


علم البيانات (Data Science) هي دراسة استخدام الأدوات والتقنيات الحديثة لاكتشاف الأنماط المخفية في البيانات، واستخلاص المعلومات القيمة منها، وتطبيقها في اتخاذ القرارات التجارية. يقوم علماء البيانات باستخدام خوارزميات التعلم الآلي المعقدة لإنشاء نماذج توقعات. ويمكن أن تأتي البيانات المستخدمة في التحليل من مصادر متنوعة وبأشكال مختلفة.
نظرًا للتوفر الواسع للبيانات، أصبح علم البيانات الآن مكونًا أساسيًا وحيويًا في كل قطاع. في الواقع، تُعد علوم البيانات من أكثر المواضيع المثيرة للجدل في الصناعات التقنية هذه الأيام.
لقد ازدادت شعبية الـ Data Science على مر السنوات، وبدأت الشركات في استخدام الأساليب العلمية للتحول الرقمي لتوسيع عملياتها وتحسين رضا العملاء. في هذا المقال، سنتعرف أكثر على علوم البيانات وأهميتها في الصناعة والحياة اليومية؛ وسنلقي نظرة على مسؤوليات الباحث في البيانات؛ وأخيرًا، سنتناول بعض تطبيقات علوم البيانات.
جدول المحتويات
- ما هو علم البيانات Data Science ؟
- التطور التاريخي لمجال علم البيانات
- الفرق بين علم البيانات وعالم البيانات
- ما هي المهارات والأدوار التي يجب أن يتعلمها عالم البيانات؟
- عملية علم البيانات
- مثال على دورة حياة علم البيانات: خطوات متكاملة لتحقيق رؤى دقيقة
- ما هي أنواع علم البيانات ولماذا هي مهمة؟
- أهمية علم البيانات
- ما هي تطبيقات علم البيانات؟
- بعض المفاهيم الإحصائية اللازمة لعلم البيانات
- ما الفرق بين علم البيانات واستخراج البيانات؟
- خريطة طريق تعلم علم البيانات
- وظائف علم البيانات في العالم ومتوسط الرواتب
- العلاقة بين علم البيانات والذكاء الاصطناعي
- أوجه التشابه بين علم البيانات والتعلم الآلي
- الفرق بين Data Science والتعلم الآلي
- الفرق بين علم البيانات والتعلم العميق
- المستقبل والآثار الواعدة لعلم البيانات
- ما فائدة علم البيانات؟
- لماذا تهتم المملكة العربية السعودية بتدريس علم البيانات؟
- إستنتاج
ما هو علم البيانات Data Science؟
علم البيانات هو مجال دراسي يستعين بأدوات وتقنيات حديثة للكشف عن الأنماط المخبأة في البيانات، واستخلاص معلومات قيمة منها، ثم توظيفها في اتخاذ القرارات الإستراتيجية. تنعكس هذه الرؤى والمعرفة العملية على نطاق واسع من المجالات والتطبيقات المتنوعة. يجمع هذا التخصص بين الإحصاء وتحليل البيانات والمعلوماتية، مع الاستفادة من الأدوات والأساليب المتقدمة المستمدة من الرياضيات وعلوم الكمبيوتر وتكنولوجيا المعلومات، إلى جانب مهارات البرمجة المتطورة.
في الوقت الحالي، يشهد Data Science نموًا متسارعًا يُحدث تحولات جذرية في العالم الرقمي. يُعتبر هذا المجال من المصطلحات الرائجة في قطاع التكنولوجيا، حيث يتزايد الطلب عليه باستمرار. الحاجة إلى علماء البيانات تتعاظم بفضل رغبة الشركات في تحويل البيانات إلى رؤى عملية. تبرز شركات مثل Google وAmazon وMicrosoft وApple بين أبرز الجهات التي توظف علماء البيانات، كما يزداد الإقبال على هذا المجال بين العاملين في قطاع تكنولوجيا المعلومات.
استنادًا إلى تقرير حديث من شركة Precedence Research، يتوقع أن ينمو الطلب على علم البيانات بمعدل نمو سنوي مركب بنسبة 16.43%، ليصل إلى قيمة سوقية تُقدر بـ676.51 مليار دولار أمريكي بحلول عام 2034.
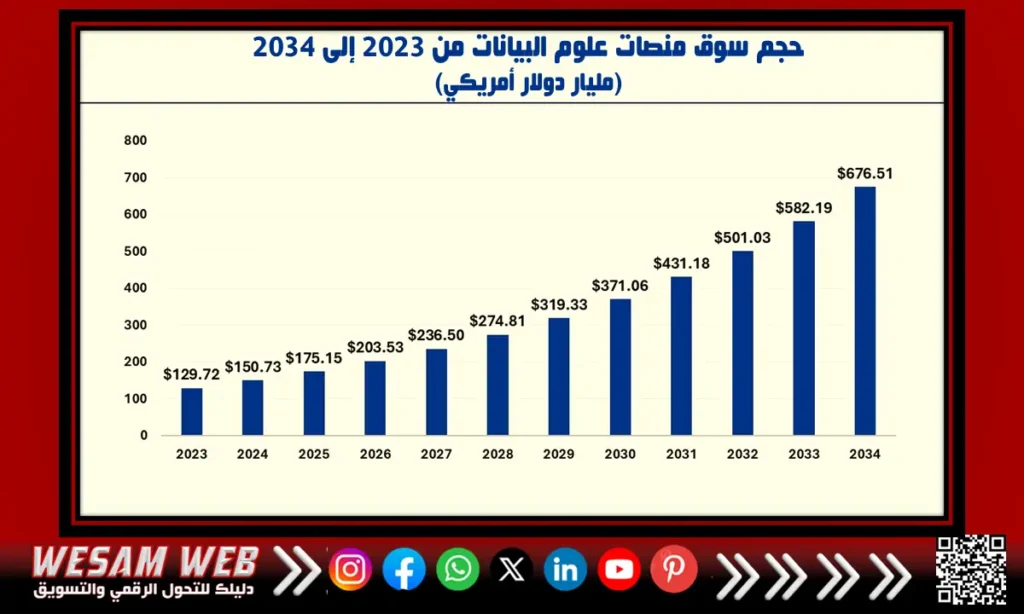
باختصار، يمثل علم البيانات فنًا وعلمًا يقوم على استخراج المعلومات القيمة من البيانات الخام باستخدام أساليب وخوارزميات متطورة، مما يضفي عليه طابعًا إبداعيًا وعلميًا في الوقت ذاته.
التطور التاريخي لمجال علم البيانات
إليك جدول شامل يوضح التطور التاريخي لمجال علوم البيانات:
| السنة | الحدث الرئيسي |
|---|---|
| 1962 | ناقش جون توكي دمج الإحصاء مع الحواسيب لتوفير نتائج كمية سريعة. |
| 1974 | أشار بيتر نور في كتابه "مسح موجز لأساليب الحاسوب" إلى مصطلح "علم البيانات". |
| 1977 | تأسست الجمعية الدولية للحوسبة الإحصائية (IASC) لدمج تكنولوجيا الحاسوب المتقدمة مع الأساليب الإحصائية التقليدية. وفي نفس العام، كتب جون توكي ورقة بحثية بعنوان "تحليل البيانات الاستكشافي". |
| 1994 | بدأت الشركات في جمع كميات كبيرة من البيانات الفردية لتحضير حملات إعلانية. |
| 1999 | جاكوب زهافي سلط الضوء على الحاجة لتطوير تقنيات جديدة لإدارة الكميات الكبيرة من البيانات التنظيمية. |
| 2001 | وضع ويليام إس كليفلاند خطة عمل لتطوير فهم متخصص لعلماء البيانات، مع التركيز على ستة مجالات دراسية. |
| 2002 | إنشاء مجلة علوم البيانات من قبل المجلس الدولي للعلوم، لمناقشة صياغة وتنفيذ أنظمة البيانات. |
| 2003 | أطلقت جامعة كولومبيا مجلة علوم البيانات كمنتدى مخصص لفرق البيانات. |
| 2005 | نشر المجلس الوطني للعلوم مجموعة جديدة من معايير الذكاء الرقمي. |
| 2013 | أشارت شركة IBM إلى أن 90٪ من بيانات العالم تم إنتاجها في العامين الماضيين. |
| 2024 | أصبح علم البيانات مجالًا محوريًا في التكنولوجيا الحديثة، حيث يتم استخدامه لتحليل البيانات الضخمة واستخلاص رؤى استراتيجية، مع ازدياد الطلب العالمي على علماء البيانات لتلبية احتياجات الشركات المتنامية في تحويل البيانات إلى معلومات قابلة للتنفيذ. |
الفرق بين علم البيانات وعالم البيانات
يعتبر علم البيانات تخصصًا، وعلماء البيانات هم ممارسون في هذا المجال. لا يتحمل علماء البيانات دائمًا المسؤولية المباشرة عن جميع الأنشطة المشاركة في دورة حياة الـ Data Science. على سبيل المثال، تتم إدارة خطوط أنابيب البيانات عادةً بواسطة مهندسي البيانات؛ ومع ذلك، قد يقدم عالم البيانات توصيات حول نوع البيانات ذات الصلة أو الضرورية.
في حين يمكن لعلماء البيانات إنشاء نماذج التعلم الآلي، فإن توسيع هذه الجهود إلى نطاق أوسع يتطلب خبرة أكبر في هندسة البرمجيات من أجل تحسين البرنامج للعمل بشكل أسرع. ونتيجة لذلك، من المعتاد أن يتعاون عالم البيانات مع مهندسي التعلم الآلي أثناء توسيع نماذج التعلم الآلي.
