادات الشراء لتحديد المنتجات الأكثر شيوعاً وفهم دوافع الشراء |
| مثال عملي (أعمال) | التأكد من أن بيانات الأداء المالي تعكس الوضع الحقيقي للشركة | فهم كيف يؤثر تغيير استراتيجية التسويق على المبيعات وردود فعل العملاء |
| النتيجة النهائية | زيادة الثقة في البيانات وجعلها أكثر قوة للاعتماد عليها | تحسين قدرة القادة على اتخاذ قرارات دقيقة وفعالة موجهة استراتيجياً |
باختصار شديد، لا يمكن لأحدهما أن يعمل بدون الآخر. فالبيانات غير الموثوقة (غير الدقيقة) ستنتج رؤى خاطئة ولو كانت خوارزمياتك ذكية، والبيانات الموثوقة بدون رؤية (قدرة على التحليل) ستظل كنزاً مدفوناً لا أحد يستفيد منه. المؤسسات الناجحة هي التي تستثمر في تنقية بياناتها (لتحقيق الموثوقية) وفي تدريب فرقها على التحليل المتقدم (لتحقيق الرؤية) في نفس الوقت.
ما هي استخدامات البيانات الضخمة؟
ببساطة، لا يوجد مجال حيوي في عصرنا إلا وتخترقه البيانات الضخمة. فمن اللحظة التي تستيقظ فيها على صوت منبه ساعتك الذكية، حتى لحظة خروجك للنوم بعد مشاهدة فيلم أوصى لك به موقع المشاهدة، تكون البيانات الضخمة تعمل خلف الكواليس لتحسين حياتك وقراراتك، سواء أدركت ذلك أم لم تدرك.
أبرز استخدامات البيج داتا في العالم اليوم:
- الحوكمة والمدن الذكية: تحليل بيانات استهلاك الكهرباء والمياه لترشيد الاستخدام، تحسين خدمات جمع النفايات في المنزل الذكي، وقياس رضا المواطنين عن الخدمات الحكومية.
- التسويق والأعمال: تحليل سلوك المستهلك بدقة، وتطوير الحملات التسويقية بناءً على اهتماماته الفعلية، وتقسيم العملاء إلى مجموعات ذكية لكل مجموعة رسائلها ومنتجاتها المخصصة.
- تحسين العمليات التصنيعية والتجارية: مراقبة خطوط الإنتاج لحظياً، اكتشاف الأعطال قبل وقوعها (الصيانة التنبؤية)، وتحسين سلاسل التوريد لتقليل التكاليف وزيادة الكفاءة.
- الأجهزة القابلة للارتداء (Wearables): تقوم الساعات الذكية وأساور تتبع اللياقة البدية بتحليل نبضات القلب، وقياس عدد الخطوات، ومراقبة جودة النوم، وتقديم نصائح صحية مخصصة لكل مستخدم.
- الصحة العامة والرعاية الطبية: تحليل ملايين السجلات الطبية لتوقع انتشار الأمراض، تطوير خطط علاجية مخصصة لكل مريض (الطب الشخصي)، وتسريع اكتشاف الأدوية الجديدة.
- مراقبة حركة المرور في المدن الذكية: تحليل بيانات كاميرات المراقبة وأجهزة الاستشعار لتخفيف الازدحام، تحسين توقيت إشارات المرور، وتوجيه السائقين إلى أسرع الطرق في الوقت الفعلي.
- خلق الأمن وإنفاذ القانون: تحليل أنماط الجريمة للتنبؤ بمناطق الخطر، كشف الأنشطة المشبوهة عبر مراقبة البيانات الرقمية، ومكافحة غسل الأموال والجرائم الإلكترونية.
- الخدمات المصرفية والمالية: كشف الاحتيال أثناء حدوث المعاملة، تقييم الجدارة الائتمانية بدقة أكبر، وتحليل الأسواق المالية لاتخاذ قرارات استثمارية أسرع.
- التعليم والتعلم الذكي: تحليل أداء الطلاب لتحديد نقاط الضعف لديهم، تصميم مسارات تعليمية مخصصة لكل طالب، والتنبؤ بالطلاب المعرضين لخطر التسرب الدراسي.
- الزراعة الدقيقة (Precision Agriculture): تحليل بيانات الطقس والتربة وأجهزة الاستشعار في الحقول لتحسين الري، تحديد موعد الزراعة والحصاد المثالي، وزيادة الإنتاجية مع تقليل استخدام الموارد.
- وسائل الإعلام والترفيه: توصية بمحتوى يناسب ذوقك على منصات مثل نتفليكس ويوتيوب، تحليل تفاعل الجمهور مع البرامج، وتحديد توقيت نشر المحتوى لتحقيق أقصى مشاهدة.
- النقل والخدمات اللوجستية: تحسين مسارات التوصيل لشركات مثل أوبر وأمازون، تقليل استهلاك الوقود، وتوقع أوقات التأخير قبل حدوثها.
فوائد استخدام البيانات الضخمة في الأعمال التجارية
قد يكون وجود البيانات الضخمة وتراكمها هو الفارق الوحيد بين شركة تزدهر وأخرى تندثر. فتحليل هذه البيانات باستخدام الأنظمة الحديثة يساعد المؤسسات على اتخاذ قرارات أذكى، وتحديد استراتيجيات أكثر دقة، مما يقلل التكاليف ويعزز الدخل في أي عمل تجاري بغض النظر عن حجمه أو مجاله.