تتداخل مهام عالم البيانات ومحلل البيانات بشكل متكرر، وخاصة فيما يتعلق بتحليل البيانات الاستكشافي وتصور البيانات. من ناحية أخرى، غالبًا ما يكون لدى عالم البيانات مجموعة مهارات أكبر من محلل البيانات العادي. يستخدم علماء البيانات لغات البرمجة السائدة مثل R وPython للقيام بالاستدلال الإحصائي وتصور البيانات.
لإكمال هذه المسؤوليات، يجب أن يتمتع علماء البيانات بعلوم الكمبيوتر والقدرات العلمية البحتة التي تتجاوز قدرات محلل الأعمال العادي أو محلل البيانات. يجب على عالم البيانات أيضًا أن يفهم خصوصيات الصناعة، مثل إنتاج السيارات، أو التجارة الإلكترونية، أو الرعاية الصحية.
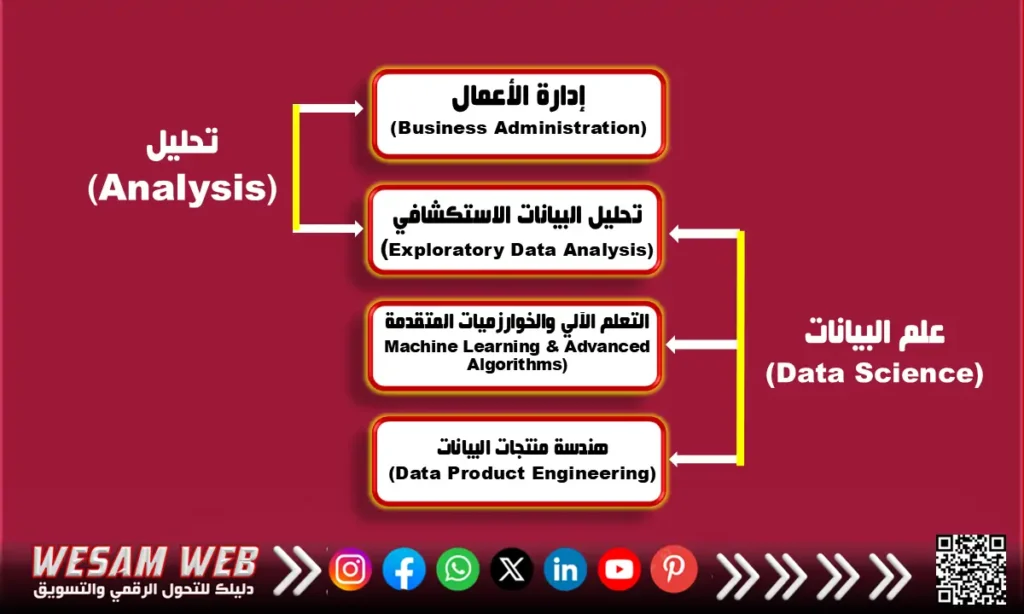
كما هو موضح في الصورة أعلاه، غالبًا ما يصف محلل البيانات ما يحدث عند معالجتها. من ناحية أخرى، يتجاوز عالم البيانات حدوده من خلال التنبؤ بإمكانية حدوث أحداث مستقبلية باستخدام تقنيات الذكاء الاصطناعي والتعلم الآلي واستخراج البيانات وذكاء الأعمال.
أخيرًا، يفحص عالم البيانات المعلومات من مجموعة متنوعة من الزوايا، بما في ذلك وجهات النظر الجديدة. ونتيجة لذلك، يركز المجال على تحليل كميات هائلة من البيانات لفهم كيفية عمل الأنظمة بشكل أفضل، يليه التحليلات والأحكام والتنبؤات القائمة على التعلم الآلي.
ما هي المهارات والأدوار التي يجب أن يتعلمها عالم البيانات؟
هذه المهارات والأدوات مطلوبة بشدة، ونتيجة لذلك، فإن العديد من الأشخاص الذين يريدون دخول مهنة علوم البيانات يستكشفون مجموعة متنوعة من برامجها، مثل برامج الشهادات، ودورات علوم البيانات، وبرامج الدرجات العلمية التي تقدمها المؤسسات التعليمية.
دور عالم البيانات
نظرًا لسرعة التغيير وحجم البيانات المتاحة في بيئة الشركات اليوم، يلعب علماء البيانات دورًا مهمًا في مساعدة الشركة على تحقيق أهدافها. يجب على عالم البيانات الحديث القيام بما يلي:
- تصميم وإدارة أنظمة ومستودعات تكامل البيانات.
- التعاون مع أصحاب المصلحة في الشركة لإنشاء سياسات حوكمة البيانات وتعزيز تكامل البيانات وإدارتها وأنظمتها.
- إنهم يدركون تمامًا موقف شركتهم أو مؤسستهم في السوق.
- استخدام تقنيات الاستخبارات التجارية أو تحليلات البيانات لدراسة واستكشاف كميات هائلة من البيانات المنظمة وغير المنظمة.
- إنشاء نماذج وخوارزميات تحليلية باستخدام SQL أو R أو Python، واستخدام مناهج علوم البيانات مثل التعلم الآلي والنمذجة الإحصائية والذكاء الاصطناعي.
- اختبار واختبار وتحسين هذه النماذج في نظام تحليلي أو دعم القرار للحصول على رؤى الأعمال المطلوبة.
- نقل الاتجاهات والأنماط والتوقعات والرؤى بفعالية إلى جميع أصحاب المصلحة باستخدام الاتصال اللفظي والتقارير المكتوبة وتصور البيانات.
مهارات عالم البيانات
- يمكن لعالم البيانات المثالي التعامل مع القضايا المعقدة للغاية لأنه يمكنه القيام بما يلي:
- المساعدة في إنشاء الأهداف وتقييم النتائج باستخدام خبرة مجال الأعمال.
- إدارة وتحسين البنية الأساسية للبيانات في المؤسسة.
- استخدام لغات البرمجة المعمول بها والأساليب الإحصائية وأدوات البرمجيات.
- امتلاك الفضول للتحقيق في الاتجاهات والأنماط في البيانات وتحديدها.
- التواصل والتعاون بنجاح عبر المؤسسة.
عملية علم البيانات

إذا كنت تفكر في أن تصبح عالم بيانات وتتساءل “ماذا يفعل عالم البيانات؟”، فإليك المراحل الـ 7 الرئيسية لعملية علم البيانات:
1. تحديد المشكلة
البداية هي فهم المشكلة أو التحدي الذي يحتاج إلى حل. تتطلب هذه المرحلة تحديد الهدف الأساسي للمشروع وتحديد الأسئلة التي تحتاج إلى إجابة. يتم استخدام التعاون بين الفرق متعددة التخصصات لتوضيح النطاق والأهداف المحددة لضمان التوافق الكامل مع الاحتياجات التشغيلية.
2. جمع البيانات
بعد تحديد المشكلة، تأتي مرحلة جمع البيانات ذات الصلة. يتم البحث عن مصادر البيانات المتاحة، سواء كانت داخلية أو خارجية، منظمة أو غير منظمة. تعتمد فعالية التحليل النهائي إلى حد كبير على جودة وكمية البيانات التي تم جمعها. فيما يلي بعض الطرق الأكثر شيوعًا لجمع البيانات:
- الاستطلاعات
- مجموعات التركيز
- مقابلات العملاء
- مراقبة وسائل التواصل الاجتماعي
- المراقبة عبر الإنترنت
- استخراج البيانات من الويب
- التحليلات للتسويق عبر الإنترنت
- جمع معلومات الاشتراك
- البحث باستخدام الأرشيفات
- مراقبة المعاملات
- مراجعة المستندات
- ملاحظة
3. معالجة البيانات
تنطوي هذه المرحلة على تنظيف البيانات من الأخطاء أو القيم المفقودة وإعدادها للاستخدام. يتم تطبيق تقنيات مختلفة لتحسين جودة البيانات وضمان توفرها بشكل كافٍ للتحليل اللاحق. هذه الخطوة بالغة الأهمية، حيث تؤثر جودة البيانات بشكل مباشر على دقة النتائج. يمكن القيام بذلك يدويًا أو عن طريق إنشاء التعليمات البرمجية، وقد يشمل بعض ما يلي:
- هندسة البيانات
- دمج مجموعات البيانات
- تنظيف البيانات
- إزالة عدم الدقة والقيم المفقودة
- تحويل المعلومات إلى تنسيق جديد
4. استكشاف البيانات
في هذه المرحلة، يبدأ المحللون في استكشاف البيانات من خلال تقنيات مختلفة مثل التصور والإحصاءات الوصفية. الهدف هو فهم الأنماط والعلاقات بين المتغيرات وتحديد المؤشرات المبكرة التي يمكن أن تؤدي إلى رؤى أعمق.
5. التحليل
تتضمن هذه الخطوة تطبيق تقنيات تحليلية متقدمة، مثل التحليل الإحصائي والخوارزميات الذكية. يسعى المحللون إلى استخراج رؤى قيمة من البيانات التي تساعد في تحقيق أهداف المشروع، والتي قد تتطلب استخدام أدوات تحليلية متقدمة وبرامج متخصصة.
6. نمذجة البيانات
في هذه المرحلة، يتم بناء نماذج تنبؤية أو توضيحية باستخدام تقنيات مثل التعلم الآلي أو النماذج الإحصائية. والهدف هو استخدام البيانات لإنشاء نماذج يمكنها تقديم تنبؤات دقيقة أو فهم أعمق للمشكلة قيد الدراسة.