اكتساب العملاء والاحتفاظ بهم
لكي تزدهر أي شركة، يجب أن تتخذ الإستراتيجية المناسبة لبيع منتجاتها، وهنا يأتي دور البيانات الضخمة بشكل حاسم. فمن خلال تحليل سلوك الملايين من المستهلكين، يمكن للشركات أن تتعلم بالضبط ما يريده العملاء قبل أن يطلبوه، وليس بعد فوات الأوان.
ببساطة، مراقبة عادات الاستهلاك اليومية، وفهم أنماط الشراء الموسمية، وتحليل أسباب ترك العملاء للعلامة التجارية، كلها مهام تصبح دقيقة وسهلة بفضل البيانات الضخمة. ونتيجة لذلك، يمكن للشركات تعزيز ولاء العملاء للمنتج من خلال اكتشاف هذه الاتجاهات الخفية، ثم إنشاء طرق مبتكرة لجعل العملاء أكثر سعادة وارتباطاً بالعلامة التجارية.
أداء هادف ومركز (استهداف دقيق)
لماذا تنفق ميزانيات ضخمة على إعلانات تصل إلى أشخاص لا يهتمون بمنتجك؟ البيانات الضخمة تحل هذه المعضلة بذكاء. فهي تمكن الشركات من تقديم منتجاتها وخدماتها إلى جماهير مستهدفة مناسبة لكل منتج، دون إنفاق فلس واحد على جهات لا تهمها. على سبيل المثال، يمكن تتبع عادات الشراء عبر الإنترنت للعملاء بدقة متناهية، ومعرفة المنتجات التي يتصفحونها، والتي يتركونها في السلة دون إتمام الشراء، والتي يعودون لشرائها لاحقاً. وهذه الحقائق بدورها تمكن الشركات من إنشاء حملات تسويقية مركزة وفعالة، تتجاوز توقعات العملاء وتعزز الولاء للعلامة التجارية، لأنها تخاطبهم بما يهتمون به حقاً، وليس بما نعتقد أنهم يهتمون به.
تحديد المخاطر المحتملة وإدارتها
تواجه الشركات في الوقت الحاضر مجموعة واسعة من المخاطر، بدءاً من التقلبات الاقتصادية، ومروراً بالمنافسة الشرسة، وصولاً إلى الاحتيال والهجمات السيبرانية. هناك العديد من المشكلات التي يمكن أن تعرض بقاء الشركة للخطر في لحظة واحدة. ولهذا السبب، تحتاج المنظمات إلى إدارة المخاطر بشكل أكثر احترافية من أي وقت مضى في هذا العالم المتقلب. وهنا، تثبت البيانات الضخمة أنها حليف لا يقدر بثمن، فهي تلعب دوراً حاسماً في تطوير حلول مبتكرة لإدارة المخاطر.
يمكن للشركات الآن تحسين نماذجها التنبؤية، وتطوير طرق أفضل لتقليل الخسائر، بل واكتشاف العلامات المبكرة للأزمات قبل أن تتفاقم، مما يحول الاستجابة التفاعلية إلى استباقية ذكية.
ابتكار المنتجات وتطويرها
للمنافسة في اقتصاد اليوم السريع، لا يمكنك الاعتماد على الغريزة وحدها أو على “حاسة البطن” مهما كانت قوية. هنا يأتي الدور الثوري للبيانات الضخمة في ابتكار المنتجات. يمكن للشركات الآن استخدام البيانات لتطوير إجراءات منظمة تتتبع تعليقات المستهلكين، وتقيس نجاح المنتج في السوق، وتقارنه بـ المعايير التنافسية بشكل آني ومستمر.
الأجمل، أن البيانات الضخمة لا تساعد فقط في تحسين السلع الحالية، بل تمكن الشركات من بناء وابتكار سلع جديدة بالكامل كانت تعتبر مستحيلة أو غير مجدية قبل عصر البيانات. كيف يحدث هذا؟ من خلال جمع كميات هائلة من البيانات عن طلبات العملاء الحالية، والاحتياجات غير المُعبّر عنها، ونقاط الألم التي يعانون منها، تستطيع الشركات تصميم منتجات تحل مشكلات حقيقية، وتنجح فور إطلاقها.
أمثلة على استخدام البيانات الضخمة في الصناعات المختلفة

قد تساعد البيانات الضخمة في تحسين حياة الإنسان بعدة طرق تتجاوز بكثير حدود المبيعات والتسويق. ففي الأقسام التالية، سنلقي نظرة على حالات استخدام ملهمة للبيانات الضخمة في العديد من الشركات والمجالات الحيوية، من الرعاية الصحية إلى السفر إلى الفضاء، لنرى كيف تغير هذه التكنولوجيا عالمنا بشكل ملموس.
مجال الرعاية الصحية
تساعد البيانات الضخمة في الكشف المبكر عن الأمراض، مما يجعل الوقاية والعلاج أسهل وأكثر نجاحاً بكثير من الطرق التقليدية. فمن خلال تحليل آلاف السجلات الطبية في لحظات، يمكن للأطباء تحديد المرضى المعرضين لخطر الإصابة بأمراض مزمنة مثل السكري أو أمراض القلب قبل ظهور الأعراض بسنوات. بالإضافة إلى ذلك، يتم تطوير أدوية فعالة لعلاج الأمراض المستعصية باستخدام بيانات ضخمة مستخلصة من الأبحاث الطبية والتجارب السريرية حول العالم، مما يقلص وقت التطوير من عقد كامل إلى بضع سنوات فقط.
وليس هذا فحسب، بل تم إنشاء أدوات وأجهزة استشعار يمكن ارتداؤها لتقييم استهلاك المريض من الطعام وإعداده، ثم إدخاله تلقائياً في سجله الصحي الإلكتروني دون حاجة لتسجيل يدوي. على سبيل المثال، أدرجت شركة أبل هذه التكنولوجيا في منتجاتها HealthKit، وCareKit، وResearchKit، مما يسمح لمستخدمي iPhone بالوصول إلى سجلاتهم الصحية والمعلومات الموجودة على هواتفهم في أي وقت ومشاركتها مع أطبائهم بضغطة زر.
- الكشف المبكر عن الأمراض قبل ظهور الأعراض، مما يزيد فرص العلاج الناجح
- تطوير أدوية أسرع باستخدام تحليل البيانات من التجارب السريرية العالمية
- أجهزة استشعار ذكية تراقب المريض وتحدث سجله الصحي تلقائياً
- منتجات Apple HealthKit تتيح الوصول الفوري للسجلات الصحية من الهاتف
القطاع العام والحكومات
في كل يوم، تواجه الحكومات كميات هائلة من البيانات لا يمكن تصورها. فهي مجبرة على تسجيل ومراقبة العديد من السجلات وقواعد البيانات المتعلقة بالسكان، ونمو المجتمع في العديد من الأبعاد (التعليم، الصحة، الإسكان)، وموارد الطاقة، والخرائط الجغرافية، والشبكات المرورية، وغيرها الكثير. بدون البيانات الضخمة، كانت هذه المهمة ستستنزف وقتاً وجهداً وموارد بشرية لا نهائية، وكانت القرارات ستتخذ بناءً على معلومات قديمة أو غير دقيقة.
تتيح البيانات الضخمة إصدار أحكام سريعة ومستنيرة على مختلف البرامج السياسية والاجتماعية، فضلاً عن تحديد المجالات التي تتطلب اهتماماً فورياً كالمدارس المتداعية أو المستشفيات المزدحمة. وتحتاج الحكومات إليها أيضاً لتتبع الأراضي والماشية، وتحديد مصادر الطاقة الجديدة، ومعالجة الصعوبات الكبرى مثل البطالة والإرهاب من خلال تحليل أنماط التوظيف والسلوكيات المشبوهة.
- إدارة السجلات السكانية ومتابعة النمو في التعليم والصحة والإسكان
- تحديد المناطق التي تحتاج تدخلاً عاجلاً بناءً على بيانات آنية
- تتبع الأراضي والماشية وموارد الطاقة بشكل دقيق
- معالجة البطالة والإرهاب من خلال تحليل الأنماط والسلوكيات
صناعة الإعلام والترفيه
لا مفر من إنشاء كميات هائلة من البيانات مع تزايد وصول الأشخاص إلى الهواتف المحمولة والأدوات الرقمية. فكل مشاهدة، وكل إعجاب، وكل تخطي لأغنية أو فيلم، يتحول إلى نقطة بيانات ثمينة. لقد أدركت الشركات في مجال الإعلام والترفيه قيمة هذه البيانات مبكراً، وتستخدمها الآن لتعزيز نموها وتحسين تجربة مستخدميها بشكل مستمر.
تشمل فوائد البيانات الضخمة في هذا المجال توقع اهتمامات الجمهور بدقة مذهلة، وتحسين أنظمة تشغيل توزيع الوسائط الرقمية، والتخطيط الأمثل للمحتوى بناءً على الطلب الفعلي، والحصول على معلومات ثرية من تعليقات العملاء، والاستهداف الإعلاني الفعال الذي لا يزعج المشاهد بل يقدم له ما يهمه. على سبيل المثال، تستخدم منصة Spotify تحليلات البيانات الضخمة لجمع البيانات من جميع مستخدميها حول العالم، ثم تحللها لتقديم اقتراحات موسيقية ذكية تناسب ذوق كل مستخدم على حدة. وبنفس الطريقة، تقدم Amazon Prime لعملائها كتباً وأفلاماً وموسيقى مخصصة بناءً على تاريخ مشاهداتهم وشرائهم.
- توقع اهتمامات الجمهور وتقديم محتوى مخصص لكل مستخدم
- التخطيط الأمثل للمحتوى بناءً على الطلب الفعلي وليس التوقعات
- تحليل تعليقات العملاء لفهم نقاط القوة والضعف
- Spotify تستخدم البيانات لاقتراح موسيقى ذكية لمليارات المستخدمين
- Amazon Prime تقدم محتوى مخصصاً بناءً على تاريخ المشاهدة والشراء
الأرصاد الجوية والكوارث الطبيعية
تلتقط الأقمار الصناعية وأجهزة استشعار الطقس المنتشرة في أنحاء العالم كميات هائلة من البيانات كل ثانية. يمكن استخدام هذه المعلومات الحيوية للتنبؤ بالطقس بدقة غير مسبوقة، وتحليل ظاهرة الاحتباس الحراري وتأثيراتها، وتحديد أماكن المياه الصالحة للشرب في المناطق النائية، وتوقع اتجاهات الكوارث الطبيعية قبل حدوثها، والتخطيط للاستعداد للكوارث العالمية بشكل يقلل الخسائر البشرية والمادية.