7. التواصل
تتضمن المرحلة النهائية تقديم النتائج والرؤى لأصحاب العمل. يتم ذلك من خلال تقارير وعروض تقديمية مفصلة تشرح النتائج بلغة واضحة ومفهومة، مما يسمح لصناع القرار باتخاذ قرارات مستنيرة بناءً على البيانات.
كل مرحلة من مراحل دورة حياة علم البيانات حيوية لنجاح المشاريع المختلفة، مما يساهم في تحويل البيانات الخام إلى معلومات قيمة تدعم اتخاذ القرارات الاستراتيجية.
مثال على دورة حياة علم البيانات: خطوات متكاملة لتحقيق رؤى دقيقة
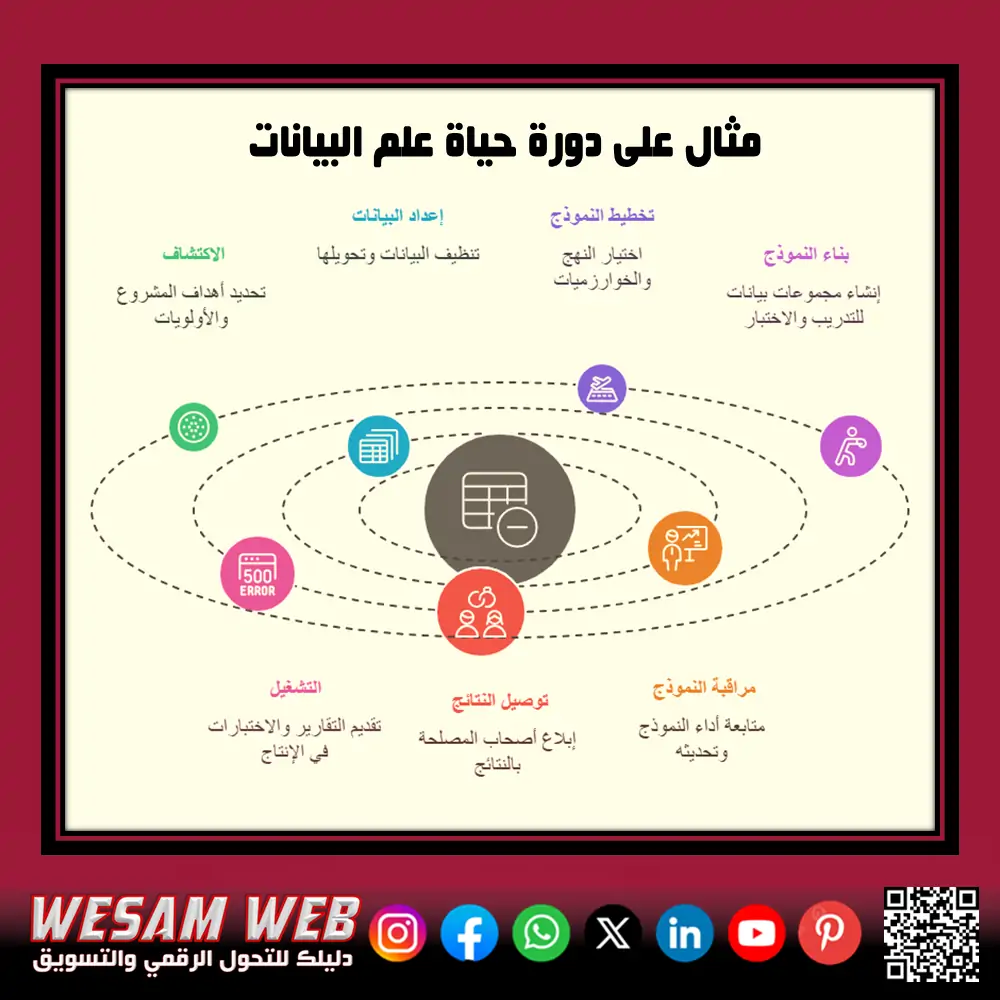
في هذا المثال، سنتناول خطوات دورة حياة علم البيانات، من تحديد المشكلة إلى مراقبة النموذج، لمزيد من التوضيح:
الخطوة 1 – الاكتشاف (Discovery)
قبل الشروع في أي مشروع، من الضروري تحديد أهداف المشروع وأولوياته بوضوح. وهذا يتطلب القدرة على طرح الأسئلة الصحيحة وفهم نطاق المشكلة. من المهم أيضًا التأكد من توفر الموارد الأساسية، مثل الموارد البشرية والتكنولوجيا المتقدمة والوقت الكافي والبيانات الشاملة. يساعد هذا التحضير في وضع أساس قوي للنجاح.
الخطوة 2 – إعداد البيانات (Data Preparation)
تبدأ هذه المرحلة بفحص البيانات وأداء مهام المعالجة الأساسية. تتضمن هذه الخطوة استخراج البيانات وتحويلها وتحميلها (ETL) لإعدادها للتحليل. تُستخدم أدوات مثل R لتنظيف وتصور واكتشاف الشذوذ، مما يساعد في إنشاء روابط بين المتغيرات المختلفة.
الخطوة 3 – تخطيط النموذج (Model Planning)
في هذه المرحلة، يتم اختيار النهج والخوارزميات المناسبة لبناء النموذج. يعتمد تحليل البيانات الاستكشافي (EDA) على العديد من الأساليب الإحصائية وأدوات التصور، كما تشمل الأدوات الشائعة المستخدمة في هذه المرحلة SQL وR وSAS/ACCESS، والتي توفر بيئة مثالية لبناء نماذج توضيحية.
الخطوة 4 – بناء النموذج (Model Building)
تتضمن هذه الخطوة إنشاء مجموعات بيانات لتدريب النموذج واختباره. من المهم التحقق من كفاءة الأدوات الحالية لتشغيل النموذج أو البحث عن بيئة أكثر قوة إذا لزم الأمر. تُستخدم تقنيات التعلم مثل التصنيف والتجميع والارتباط لبناء النموذج باستخدام أدوات مثل SAS Enterprise Miner وWEKA.
الخطوة 5 – التشغيل (Operationalize)
خلال هذه المرحلة، يتم توفير التقارير النهائية والعروض التقديمية والرمز والوثائق الفنية، وفي بعض الأحيان يتم تشغيل مشروع اختبار في نظام إنتاج فعلي لتقييم الأداء والقيود المحتملة قبل التنفيذ الكامل.
الخطوة 6 – توصيل النتائج (Communicate Results)
من الضروري تقييم مدى تحقيق الأهداف الأساسية وتحديد النتائج الرئيسية. يتم إبلاغ أصحاب المصلحة لضمان فهم واضح للنتائج وضمان نجاح المشروع وفقًا للمعايير المحددة مسبقًا.
الخطوة 7 – مراقبة النموذج (Monitoring Model)
لا ينتهي العمل بمجرد بناء النموذج؛ بل يجب مراقبة أدائه بمرور الوقت، وقد يلزم تحديث البيانات المستخدمة لتدريب النموذج باستمرار لضمان دقة التوقعات المستقبلية، وهذا أمر حيوي بشكل خاص في المجالات الديناميكية مثل اكتشاف الاحتيال.
تشكل هذه المراحل المتكاملة دورة حياة علم البيانات، مما يساعد في تحويل البيانات الخام إلى رؤى قابلة للتنفيذ تدعم اتخاذ القرارات الاستراتيجية.
ما هي أنواع علم البيانات ولماذا هي مهمة؟
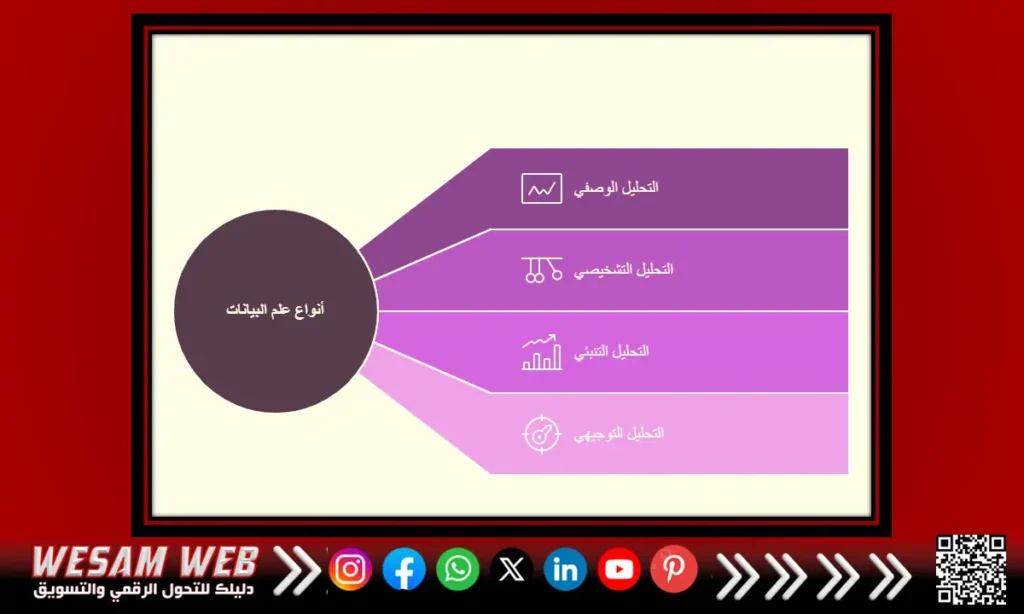
يستخدم علم البيانات في أبحاث البيانات بأربع طرق رئيسية، ولكل منها استخداماتها وفوائدها:
التحليل الوصفي (Descriptive Analysis)
في التحليل الوصفي، يتم فحص البيانات لتحديد الأحداث التي أثرت على البيانات أو تتحكم فيها حاليًا. الميزة الأبرز لهذا النهج هي استخدام مجموعة متنوعة من أدوات تصور البيانات، مثل المخططات الدائرية والرسوم البيانية الشريطية والرسوم البيانية الخطية والجداول.
على سبيل المثال، تخزن الشركة التي تعمل في مجال سجلات حجز الرحلات الجوية الكثير من المعلومات حول التذاكر كل يوم، وباستخدام التحليل الوصفي، من الممكن تحديد النمو والانخفاض المفاجئ في مبيعات التذاكر ومعرفة الأشهر الأكثر إنتاجية في السنة.
التحليل التشخيصي (Diagnostic Analysis)
في هذا النوع من التحليل، نتعمق في البيانات التفصيلية لاكتشاف سبب حدوث شيء ما. يتم استخدام تقنيات مختلفة، مثل اكتشاف البيانات واستخراج البيانات والارتباطات، ومن الممكن أن تخضع البيانات لعمليات وتحويلات مختلفة للعثور على أنماط جديدة في كل تقنية.
على سبيل المثال، يمكن لخدمة التذاكر لدينا التعمق في الأشهر الأكثر ربحية وتحديد الأسباب الدقيقة لزيادة المبيعات. على سبيل المثال، ربما في شهر معين من العام، يذهب الناس إلى مدينة معينة لمشاهدة حدث رياضي عن قرب.
التحليل التنبئي (Predictive Analysis)
في هذا التحليل، توفر البيانات التاريخية تنبؤات دقيقة حول الأنماط التي من المرجح أن تتكرر في المستقبل. التعلم الآلي والتنبؤ ومطابقة الأنماط والنماذج التنبؤية هي المكونات الأكثر بروزًا لهذا النوع من التحليل. في كل من هذه التقنيات، يتعلم الكمبيوتر كيفية هندسة السببية العكسية من العلاقات.
يمكن لشركة تخطيط الأحداث استخدام علم البيانات للتنبؤ بأنماط شراء التذاكر للعام المقبل. تنظر الخوارزمية إلى البيانات السابقة، على سبيل المثال، وتتوقع زيادة مبيعات التذاكر في مايو لمدينة معينة. لذلك، يمكن إطلاق إعلانات مستهدفة في أبريل وترحيب العملاء بها.
التحليل التوجيهي (Prescriptive Analysis)
يأخذ هذا النوع من التحليل التوجيهي التحليلات التنبؤية إلى المستوى التالي. لذلك، لا يتم التنبؤ بالأحداث المحتملة فحسب، بل يتم أيضًا توفير الاستجابة المثلى لكل نتيجة. يتم فحص عواقب الخيارات المختلفة، ويتم تقديم أفضل نهج ممكن.
في التحليل التوجيهي، يتم استخدام تحليل الرسم البياني، والمحاكاة، ومعالجة الأحداث المعقدة، والشبكات العصبية، ومحركات التوصية بالتعلم الآلي. على سبيل المثال، يمكن لشركة بيع التذاكر مراجعة البيانات من الحملات الإعلانية السابقة للتحقق من النتائج المحتملة للحملات المستقبلية في قنوات الاتصال المختلفة. باستخدام هذه البيانات، تتخذ الشركة قرارات أكثر استنارة وفعالية.
أهمية علم البيانات
في بيئة اليوم، يُنظر إلى إنشاء البيانات والاستفادة منها على أنها نشاط اقتصادي بالغ الأهمية. يساعد علم البيانات الشركات على تحليل كميات هائلة من البيانات بكفاءة من مصادر متعددة والاستفادة من الأفكار المكتسبة من أبحاثها لاتخاذ قرارات مستنيرة بناءً على تلك البيانات.
قد تستخدم الشركات علوم البيانات لتقييم أدائها واتخاذ قرارات أفضل في المستقبل، وقد تتخذ أحكامًا أفضل من خلال الاستفادة من تحليلات البيانات لتحسين مشاركة المستهلك والأداء التنظيمي والربحية. يستخدم Data Science على نطاق واسع في مجموعة متنوعة من المجالات، بما في ذلك التسويق والرعاية الصحية والتمويل والخدمات المصرفية والسياسة.
كما ذكرنا سابقًا، يستخدم علم البيانات على نطاق واسع في مجموعة متنوعة من الصناعات. دعنا نلقي نظرة على بعض تطبيقاته لمعرفة المزيد.
ما هي تطبيقات علم البيانات؟
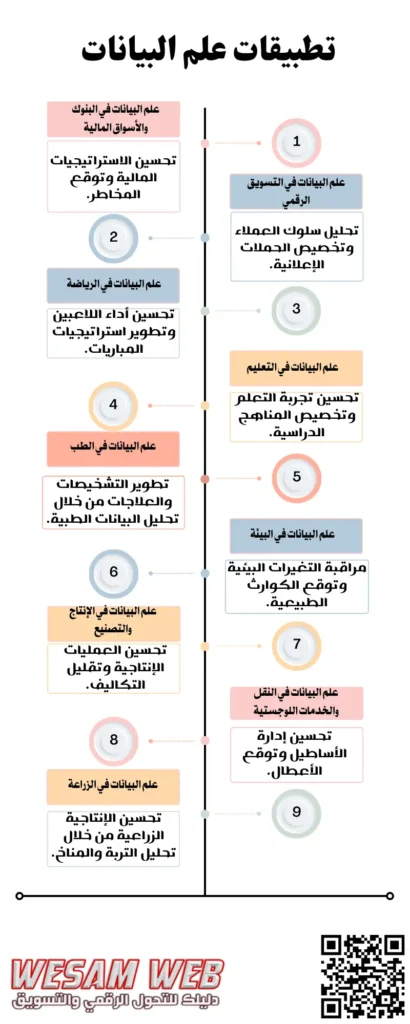
يمكن للعديد من الصناعات التي يتم فيها جمع كميات هائلة من البيانات الاستفادة من خوارزميات علم البيانات، بما في ذلك التمويل والأعمال والتسويق وإدارة المشاريع والتأمين والطب والتعليم والتصنيع والموارد البشرية واللغويات وعلم الاجتماع وما إلى ذلك.
يمكن أن تستفيد كل شركة تقريبًا تستخدم تلك التقنية بشكل كبير من جمع المعلومات وتحليلها ونمذجتها. فيما يلي بعض الاستخدامات العملية لعلم البيانات.
علم البيانات في البنوك والأسواق المالية
تعتمد المؤسسات المصرفية على علم البيانات أكثر من أي وقت مضى لتكون قادرة على المنافسة. ونتيجة لذلك، أصبح تبني Data Science في البنوك أمرًا ضروريًا.
يمكن للبنوك الاستفادة من التركيز على تكنولوجيا البيانات الضخمة بعدة طرق، بما في ذلك اتخاذ قرارات أفضل، وتخصيص الموارد بكفاءة أكبر، وتحسين الأداء. ومع ذلك، لفهم الاستخدام الفعال والناجح لعلوم البيانات في الخدمات المصرفية، يلزم الحصول على تعليم بدوام كامل في Data Science.
من الجدير بالذكر أن التعلم الآلي وعلوم البيانات وفرا على الصناعة المالية ملايين الدولارات. وبفضل الداتا ساينس، يمكن الآن إكمال مهمة كانت تستغرق مئات الآلاف من ساعات العمل اليدوي في غضون ساعات. بالإضافة إلى ذلك، تستثمر الشركات المالية مثل PayPal حاليًا في علم البيانات لتطوير أدوات التعلم الآلي التي يمكنها التعرف بسرعة على الأنشطة الاحتيالية ومنعها.
علم البيانات في التسويق الرقمي
يشير التسويق الرقمي إلى أي أنشطة عبر الإنترنت تهدف إلى الترويج لعلامة تجارية، والتي قد تكون شخصًا أو شركة أو منتجات أو خدمات. الآن، هناك العديد من جوانب التسويق الرقمي، مثل إدارة وسائل التواصل الاجتماعي وتحسين محركات البحث والتسويق عبر البريد الإلكتروني وتسويق المحتوى.
يمكن الآن تطبيق علم البيانات لتحسين ممارسات التسويق الرقمي. فيما يلي بعض الطرق التي قد يساعد بها في التسويق الرقمي:
- يستخدم التسويق الرقمي رؤى علم البيانات لاختيار القناة الرقمية المناسبة للهدف. يساعد هذا في الوصول إلى الجمهور المناسب.
- كما يساعدك على معرفة ما يريده جمهورك المستهدف. من خلال هذا، يمكنك إنشاء تكتيكات تسويقية تساعدك على تلبية هذه المطالب.
- يمنح أيضا العاملين في التسويق بالعمولة نظرة ثاقبة حول تنسيق المحتوى المناسب. كما يساعد المؤسسات على معرفة متى تنشر، وكيفية زيادة تفاعل العملاء، والمزيد.
علم البيانات في الرياضة
هناك العديد من الإحصائيات والتوقعات في قطاع الرياضة. حاليًا، يحاول العديد من الأفراد توقع نتيجة حدث رياضي من خلال مراعاة مجموعة متنوعة من العناصر والحقائق، وغالبًا ما تكون هذه التوقعات صحيحة. ومع ذلك، فإن هذا يتوقف على دقة المعلومات المستخدمة في التنبؤ. هذا مجال حاسم في الرياضة حيث يتم تطبيق علم البيانات.