على سبيل المثال الملهم، أتاح مشروع IBM Deep Thunder البحثي إمكانية إصدار تنبؤات دقيقة جداً بالطقس باستخدام المعالجة المتقدمة للبيانات الضخمة. وقد استخدمت هذه التوقعات في التخطيط للكوارث والسلامة العامة، بل وفي توقع احتمالية انقطاع خطوط الكهرباء في مدن مثل طوكيو قبل حدوث العاصفة بأيام، مما يسمح لشركات الطاقة بتجهيز فرق الصيانة مسبقاً.
- التنبؤ بالطقس بدقة غير مسبوقة لعدة أيام مقدماً
- تحليل ظاهرة الاحتباس الحراري وتأثيراتها طويلة المدى
- تحديد أماكن المياه الصالحة للشرب في المناطق النائية
- التنبؤ بالكوارث الطبيعية (أعاصير، فيضانات، حرائق) والتخطيط لها مسبقاً
- مشروع IBM Deep Thunder يقدم تنبؤات دقيقة لانقطاع الكهرباء
صناعة النقل والمواصلات
لقد تم استخدام البيانات الضخمة بعدة طرق مبتكرة لجعل النقل أسهل وأكثر كفاءة وأماناً. فمنذ بداياتها، سعت شركات النقل إلى فهم حركة الركاب وتحسين المسارات، لكن البيانات الضخمة جعلت هذا الحلم حقيقة واقعة. اليوم، يمكن استخدام البيانات الضخمة للتنبؤ بمتطلبات الركاب على الطرق المختلفة وفي الأوقات المختلفة، وترتيب أوقات انتظار أقصر، وتوزيع وسائل النقل بشكل ذكي.
مثال شهير على ذلك، تطبيق خرائط جوجل الذي يقدر كثافة حركة المرور في مختلف الطرق ويحلل الأنماط التاريخية لحركة المرور، لمساعدة المستخدمين على تحديد أسرع الطرق في الوقت الفعلي. بالإضافة إلى ذلك، فإن معالجة البيانات الضخمة وتحليل المعلومات في الوقت المناسب والتي تحدد المواقع المعرضة للحوادث يمكن أن تساعد أيضاً في تقليل الحوادث وتعزيز السلامة المرورية من خلال تحسين تصميم الطرق وإشارات المرور.
أما أوبر، فتقوم بإنشاء واستخدام كميات كبيرة من البيانات حول السائقين ومركباتهم ومواقعهم، وتحلل كل هذه البيانات للتنبؤ بالعرض والطلب، وتحديد الأسعار الديناميكية (Surge Pricing)، وتحديد المسارات المثلى للسائقين. ومن المثير للاهتمام، أن المستخدمين أنفسهم يستخدمون أحياناً الطرق التي سافروا بها مع أوبر في الماضي والتي يتذكرونها لتوفير الوقت والطاقة، مما يعني أن البيانات الضخمة تلعب دوراً ليس فقط في القرارات الكبيرة للمؤسسات، بل أيضاً في أصغر القرارات اليومية في حياتنا.
- التنبؤ بمتطلبات الركاب وتوزيع وسائل النقل بناءً على الطلب المتوقع
- خرائط جوجل تحلل كثافة المرور في الوقت الفعلي لتقديم أسرع الطرق
- تحديد المواقع المعرضة للحوادث وتحسين تصميم الطرق للسلامة
- أوبر تحلل بيانات السائقين والمركبات للتنبؤ بالعرض والطلب والتسعير الديناميكي
- المستخدمون أنفسهم يستخدمون بيانات تجاربهم السابقة لاتخاذ قرارات يومية أذكى
الخدمات المصرفية والمالية
يتزايد حجم البيانات في الصناعة المصرفية بمعدل يفوق الخيال، بل تزيد كل ثانية عن التي قبلها. ومن المتوقع أن يزيد حجم هذه البيانات بنسبة 700% بحلول نهاية العام المقبل، وفقاً لتوقعات GDC (التعاونية الإنمائية العالمية). هذا الانفجار المعلوماتي يشكل تحدياً وهائلاً، لكنه أيضاً فرصة ذهبية لا تعوض.
قد يساعد البحث والتحليل المناسب لهذه البيانات في تحديد الأنشطة غير القانونية مثل إساءة استخدام بطاقات الائتمان، والتلاعب بمعلومات وسجلات المستهلكين، وغسل الأموال، بالإضافة إلى زيادة شفافية الشركات المالية. على سبيل المثال، تستخدم العديد من برامج مكافحة غسل الأموال (AML) في الخدمات المصرفية تحليل البيانات الضخمة للكشف عن المعاملات المشبوهة وتحليل سلوك المستهلكين بشكل مستمر. يعد SAS AML أحد هذه البرامج الرائدة، ويستخدمه Bank of America منذ أكثر من 25 عاماً بنجاح كبير في إحباط مئات المحاولات الإجرامية سنوياً.