- في الرياضة، تساعد رؤى علم البيانات في التنبؤ بنتيجة المباراة، حيث يتم تضمين البيانات التي تم جمعها حول نقاط القوة والضعف لدى اللاعبين والأداء السابق وما إلى ذلك.
- بالإضافة إلى ذلك، يستخدم أصحاب العمل الداتا ساينس لاتخاذ قرارات اختيار اللاعبين. وذلك لتحديد ما إذا كان اللاعب سيكون أصلًا رائعًا للفريق. يستخدمون علوم البيانات لجمع وتحليل البيانات حول أداء اللاعب السابق والصحة الحالية والمستقبلية والملاءمة الفردية للفريق والمزيد.
- يستخدم المدربون أيضًا علم البيانات للحصول على معلومات حول كيفية تدريب اللاعبين لتحقيق الأداء الأمثل.
علم البيانات في التعليم
التعليم هو أساس كل مجتمع وعملية نقل المعرفة للآخرين. يستخدم مجال التعليم علم البيانات بالطرق التالية:
- يستخدم خبراء التعليم علم البيانات لتحسين التعلم ومساعدة كل طالب على التعلم بطريقته الفريدة. في الواقع، يقومون بتخصيص التعلم بطريقة ما.
- كما يساعد في تقييم أساليب التدريس للمعلمين للمساعدة في تحسين نقاط القوة والضعف في هذه الأساليب التعليمية.
- وعلاوة على ذلك، يزود التعليم الناس بالمعرفة لحل مشاكل العالم الحقيقي، ونظرًا لأن الاتجاهات المختلفة تظهر في العالم في أوقات مختلفة، فمن المهم تحديث المناهج الدراسية بانتظام. للقيام بذلك، يستخدم الخبراء رؤى علم البيانات للتنبؤ بالاتجاهات المستقبلية وتعزيز المناهج التعليمية لتناسب هذه الاتجاهات.
علم البيانات في الطب
الرعاية الصحية هي واحدة من أهم مجالات المجتمع، ويستخدم علم البيانات على نطاق واسع لمعالجة التحديات في العالم الحقيقي. يقدم علم البيانات في الرعاية الصحية رؤى قابلة للتنفيذ تساعد في الوقاية من المرض والوفاة.
- يستخدم الخبراء رؤى العلم لمراقبة ومنع المشاكل الصحية. يتم ذلك من خلال جمع البيانات حول أنماط النوم ومستويات السكر في الدم ونشاط الدماغ والمزيد. بعد ذلك، يقوم المتخصصون بتحليل البيانات للتحقق من التغييرات واكتشاف الاضطرابات أو المشاكل الصحية المحتملة.
- كما يساعد في تحسين دقة التشخيص. يساعد Data Science في بناء خوارزميات التعلم التي يمكنها قراءة وتحليل بيانات التصوير. بعد ذلك، يقارنون النتائج المقدمة بقاعدة بيانات موجودة من التقارير السريرية.
- يمكن العثور على علاجات للأمراض القاتلة مثل السرطان والإيبولا وكوفيد-19 وما إلى ذلك باستخدام رؤى من علم البيانات.
علم البيانات في البيئة
يساهم علم البيانات بشكل كبير في حماية البيئة. في الواقع، يعد علم بيانات الأرض موضوعًا لعلم البيانات. يطبق الخبراء في هذا الموضوع مناهج للتحقيق في ديناميكيات الأرض ومعالجة القضايا البيئية.
- يساعد Data Science في التنبؤ بدقة بتغير المناخ والأحداث الجوية المتطرفة وما إلى ذلك.
- يتنبأ أيضًا بحدوث الكوارث الطبيعية والحوادث في البيئة.
علم البيانات في الإنتاج والتصنيع
التصنيع هو عملية تحويل المواد الخام إلى سلع أو سلع مكتملة، باستخدام الموظفين والآلات والمعدات الأخرى لتكرير الموارد الخام. فيما يلي بعض تطبيقات علم البيانات في هذا المجال:
- في صناعة التصنيع، نستخدم رؤى تحليلات البيانات لمراقبة الآلات والمعدات في الوقت الفعلي. هذا العمل لمنع تعطل الآلات واكتشاف الأسباب المحتملة لتعطلها في المستقبل.
- يمكن ل Data Science أيضًا توفير نظرة ثاقبة لأفضل المعدات وأكثرها فعالية من حيث التكلفة والتي يمكن لمصنعي المعدات شراؤها، مما يساعد في دفع عائد الاستثمار.
- كما يساعد علم البيانات في التنبؤ بتغيرات السوق، مما يسمح للمصنعين باتخاذ قرارات تصنيع حاسمة تتناسب مع احتياجات السوق.
علم البيانات في النقل والخدمات اللوجستية
يتعلق النقل والخدمات اللوجستية بنقل الأشخاص والحيوانات والبضائع وما إلى ذلك من مكان إلى آخر ويقدر قطاع النقل والخدمات اللوجستية علم البيانات كثيرًا. في الماضي، اعتمدت صناعة الشحن والخدمات اللوجستية فقط على العمليات اليدوية لإنجاز الأمور، مما يؤدي إلى الهدر وتأخير الإنتاجية وعدم رضا العملاء. حاليًا، يمكن لعلم البيانات حل هذه المشكلات:
- يلبي علم البيانات رغبات الناس بناءً على اتجاهات السوق والتنبؤات الأخيرة.
- بالإضافة إلى ذلك، تستخدم صناعة النقل والخدمات اللوجستية رؤى Data Science لتقدير وتوقع أوقات الوصول والمغادرة.
- يستخدم الخبراء علم البيانات لتحديد أقصر طريق ممكن إلى موقع يتجنب إهدار الوقت والطاقة.
- يستخدم الخبراء رؤى من خلاله لإجراء تقييمات المخاطر والتنبؤ بالاضطرابات في صناعة النقل. كما يتم استخدامه لإبلاغ أصحاب المصلحة المعنيين بأي مشاكل تواجههم في مرافق النقل الخاصة بهم.
علم البيانات في الزراعة
الزراعة مجال مهم للغاية في عالم اليوم. لقد كانت وستظل كذلك منذ بداية العالم. تشمل الزراعة إنتاج أنواع مختلفة من المحاصيل وتربية الحيوانات للاستخدام البشري والصناعي. الآن، يستخدم مجال الزراعة علم البيانات بالطرق التالية:
- يستخدم الخبراء علم البيانات لمكافحة نقص الغذاء. يتم هذا العمل من خلال تحليل البيانات ذات الصلة التي توفر رؤى قابلة للتنفيذ حول كيفية مكافحة نقص الغذاء في العالم.
- يمنح Data Science المزارعين أيضًا نظرة ثاقبة حول أنواع وكميات آفات المحاصيل والأمراض التي تؤثر على محاصيلهم.
- علم البيانات مفيد أيضًا في القطاع الزراعي لمساعدة المزارعين على التكيف مع تغير المناخ. سيساعدهم هذا في التخطيط لدورة الزراعة الخاصة بهم وفقًا للتنبؤات التي قدمتها طرق الداتا ساينس المختلفة.
- يمكن أيضًا استخدام علم البيانات للتنبؤ بالعائدات. يساعد هذا المزارعين على معرفة ما يمكن توقعه قبل وقت الحصاد.
بعض المفاهيم الإحصائية اللازمة لعلم البيانات
إن الإحصاء وعلوم البيانات مرتبطان بطريقة ما. بعبارة أخرى، تعمل الإحصاء كأساس لعلم البيانات. ونتيجة لذلك، يجب على الشخص الذي ينوي العمل في هذه المهنة أن يتقن أولاً بعض الإحصاءات الأساسية. في هذا القسم، سنقدم بعضًا من أكثر المفاهيم الإحصائية شهرة في Data Science.
المتغيرات العشوائية (Random Variables)
إن فكرة المتغيرات العشوائية هي أساس العديد من المفاهيم الإحصائية. قد يكون من الصعب فهم تفسيرها الرياضي الدقيق، ولكن ببساطة، فإن المتغير العشوائي هو طريقة لرسم مخرجات العمليات العشوائية، مثل رمي العملة المعدنية أو رمي النرد، إلى أرقام. على سبيل المثال، قد نعبر عن العملية العشوائية لرمي العملة المعدنية باستخدام متغير عشوائي X، والذي يأخذ القيمة 1 إذا كانت النتيجة ذيلًا و0 إذا كانت النتيجة خطًا.

في هذا المثال، لدينا عملية عشوائية لرمي العملة المعدنية، والتي يمكن أن تؤدي إلى نتيجتين مختلفتين: {0،1}. تشير مساحة العينة الاختبارية إلى جميع النتائج التي يمكن تصورها. يتم تعريف الحدث على أنه عندما تتكرر عملية عشوائية. إن رمي العملة المعدنية واستلام خط هو مثال على نتيجة حدث ما. ويشار إلى إمكانية حدوث هذا الحدث بنتيجة محددة باسم احتمالية الحدث. واحتمالية وقوع حدث ما هي احتمالية أن يأخذ متغير عشوائي قيمة معينة من x، والتي يمكن تمثيلها على أنها P(x). وفي مثال رمي العملة المعدنية، تكون فرصة ظهور الكتابة أو الخطوط متساوية، أي 0.5 أو 50%. لذا لدينا:

المتوسط والتباين والانحراف المعياري
يتطلب فهم مفاهيم المتوسط والتباين والعديد من القضايا الإحصائية الأخرى معرفة السكان والعينة. السكان عبارة عن مجموعة من جميع الملاحظات (الأشخاص أو الأشياء أو الأحداث أو الإجراءات) التي غالبًا ما تكون واسعة جدًا ومتنوعة، في حين أن العينة عبارة عن مجموعة مختارة من الملاحظات من السكان والتي يُقصد منها أن تكون انعكاسًا حقيقيًا للسكان.
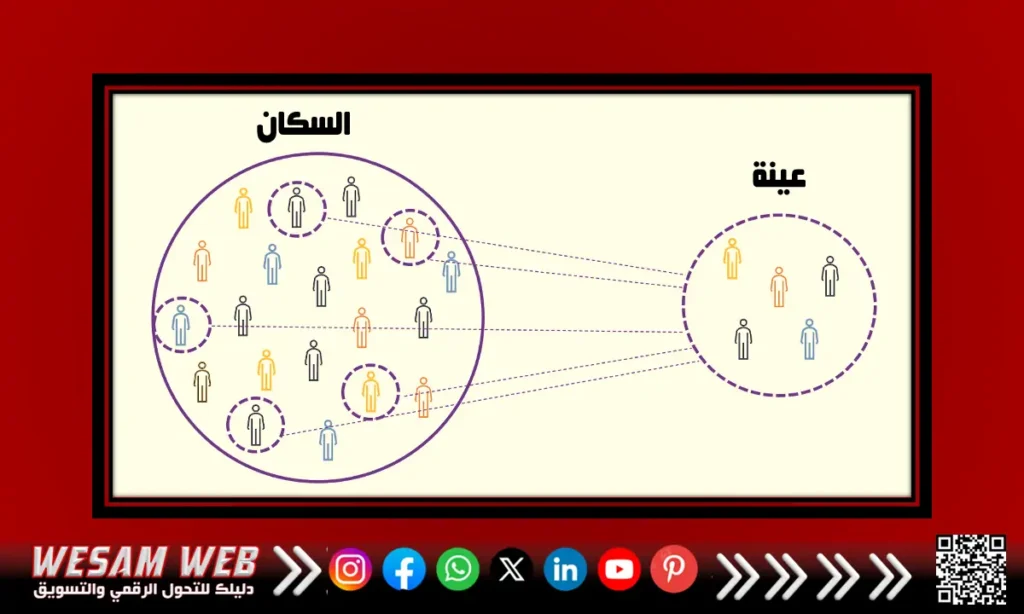
نظرًا لأن تقييم السكان بالكامل غير عملي أو مكلف للغاية، فإن الباحثين والمحللين يجرون دراسات على العينات بدلاً من السكان بالكامل. لضمان أن تكون نتائج الاختبار جديرة بالثقة وذات صلة بالسكان بالكامل، يجب أن تكون العينة ممثلة حقًا. أي يجب أن تكون العينة محايدة. تعد العينات العشوائية والعينات المنتظمة والعينات المجمعة والعينات المرجحة والعينات الطبقية كلها مناسبة لهذا الغرض.
المتوسط (Mean)
يُعرف المتوسط أيضًا باسم الوسيط، وهو نقطة المنتصف لمجموعة محدودة من الأعداد الصحيحة. افترض أن المتغير العشوائي X في البيانات له القيم التالية:

حيث N هو عدد الملاحظات أو نقاط البيانات في مجموعة العينة، والمعروفة غالبًا باسم تردد البيانات. يُستخدم متوسط العينة (μ) عادةً لتقريب متوسط المجتمع. ويمكن تمثيله على النحو التالي:

التباين (Variance)
التباين هو مقياس لمسافة نقاط البيانات عن القيمة المتوسطة، ويتم حسابه كمجموع الانحرافات التربيعية بين قيم البيانات والمتوسط. علاوة على ذلك، يمكن صياغة تباين السكان على النحو التالي:

الانحراف المعياري
الانحراف المعياري هو مجرد الجذر التربيعي للتباين، ويمثل مدى انحراف البيانات عن المتوسط. يمكن صياغة الانحراف المعياري لسيجما على النحو التالي:

التغاير (Covariance)
التغاير هو مقياس يوضح التغير المشترك لمتغيرين عشوائيين ويوضح العلاقة بينهما. يتم تعريفه على أنه القيمة المتوقعة لحاصل ضرب انحرافات متغيرين عشوائيين عن المتوسط. يتم تمثيل التغاير بين متغيرين عشوائيين X وZ بالتعبير التالي، حيث E(X) وE(Z) هما متوسطي X وZ على التوالي.

يمكن أن يكون التغاير سلبيًا أو موجبًا أو صفرًا. تشير قيمة التغاير الموجبة إلى أن متغيرين عشوائيين يتحركان في نفس الاتجاه، بينما تشير القيمة السالبة إلى أن نفس المتغيرات تختلف في اتجاهين متعاكسين. أخيرًا، يشير الرقم 0 إلى عدم اختلافهما.
الارتباط (Correlation)
الارتباط هو أيضًا مقياس اتصال يقيم درجة واتجاه الارتباط الخطي بين المتغيرات. يشير الارتباط إلى ارتباط أو نمط بين متغيرين مستهدفين. الارتباط بين متغيرين عشوائيين، X وZ، يساوي تباين هذين المتغيرين مقسومًا على حاصل انحرافاتهما المعيارية، كما هو موضح في المعادلة أدناه.

تتراوح معاملات الارتباط من -1 إلى 1. تذكر أن ارتباط المتغير بنفسه يكون دائمًا 1، وبالتالي فإن Cor(X, X) = 1. هناك نقطة أخرى يجب تذكرها عند تقييم الارتباط وهي عدم الخلط بينه وبين السببية. نظرًا لأن الارتباط ليس سببية. حتى إذا ارتبط متغيران، فهذا لا يعني أن أحدهما يسبب تغييرًا في الآخر. قد يكون هذا الارتباط عشوائيًا، أو قد يؤثر المكون الثالث على كلا المتغيرين.
وظائف توزيع الاحتمالات (Probability distribution Functions)
دالة توزيع الاحتمالات (pdf) أو كثافة الاحتمال هي دالة تحدد جميع القيم المحتملة، ومساحة العينة، والاحتمالات ذات الصلة التي يمكن أن يأخذها متغير عشوائي ضمن نطاق محدد يحده الحد الأدنى والحد الأقصى للقيم التي يمكن تصورها.
يجب أن تلبي كل دالة توزيع احتمالية المعيارين التاليين:

ينص الشرط الأول على أن تكون جميع الخيارات أعدادًا صحيحة في النطاق [0,1]، بينما يشير المعيار الثاني إلى أن مجموع جميع الاحتمالات التي يمكن تصورها يجب أن يساوي 1.
غالبًا ما تنقسم وظائف الاحتمال إلى فئتين: منفصلة ومتصلة. تصور دالة التوزيع المنفصلة عملية عشوائية بمساحة عينة محدودة، مثل رمي العملة المعدنية بنتيجتين فقط. تحدد دالة التوزيع المستمر عملية عشوائية عبر مساحة عينة مستمرة. تشمل أمثلة وظائف التوزيع المنفصلة برنولي (Bernoulli)، والثنائية (Binomial)، وبواسون (Poisson)، والمنتظم المنفصل (Discrete Uniform). تشمل أمثلة وظائف التوزيع المستمر التوزيع الطبيعي (Normal)، والمنتظم المستمر (Continuous Uniform)، وكوشي (Cauchy).
الانحدار الخطي (Linear Regression)
الانحدار الخطي هو إجراء إحصائي يحدد العلاقة بين المتغيرات التابعة والمستقلة. هذه الاستراتيجية مفيدة للغاية في التعلم الآلي الخاضع للإشراف. بالطبع، هذا تعريف كتابي؛ بعبارة أخرى، يمكن تعريف الانحدار بأنه عملية تحديد أفضل خط أو معادلة انحدار مناسبة بناءً على العلاقة بين المتغيرات من أجل توليد التنبؤات.
ما الفرق بين علم البيانات واستخراج البيانات؟
استخراج البيانات (Data Mining) هو عملية تحليل مجموعات البيانات (Datasets) للكشف عن الأنماط والاتجاهات المخفية باستخدام تقنيات مثل التعلم الآلي، والإحصائيات، وأنظمة قواعد البيانات (Database Systems). يُعتبر استخراج البيانات جزءًا من علوم الحاسوب ويتداخل مع تخصصات أخرى، ولكنه يركز بشكل أساسي على استخدام الخوارزميات الذكية لتحويل البيانات الخام إلى معلومات قابلة للاستخدام التجاري.
تم صياغة مصطلح “اكتشاف المعرفة في قاعدة البيانات” (Knowledge Discovery in Database) من قبل غريغوري بياتتسكي شابيرو في عام 1989، وأصبح استخراج البيانات يُستخدم على نطاق واسع منذ التسعينيات، خاصة من قبل خبراء قواعد البيانات. تُوظّف الشركات المالية وشركات التجزئة استخراج البيانات لتحليل البيانات الكبيرة، بهدف العثور على أنماط تسهم في تحسين استراتيجيات العملاء والتنبؤ بتغيرات السوق.
أما علم البيانات (Data Science)، فهو مجال أوسع يشمل استخدام التقنيات والإجراءات والخوارزميات لتحليل كميات هائلة من البيانات المنظمة وغير المنظمة بهدف استخراج رؤى ومعلومات قيمة. علم البيانات يعتمد على مجموعة من التخصصات مثل استخراج البيانات، والتعلم العميق (Deep Learning)، وتحليل البيانات الضخمة (Big Data).