- كشف إساءة استخدام بطاقات الائتمان أثناء حدوث المعاملة قبل اكتمالها
- مكافحة غسل الأموال من خلال تحليل أنماط المعاملات المشبوهة
- زيادة شفافية الشركات المالية للمساهمين والجهات التنظيمية
- برنامج SAS AML يستخدمه Bank of America منذ 25 عاماً
- توقع بنسبة 700% في نمو البيانات المصرفية خلال العام القادم
مجال السفر إلى الفضاء
تتلقى وكالات الفضاء من مختلف الدول كميات هائلة من البيانات يوميًا عبر مراقبة الفضاء السحيق، والمعلومات الواردة من الأقمار الصناعية التي تدور حول الأرض، والبعثات الاستكشافية للفضاء الخارجي، والمركبات الجوالة على كواكب أخرى كالمريخ. تعد هذه البيانات شريان الحياة لأي مهمة فضائية، ويتم قياسها الآن بالبيتابايت، لا بالجيجابايت.
تحلل هذه البيانات الضخمة وتستخدم لمحاكاة مسارات الطيران بدقة متناهية قبل إطلاق الصواريخ إلى المدار. قبل كل عملية إطلاق، تجرى محاكاة متطورة تعتمد على البيانات الضخمة لاختبار جوانب عديدة، مثل ظروف الغلاف الجوي العلوي، وحمولة الصاروخ، وموقع المدارات المستهدفة، والمسار المتوقع، وزوايا الإطلاق المثلى.
على سبيل المثال، تقوم وكالة ناسا حاليًا بجمع وتحليل كميات هائلة من البيانات حول تضاريس المريخ، وأحواله الجوية، وخصائصه الأخرى، من العديد من الأقمار الصناعية والمركبات الجوالة، استعدادًا لمهمتها المتقدمة المخطط لها في العقد القادم.
- اتخاذ قرارات حاسمة تعتمد على تحليل دقيق للبيانات قبل استثمار المليارات
- محاكاة مسارات الطيران قبل الإطلاق الفعلي للصواريخ
- تحليل بيانات الأقمار الصناعية والمركبات الجوالة على الكواكب الأخرى
- اختبار عوامل متعددة: الطقس، الحمولة، المدارات، زوايا الانطلاق
- ناسا تجمع بيتابايت من بيانات المريخ لمهماتها المستقبلية
الربط بين البيانات الضخمة والذكاء الاصطناعي وعلم البيانات
تخيل أن البيانات الضخمة هي الوقود الخام، والذكاء الاصطناعي هو المحرك الذي يحرك السيارة، وعلم البيانات هو السائق الذي يقرر أين يتجه ومتى يضغط على المكابح. بدون أي من هذه العناصر الثلاثة، لن تصل إلى أي مكان. لنفهم معاً كيف تعمل هذه الثلاثية العجيبة بتناغم تام لتحويل الأرقام الصماء إلى قرارات ذكية تغير العالم.
الذكاء الاصطناعي والبيانات الضخمة
يعتبر خبراء البيانات والمنظمات الكبرى أن البيانات الضخمة والذكاء الاصطناعي هما الأساطير الحقيقية في ميكانيكا البيانات الحديثة. فبينما توفر البيانات الضخمة الكم الهائل من المعلومات الخام، يمنحها الذكاء الاصطناعي العقل الذي يحللها ويفهمها. تعتقد العديد من الشركات أن الذكاء الاصطناعي يمكنه بالفعل إحداث ثورة كاملة في عملياتها من خلال الاستفادة الذكية من البيانات التنظيمية التي كانت راكدة وغير مستغلة لعقود.
التعلم الآلي، وهو نوع أكثر تطوراً من الذكاء الاصطناعي، يسمح للآلات بتحليل البيانات وإرسالها واستقبالها بل وتعلم مفاهيم جديدة تماماً دون تدخل بشري مباشر. وهنا يأتي الدور الحيوي للبيانات الضخمة، فهي التي تمكن الشركات من استخلاص المعلومات التي تحتاجها والحصول على رؤى مفيدة وموثوقة من بحر البيانات الهائل. يعتقد البعض خطأً أن الذكاء الاصطناعي سيحل محل البشر بالكامل، ولكن الحقيقة أن البيانات الضخمة أثبتت عكس ذلك، فهي تحتاج إلى الذكاء البشري لتفسير السياقات العاطفية والاجتماعية التي لا تستطيع الآلات فهمها.
- البيانات الضخمة هي الوقود الخام، والذكاء الاصطناعي هو المحرك الذي يحوله إلى طاقة
- التعلم الآلي يمكن الآلات من تعلم مفاهيم جديدة دون برمجة بشرية مباشرة
- الذكاء الاصطناعي وحده لا يستطيع فهم العواطف والسياقات الاجتماعية، وهنا يأتي دور الإنسان
- الآلات تستنتج حقائق باردة، أما البشر فيضيفون الذكاء العاطفي والحكمة
- البيانات الضخمة تمنح الذكاء الاصطناعي حجم البيانات الذي يحتاجه ليتعلم بدقة
علم البيانات والبيانات الضخمة
علم البيانات هو الجسر الحيوي الذي يصل بين الكم الهائل من البيانات الخام وبين القرارات الذكية القابلة للتنفيذ. فعلماء البيانات هم أولئك المحترفون الذين يمتلكون المهارات الفريدة التي تمزج بين إحصاءات الرياضيات، وبرمجة الحاسوب، والمعرفة العميقة بمجال العمل. بفضل علم البيانات، يمكن للمؤسسات أن تحول الفوضى الرقمية إلى رؤى منظمة تغير طريقة عملها بالكامل.