صاغ بيتر ناور مصطلح “علم البيانات” في عام 1974 كبديل لمصطلح “علوم الحاسوب”، وفي عام 1997، اقترح جيف وو إعادة تسمية الإحصاء إلى علم البيانات للتخلص من التصورات التقليدية المرتبطة بالإحصاء. بدوره، رأى تشيكيو هاياشي في عام 1998 أن علم البيانات هو مجال جديد ومتعدد التخصصات يتجاوز حدود الإحصاء التقليدي ليشمل تحليلات البيانات العميقة والرؤى التنبؤية.
الفرق الأساسي بين علم البيانات واستخراج البيانات هو أن الأول يشمل نطاقًا أوسع من الأدوات والتقنيات لتحليل البيانات واستخراج الرؤى، بينما يركز الثاني على استخدام تقنيات محددة للكشف عن الأنماط المخفية في البيانات.
اقرأ الجدول أدناه لفهم المزيد عن الاختلافات بين هاتين الفكرتين وأين يتم استخدامهما في أغلب الأحيان:
| العنصر | علم البيانات | استخراج البيانات |
|---|---|---|
| التعريف | يركز على تحليل واستخدام البيانات لاستخراج المعلومات واتخاذ القرارات الفاعلة. | يعني جمع البيانات من مصادر متنوعة بغرض التخزين والاحتفاظ بها للاستفادة في وقت لاحق. |
| الهدف الرئيسي | استخدام البيانات لفهم الأنماط والاتجاهات واتخاذ قرارات مستنيرة. | جمع البيانات الأولية وتنظيمها بشكل أساسي للاحتفاظ بها والرجوع إليها. |
| التقنيات المستخدمة | يستخدم تقنيات التحليل الإحصائي والتعلم الآلي لاستخدام البيانات بشكل فعال. | يركز على تقنيات تخزين البيانات وقد تشمل قواعد البيانات وتقنيات الاستعلام. |
| المجالات الرئيسية | يشمل علم البيانات مجالات متنوعة مثل التنبؤ، وتصور البيانات، والتحليل الاستراتيجي. | يكون استخراج البيانات أحد المراحل الأولية في عملية تحليل البيانات والتي يمكن استخدامها في مختلف المجالات. |
| التأثير النهائي | يسهم في اتخاذ قرارات أفضل وتحسين الأداء بناءً على الفهم العميق للبيانات. | يقدم البيانات الأولية التي يمكن استخدامها لأغراض متعددة، بدءًا من التحليل البسيط إلى الاستفادة منها في مشروعات أكبر. |
خريطة طريق تعلم علم البيانات
إذا قررت بعد كل ما قرأته الدخول في مهنة علم البيانات، فسنلقي نظرة على مسار التعلم لتصبح عالم بيانات في هذا الجزء. يطبق عالم البيانات تقنيات من هندسة البرمجيات والإحصاء والأعمال لتحليل البيانات واستخلاص رؤى مفيدة. في هذا القسم، حددنا بعض المراحل لمساعدتك على تعلم وإتقان المهارات المطلوبة لتصبح عالم بيانات.
تتمتع هذه المراحل بمنحنى تعلم خاص بها بسبب التعقيدات الحالية. ونتيجة لذلك، يستغرق كل مستوى من مستويات التعلم والإتقان قدرًا متفاوتًا من الوقت. من الأفضل أن تأخذ هذه العناصر بناءً على ظروفك. لإتقان بعض العمليات، قد تحتاج إلى تنفيذ العديد من الخطوات في وقت واحد، وهي طريقة متفوقة بشكل واضح وستسمح لك بالتحرك بشكل أسرع.
تعلم بايثون Python
يجب أن يكون علماء البيانات متقنين لواحدة أو أكثر من لغات البرمجة للقيام بواجباتهم. تعد Python وR أكثر اللغات استخدامًا بين علماء البيانات. إذا كنت مبتدئًا، فإن بايثون لعلم البيانات هي أفضل لغة برمجة للبدء بها.
أحد الأسباب الرئيسية لاستخدام بايثون على نطاق واسع وشعبية في مجال علم البيانات هو سهولة استخدامه وقواعده النحوية البسيطة، والتي تسمح للأشخاص الذين ليس لديهم خلفية هندسية بالتعلم والتكيف. هناك أيضًا العديد من مكتبات بايثون مفتوحة المصدر المتاحة، بالإضافة إلى الوثائق عبر الإنترنت، لإجراء أنشطة مختلفة في علم البيانات مثل التعلم الآلي والتعلم العميق وتصور البيانات وما إلى ذلك.
الآن بعد أن فهمت سبب وجوب دراسة بايثون كخطوة أولى نحو أن تصبح عالم بيانات، دعنا نلقي نظرة على مفاهيم البرمجة المحددة التي يجب أن تدرجها في مسار التعلم الخاص بك.
- هياكل البيانات (أنواع البيانات المختلفة والقوائم والمجموعات والقواميس والمصفوفات والمجموعات والمصفوفات والمتجهات وما إلى ذلك)
- تحديد وكتابة وظائف محددة من قبل المستخدم
- أنواع الحلقات والعبارات الشرطية مثل If وelse وما إلى ذلك
- خوارزميات البحث والفرز
- مفاهيم SQL – Join وAggregations وMerge وما إلى ذلك.
تعلم مكتبات بايثون لعلوم البيانات
يمكن أن يُعزى بروز بايثون في مجال علوم البيانات إلى حقيقة أنه يوفر مكتبات مختلفة لإكمال أي عملية متعلقة بعلوم البيانات. تتضمن بعض المكتبات الأكثر شيوعًا التي يستخدمها علماء البيانات ما يلي:
NumPy
NumPy هي حزمة تقدم طرقًا ووظائف لإدارة ومعالجة المصفوفات الضخمة والمصفوفات والجبر الخطي. يرمز اسمها إلى Numerical Python. تتضمن مكتبة المتجهات هذه مجموعة متنوعة من الجبر الخطي والوظائف الرياضية المطلوبة للعمل مع المصفوفات والمصفوفات الضخمة، بالإضافة إلى متجهات الوظائف، مما يسمح بالإجراءات على جميع أعضاء المتجه دون الحاجة إلى التكرار على كل عنصر. التطبيق، مما يؤدي إلى زيادة سرعة التنفيذ والأداء.
Pandas
Pandas هي مكتبة بايثون الأكثر استخدامًا بين علماء البيانات. تتضمن هذه المكتبة العديد من الوظائف المضمنة المفيدة لمعالجة وتحليل كميات هائلة من البيانات المنظمة. Pandas هي أداة ممتازة لتحليل البيانات وتدعم بنيتين للبيانات: السلسلة وإطار البيانات.
السلسلة عبارة عن مصفوفة أحادية البعد قد تحمل أي نوع من البيانات (عدد صحيح، نص، رقم عشري، كائن، إلخ). يعرّف Pandas إطار البيانات على أنه بنية بيانات ثنائية الأبعاد غير متجانسة يتم فيها تنظيم البيانات في صفوف وأعمدة، على غرار جدول بيانات Excel أو جدول SQL. يدعم Pandas DataFrame الأعمدة ذات أنواع البيانات العديدة.
Matplotlib
يعد التصور البياني للبيانات خطوة بالغة الأهمية في تطوير أي حل لعلم البيانات. Matplotlib عبارة عن حزمة مفيدة تتضمن طرقًا ووظائف لعرض البيانات في رسوم بيانية مختلفة.
Seaborn
هذه مكتبة تصور أخرى بلغة Python تتضمن العديد من الوظائف المضمنة لمجموعة متنوعة من أساليب التصور البياني للبيانات، بما في ذلك الرسوم البيانية العمودية والمخططات الشريطية وخرائط الحرارة ومخططات الكثافة والمزيد. إنه أسهل بكثير في الاستخدام من matplotlib وينتج نتائج جذابة بصريًا.
SciPy
كعالم بيانات، يجب عليك إجراء تحليلات إحصائية مكثفة للبيانات، بما في ذلك المتوسط والانحراف المعياري والدرجة المعيارية واختبار القيمة الاحتمالية وما إلى ذلك. يتضمن SciPy مجموعة من الخوارزميات والوظائف لتنفيذ المفاهيم الإحصائية والرياضية المستخدمة في أبحاث البيانات.
Scikit-Learn
إنها مكتبة تعلم آلي بلغة Python تقدم تنفيذات بسيطة وفعالة ومتسقة للعديد من خوارزميات التعلم الآلي.
تعرف على الإحصاء والرياضيات التطبيقية
الإحصاء والرياضيات من المكونات الأساسية لعلم البيانات وكل تقنية من تقنيات التعلم الآلي. يجب على علماء البيانات فهم العديد من المبادئ الإحصائية والرياضية التي تشارك في علوم البيانات. بالطبع، لست بحاجة إلى أن تكون عالم رياضيات لإتقان Data Science؛ إن مجرد التعرف على بعض المبادئ الأساسية يمكن أن يساعدك في فهم كيفية عمل الخوارزميات في هذا الموضوع.
تعرف على التعلم الآلي والعميق
بمجرد أن يكون لديك معرفة شاملة بجميع المبادئ التي تمت مناقشتها أعلاه، يمكنك المضي قدمًا في دراسة وفهم خوارزميات التعلم الآلي.
من المفاهيم التي تحتاج إلى التعرف عليها:
- التعلم الخاضع للإشراف (Supervised Learning): تتعلم هذه الخوارزميات نمط البيانات بناءً على المتغير المستهدف المقدم لها، والذي يتضمن تقنيات الانحدار والتصنيف. يجب أن يكون لديك خوارزميات التعلم الآلي الشائعة مثل الانحدار الخطي والانحدار اللوجستي وشجرة القرار والغابة العشوائية وXGBoost وNaive Bayes وKNN وما إلى ذلك في خريطة طريق التعلم الخاصة بك.