لا يستطيع عالم البيانات تحليل رغبات العميل فحسب، بل يمكنه أيضاً فهم المعايير واللوائح المحلية لأسواق معينة، وهو ما تعجز عنه الآلات وحدها. فبينما يستطيع الذكاء الاصطناعي اكتشاف أن العملاء في منطقة معينة يشترون منتجاً معيناً بكثرة، يستطيع عالم البيانات أن يفسر أن هذا السلوك قد يكون مرتبطاً بعادات ثقافية أو مناسبات موسمية أو حتى ظروف اقتصادية محلية. وباستخدام هذه البيانات العميقة، يقدم علماء البيانات أفضل فرص السوق التي قد لا يمكن تحقيقها من خلال الاعتماد على التعلم الآلي وحده، لأنهم يضيفون طبقة القرار البشري الواعي فوق طبقة التحليل الآلي البارد.
مميزات علم البيانات مع البيج داتا
- علم البيانات هو الجسر بين البيانات الخام والقرارات الذكية القابلة للتنفيذ
- عالم البيانات يمزج بين الإحصاء، البرمجة، ومعرفة مجال العمل في آن واحد
- فهم السياقات المحلية (العادات، القوانين، الثقافات) هو ما يميز الإنسان عن الآلة
- الذكاء الاصطناعي يكتشف الأنماط، وعالم البيانات يفسر الأسباب الحقيقية وراءها
- علم البيانات يضيف طبقة القرار البشري الواعي فوق طبقة التحليل الآلي البارد
- أفضل فرص السوق تكتشف عندما يتعاون عالم البيانات مع الذكاء الاصطناعي وليس عندما يحل أحدهما مكان الآخر
ختاماً لهذا الربط الثلاثي، تذكر دائماً أن البيانات الضخمة هي المادة الخام، والذكاء الاصطناعي هو أداة التحليل القوية، وعلم البيانات هو الحكمة البشرية التي توجه هذه الأداة نحو الأهداف الصحيحة. من يظن أن أحد هذه العناصر يمكنه الاستغناء عن الآخر، فهو لم يفهم بعد كيف تعمل ثورة البيانات الحقيقية.
ونتيجة لذلك، فمن الواضح أنه من خلال الجمع بين الذكاء الاصطناعي والبيج داتا، سوف نصل إلى عدد كبير من المفاهيم والإمكانيات الجديدة، كل منها لديه القدرة على إحداث ثورة في جزء كبير من المنظمات المختلفة. قد يساعد الذكاء الاصطناعي والبيانات الضخمة معًا المؤسسات على فهم اهتمامات المستهلكين وطلباتهم بشكل أفضل باستخدام تقنيات التعلم الآلي، قد تتمكن العديد من المؤسسات والشركات من فهم اهتماماتها واهتمامات عملائها بسرعة.
مقالة ذات صلة: ما هو علم البيانات Data Science؟ معرفة البوابة نحو مستقبل التحليل الذكي.
الحوسبة السحابية والبيانات الضخمة
تخيل أن لديك كنزاً من البيانات الضخمة لكنك لا تملك مكاناً لتخزينه ولا آلات لتحليله. الحوسبة السحابية هي الحل السحري: مستودع وآلات ثقيلة في آن واحد، متاحة عند الطلب وبدون استثمارات مكلفة.
تشكل الحوسبة السحابية والبيانات الضخمة تحولاً هائلاً في عالم التكنولوجيا. يعتبر السحاب منصة مثالية للتعامل مع الحجم الهائل للبيانات، حيث يمكن للمؤسسات استئجار موارد الحوسبة والتخزين حسب الحاجة دون استثمارات ضخمة. يتيح هذا التوسع غير المحدود والوصول السريع من أي مكان.
- الدفع حسب الاستخدام يمنع هدر المال على موارد لا تحتاجها
- توسع فوري: تحتاج مساحة أكبر؟ اضغط زراً فقط
- وصول عالمي للبيانات من أي جهاز ومكان
تتيح الحوسبة السحابية قدرات معالجة هائلة لتحليل البيانات الضخمة بسرعات خيالية. يمكن تكوين الموارد بشكل ديناميكي لمواكبة احتياجات التحليل، فتضاعف القوة في لحظات الذروة وتخفضها في الهدوء. يعزز هذا استخراج رؤى معمقة وقرارات دقيقة دون انتظار أيام.
- معالجة موزعة توزع عبء البيتابايت على آلاف الخوادم في ثوان
- مرونة كاملة تزيد القوة وقت الحاجة وتخفضها للتوفير
يسهم نموذج الدفع حسب الاستهلاك في تحكم أفضل بالتكاليف وفعالية أكبر. لم تعد البيانات الضخمة حكراً على الشركات العملاقة، بل بفضل السحاب أصبحت في متناول الجميع.
- أمن وحماية عالية لبياناتك مع توفر دائم
- لا حاجة لفريق صيانة خوادم، مزود السحاب يتولى كل شيء
تأثير البيانات الضخمة على التسويق الرقمي
هل تساءلت يوماً كيف تعرف مواقع التسوق ما تريده بالضبط قبل أن تبحث عنه؟ هذا هو سحر البيانات الضخمة في التسويق الرقمي، حيث تحول التخمين إلى علم دقيق، وتجعل كل إعلان تراه مناسباً لك بشكل مدهش.
تتطلب خيارات التسويق الحديثة استخدام البيانات الضخمة، فالبيانات المعقدة والأعداد الهائلة لا تتوافق مع البرامج العادية وتستلزم تقنيات متخصصة. فيما يلي أبرز تأثيرات البيانات الضخمة في التسويق الرقمي:
- حملات أكثر فعالية: الحملات التي تستخدم المزيد من البيانات تكون أكثر نجاحاً، فهي تتنبأ بسلوك المستخدم واتجاهات الشراء بدلاً من التخمين
- قرارات أفضل للتسعير: تحليل أسعار المنافسين، حالة صفقاتهم، وكمية الطلب لتحديد السعر الأمثل
- إنشاء المحتوى الصحيح: تصميم محتوى موقع الويب وفقاً لاهتمامات جمهورك المستهدف بدقة
مصادر الوصول إلى البيانات الضخمة
- الوسائط: أسرع طريقة لفهم أنماط سلوك الجماهير
- الويب: مجموعة هائلة من البيانات المتاحة للمستهلكين والشركات
- إنترنت الأشياء (IoT): بيانات فورية من أجهزة استشعار متصلة بالمعدات الكهربائية
- قواعد البيانات: مثل MS Access، DB2، Oracle، SQL، Amazon Simple
أنواع تحليل البيانات الضخمة
- التحليل الوصفي: ينظر إلى الماضي ويستكشف تفاصيل الأحداث باستخدام الإحصائيات الموجزة
- التحليلات التنبؤية: تتنبأ بالمستقبل باستخدام الإحصاءات، النمذجة، استخراج البيانات، والتعلم الآلي
- التحليلات المستقبلية: أحد الأنواع الثلاثة الرئيسية للتحليلات التي تستخدمها كبرى الشركات
- التحليل التشخيصي: يحدد سبب حدوث شيء ما باستخدام استخراج البيانات والارتباط
- التحليلات السيبرانية: مزيج من الأمن السيبراني وتحليل البيانات لتحديد نقاط الضعف والتنبؤ بالهجمات
أدوات تحليل البيانات الضخمة
يعد اختيار أداة تحليل البيانات الضخمة المناسبة قراراً استراتيجياً يؤثر بشكل مباشر على جودة الرؤى المستخلصة وسرعة الحصول عليها. فمع تعدد الأدوات وتنوع وظائفها، يجب على المؤسسات أن تختار بعناية ما يتناسب مع حجم بياناتها وميزانيتها. فيما يلي أشهر أدوات التحليل مع روابطها الرسمية:
- Xplenty: خدمة سحابية متكاملة تُستخدم لتنظيف البيانات ودمجها وتحويلها دون الحاجة لكتابة أكواد برمجية معقدة
- Improvado: أداة متخصصة لمساعدة الشركات بجميع أحجامها في جمع وفرز وتحليل بيانات التسويق من أكثر من 500 منصة مختلفة
- Google Analytics: لوحة تحكم شاملة تتيح التحليل الرسومي والمرئي لبيانات المواقع والتطبيقات، مع تكامل سلس مع مصادر متعددة
- Skytree: واحدة من أقوى الأدوات لإنشاء نماذج تنبؤ دقيقة باستخدام تقنيات التعلم الآلي المتقدمة، وتتميز بسرعتها العالية
- Apache Spark: محرك تحليل موحد مفتوح المصدر لمعالجة البيانات الضخمة بسرعات فائقة بفضل الاعتماد على المعالجة في الذاكرة العشوائية
- Apache Hadoop: منصة مفتوحة المصدر رائدة لمعالجة وتخزين البيانات على نطاق واسع باستخدام نموذج MapReduce ونظام الملفات الموزع HDFS
تأثير الـ Big data على التسويق الرقمي
هل تساءلت يوماً كيف تعرف مواقع التسوق ما تريده بالضبط قبل أن تبحث عنه؟ هذا هو سحر البيانات الضخمة في التسويق الرقمي، حيث تحول التخمين إلى علم دقيق، وتجعل كل إعلان تراه مناسباً لك بشكل مدهش.
تتطلب خيارات التسويق الحديثة استخدام البيانات الضخمة، فالبيانات المعقدة والأعداد الهائلة لا تتوافق مع البرامج العادية وتستلزم تقنيات متخصصة. فيما يلي أبرز تأثيرات البيانات الضخمة في التسويق الرقمي:
- حملات أكثر فعالية: الحملات التي تستخدم المزيد من البيانات تكون أكثر نجاحاً، فهي تتنبأ بسلوك المستخدم واتجاهات الشراء بدلاً من التخمين
- قرارات أفضل للتسعير: تحليل أسعار المنافسين، حالة صفقاتهم، وكمية الطلب لتحديد السعر الأمثل
- إنشاء المحتوى الصحيح: تصميم محتوى موقع الويب وفقاً لاهتمامات جمهورك المستهدف بدقة
مصادر الوصول إلى البيانات الضخمة
- الوسائط: أسرع طريقة لفهم أنماط سلوك الجماهير
- الويب: مجموعة هائلة من البيانات المتاحة للمستهلكين والشركات
- إنترنت الأشياء (IoT): بيانات فورية من أجهزة استشعار متصلة بالمعدات الكهربائية
- قواعد البيانات: مثل MS Access، DB2، Oracle، SQL، Amazon Simple
أنواع تحليل الـ Big data
- التحليل الوصفي: ينظر إلى الماضي ويستكشف تفاصيل الأحداث باستخدام الإحصائيات الموجزة
- التحليلات التنبؤية: تتنبأ بالمستقبل باستخدام الإحصاءات، النمذجة، استخراج البيانات، والتعلم الآلي
- التحليلات المستقبلية: أحد الأنواع الثلاثة الرئيسية للتحليلات التي تستخدمها كبرى الشركات
- التحليل التشخيصي: يحدد سبب حدوث شيء ما باستخدام استخراج البيانات والارتباط
- التحليلات السيبرانية: مزيج من الأمن السيبراني وتحليل البيانات لتحديد نقاط الضعف والتنبؤ بالهجمات
أدوات تحليل البيانات الضخمة
يعد اختيار أداة تحليل البيانات الضخمة المناسبة قراراً استراتيجياً يؤثر بشكل مباشر على جودة الرؤى المستخلصة وسرعة الحصول عليها. فمع تعدد الأدوات وتنوع وظائفها، يجب على المؤسسات أن تختار بعناية ما يتناسب مع حجم بياناتها وميزانيتها. فيما يلي أشهر أدوات التحليل مع روابطها الرسمية:
- Xplenty: خدمة سحابية متكاملة تُستخدم لتنظيف البيانات ودمجها وتحويلها دون الحاجة لكتابة أكواد برمجية معقدة
- Improvado: أداة متخصصة لمساعدة الشركات بجميع أحجامها في جمع وفرز وتحليل بيانات التسويق من أكثر من 500 منصة مختلفة
- Google Analytics: لوحة تحكم شاملة تتيح التحليل الرسومي والمرئي لبيانات المواقع والتطبيقات، مع تكامل سلس مع مصادر متعددة
- Skytree: واحدة من أقوى الأدوات لإنشاء نماذج تنبؤ دقيقة باستخدام تقنيات التعلم الآلي المتقدمة، وتتميز بسرعتها العالية
- Apache Spark: محرك تحليل موحد مفتوح المصدر لمعالجة البيانات الضخمة بسرعات فائقة بفضل الاعتماد على المعالجة في الذاكرة العشوائية
- Apache Hadoop: منصة مفتوحة المصدر رائدة لمعالجة وتخزين البيانات على نطاق واسع باستخدام نموذج MapReduce ونظام الملفات الموزع HDFS
مستقبل البيانات الضخمة
وفقاً لمتخصصي علم البيانات، كل شخص يعيش في مدينة حديثة ويستخدم الأدوات الرقمية ينتج حوالي 1.5 غيغابايت من البيانات كل ثانية. وهذا العدد يتزايد يومياً، ويتم حفظ البيانات بمعدلات أسرع من أي وقت مضى.
البيانات الضخمة بمعناها الدقيق ليست مفهوماً جديداً، فالبشر أدركوا منذ زمن أنه مع المزيد من البيانات يمكننا إيجاد العلاقات بين الأحداث، لكننا كنا نفتقر للبنية التحتية والمنصة. أصبحت هذه المنصة ممكنة بفضل الإنترنت وتقنيات الحوسبة السحابية.
في المستقبل القريب، مع استمرار انتشار إنترنت الأشياء، ستتوسع سرعة وكمية توليد البيانات بشكل هائل. ليس هناك شك أن الشركات مضطرة لتبني إجراءات تعتمد على البيانات، ولكن الشركات التي ستزدهر هي التي ستفعل ذلك في أسرع وقت ممكن.
استنتاج
البيانات الضخمة ليست موضوعاً يمكن تمريره بسهولة أو تجاهله بأي حال من الأحوال. صحيح أن أبرز الجهات المستخدمة لها هي الشركات العملاقة مثل جوجل وأمازون وفيسبوك، ولكن لا يمكن القول أبداً أن البيانات الضخمة لا تنطبق على الشركات العادية والصغيرة. فالحقيقة، أن عصر البيانات قد فتح أبوابه للجميع، وليس هناك حاجة لأن تكون عملاقاً تقنياً لتستفيد من هذه الثورة.
يمكنك أيضاً استخدام الطرق الشائعة وأساليب التطبيق المعروفة لهذا النظام مجاناً وبدون وسطاء. فلا تحتاج بالضرورة إلى تحليلات متقدمة أو فرق ضخمة من علماء البيانات. يكفي أن تبدأ بإنشاء نظام مناسب لجمع المعلومات من المصادر المتاحة حولك، مثل شبكات التواصل الاجتماعي، ثم جمع أي معلومات قد تكون ذات قيمة لعملك أو قراراتك في هذا النظام، وبعد ذلك مراجعة المعلومات ذات الصلة واستخراج الرؤى المفيدة منها.
أما إذا كنت ترغب في إنجاز هذه المهمة بشكل احترافي وعلى نطاق أوسع، فمن الأفضل أن تترك الإجراء للشركات المتخصصة ومقدمي الخدمات النشطة في هذه الصناعة. الخلاصة الأهم، أن البيانات الضخمة لم تعد رفاهية، بل أصبحت ضرورة، والمهم ليس كم تملك من بيانات، بل كيف تستخدم ما تملكه منها.
وأخيراً، تذكر دائماً أن البيانات الضخمة أداة قوية، لكنها تظل مجرد أداة. العبرة الحقيقية تكمن في الحكمة البشرية التي توجه هذه الأداة، وفي القرارات الذكية التي تتخذ بناءً على ما تكتشفه من أنماط واتجاهات. فالبيانات وحدها لا تغير العالم، بل ما نفعله بها هو ما يحدث الفرق الحقيقي.