- التعلم غير الخاضع للإشراف (Unsupervised Learning): تُستخدم هذه الخوارزميات عندما لا يتوفر متغير مستهدف. تحتاج إلى دراسة أشياء مثل K-Means Clustering وPCA وAssociation Mining وما إلى ذلك في هذه الفئة.
- التعلم العميق (Deep Learning): هو مجال فرعي في مجال التعلم الآلي يقوم بنمذجة البيانات باستخدام الشبكات العصبية. الشبكات العصبية ليست سوى نماذج رياضية تحاكي الدماغ البشري. مكّن التعلم العميق علماء البيانات من معالجة ونمذجة البيانات المعقدة مثل الصور والنصوص وما إلى ذلك.
وظائف علم البيانات في العالم ومتوسط الرواتب
يفتح علم البيانات الأبواب لمجموعة واسعة من الوظائف في مختلف الصناعات. وفيما يلي بعض الوظائف التي يمكن لخبراء علوم البيانات القيام بها. وفيما يلي جدول شامل يحتوي على أبرز وظائف Data Science ومهامها الأساسية، بالإضافة إلى متوسط الرواتب التقريبية في الدول العربية والأجنبية:
| المسمى الوظيفي | الوصف الوظيفي | متوسط الراتب (الدول العربية) | متوسط الراتب (الدول الأجنبية) |
|---|---|---|---|
| محلل بيانات (Data Analyst) | تحليل البيانات لاستخراج الرؤى وتقديم التقارير لمساعدة الشركات في اتخاذ القرارات. | 5,000 - 12,000 دولار سنويًا | 50,000 - 80,000 دولار سنويًا |
| عالم بيانات (Data Scientist) | استخدام الخوارزميات والنماذج الإحصائية لتحليل البيانات الكبيرة واستخراج معلومات قيمة. | 8,000 - 20,000 دولار سنويًا | 90,000 - 130,000 دولار سنويًا |
| مهندس بيانات (Data Engineer) | تطوير وصيانة بنى البيانات والبنية التحتية اللازمة لمعالجة البيانات وتحليلها. | 7,000 - 18,000 دولار سنويًا | 80,000 - 120,000 دولار سنويًا |
| محلل أعمال (Business Analyst) | تحديد احتياجات العمل من خلال تحليل البيانات وتقديم توصيات لتحسين الأداء. | 6,000 - 15,000 دولار سنويًا | 70,000 - 100,000 دولار سنويًا |
| مهندس تعلم الآلة (Machine Learning Engineer) | تطوير وتطبيق نماذج تعلم الآلة لتحسين المنتجات والخدمات. | 10,000 - 25,000 دولار سنويًا | 100,000 - 150,000 دولار سنويًا |
| مدير علم البيانات (Data Science Manager) | قيادة فرق علم البيانات وتنسيق المشاريع لتحقيق أهداف الشركة. | 12,000 - 30,000 دولار سنويًا | 120,000 - 160,000 دولار سنويًا |
| مهندس بيانات كبيرة (Big Data Engineer) | تصميم وتنفيذ حلول بيانات كبيرة لتحليل كميات ضخمة من البيانات. | 9,000 - 22,000 دولار سنويًا | 90,000 - 140,000 دولار سنويًا |
| محلل ذكاء الأعمال (Business Intelligence Analyst) | استخدام أدوات ذكاء الأعمال لتحليل البيانات وتقديم رؤى تدعم قرارات الأعمال. | 5,000 - 13,000 دولار سنويًا | 60,000 - 90,000 دولار سنويًا |
| مهندس قواعد البيانات (Database Administrator) | إدارة وصيانة قواعد البيانات وضمان الأداء الأمثل والموثوقية. | 6,000 - 14,000 دولار سنويًا | 70,000 - 100,000 دولار سنويًا |
الآن دعونا نفحص العلاقة بين علم البيانات والذكاء الاصطناعي والتعلم الآلي والتعلم العميق.
العلاقة بين علم البيانات والذكاء الاصطناعي

علم البيانات والذكاء الاصطناعي مجالان متشابكان. يشير “الذكاء الاصطناعي” أو (AI) إلى نشاط الدماغ البشري المُحاكي في أجهزة الكمبيوتر. يعد التعلم والمنطق والتصحيح الذاتي من بين الخصائص التي تشير إلى هذا النوع من نشاط الدماغ. بعبارة أخرى، الذكاء الاصطناعي (AI) هو نظام يمكنه التعلم وتصحيح نفسه كما يعرف والاستدلال واستخلاص النتائج بشكل مستقل.
الذكاء الاصطناعي إما واسع أو محدود. يشير الذكاء الاصطناعي العام إلى الآلات الذكية التي نراها في الأفلام. يمكنها القيام بمجموعة متنوعة من المهام التي تتطلب التفكير والحكم والإدراك، وهي متطابقة بشكل أساسي مع تلك التي يؤديها البشر. حتى الآن، لم يتم تحقيق ذلك.
ومع ذلك، يستلزم الذكاء الاصطناعي الضيق تطبيق نفس النوع من مواهب “التفكير” على وظائف محددة للغاية. على سبيل المثال، يعد واتسون من IBM ذكاءً اصطناعيًا يمكنه فهم بعض أنواع المعلومات الطبية لأغراض التشخيص وكذلك أفضل من البشر في الظروف الصحيحة.
يسعى العلماء والمهندسون إلى تحقيق الذكاء الاصطناعي من خلال تطوير الشبكات العصبية الاصطناعية. ومع ذلك، فإن تعليم الروبوتات التفكير مثل العقل البشري، حتى بالنسبة لهدف محدد للغاية، يتطلب كمية هائلة من البيانات. هذا هو تقاطع علم البيانات والذكاء الاصطناعي والتعلم الآلي.
أوجه التشابه بين علم البيانات والتعلم الآلي
يعمل الذكاء الاصطناعي وعلوم البيانات والتعلم الآلي معًا. التعلم الآلي هو فرع من فروع علم البيانات يغذي أجهزة الكمبيوتر بكميات هائلة من البيانات حتى تتمكن من تعلم إصدار أحكام ذكية بنفس الطريقة التي يفعلها الناس.
على سبيل المثال، يتعلم معظم الشباب ما هي الزهرة دون التفكير فيها. ومع ذلك، يتعلم الدماغ البشري من الخبرة – من خلال جمع البيانات – على السمات المحددة المرتبطة بالزهور.
يمكن للآلة إنجاز نفس الشيء بمساعدة بشرية. عندما يقدم الناس للخوارزمية كميات هائلة من البيانات، فقد يتعلمون أن البتلات والسيقان والخصائص الأخرى المختلفة مرتبطة جميعًا بالزهور.
بعبارة أخرى، يوفر البشر بيانات التدريب أو البيانات الخام للآلة، مما يسمح لها بتعلم جميع خصائص البيانات ذات الصلة. إذا كان التدريب فعالاً، فيجب أن يُظهر الاختبار باستخدام بيانات إضافية أن الكمبيوتر يمكنه التعرف على الميزات التي تعلمها. إذا لم يكن الأمر كذلك، فإنه يتطلب تعليمات إضافية أو أفضل.
الفرق بين Data Science والتعلم الآلي
علم البيانات هو امتداد طبيعي للإحصاءات. ظهر مع علم الكمبيوتر لإدارة كميات هائلة من البيانات باستخدام تقنيات جديدة.
التعلم الآلي، من ناحية أخرى، هو عملية داخل علم البيانات. إنه يمكّن أجهزة الكمبيوتر من التعلم – والقيام بذلك بشكل أكثر فعالية بمرور الوقت – دون الحاجة إلى برمجة صريحة لكل قطعة من المعلومات.
في التعلم الآلي، تستخدم أجهزة الكمبيوتر الخوارزميات لتعليم نفسها، لكن هذه الخوارزميات تتطلب بعض بيانات المصدر. يستخدم الكمبيوتر هذه البيانات كمجموعة تدريب لتعزيز خوارزميته، والتي يقوم بتعديلها واختبارها أثناء التحسين. إنه يضبط العديد من معلمات خوارزميات Data Science الخاصة به باستخدام الأساليب الإحصائية مثل بايز الساذج والانحدار والتجميع الخاضع للإشراف.
ومع ذلك، يتم تضمين منهجيات إضافية تتطلب إدخالًا بشريًا أيضًا في علوم البيانات كما نعرفه اليوم. على سبيل المثال، يمكن لجهاز كمبيوتر استخدام التجميع غير الخاضع للإشراف لتعليم جهاز آخر التعرف على هياكل البيانات من أجل تحسين خوارزمية التصنيف. ولكن من أجل إكمال العملية، يتعين على الإنسان تصنيف الهياكل التي حددها الكمبيوتر – على الأقل حتى يتم تدريبه بالكامل.
يمتد نطاق علم البيانات إلى ما هو أبعد من التعلم الآلي، بما في ذلك البيانات التي لا يتم إنشاؤها بواسطة عملية ميكانيكية أو كمبيوتر أو آلة. على سبيل المثال، يشمل التخصص بيانات المسح، والبيانات من التجارب السريرية، وكل نوع آخر من البيانات الموجودة تقريبًا – الطيف الكامل.
تتضمن علوم البيانات أيضًا تقديم البيانات، وليس تدريب الروبوتات فقط. يشمل علم البيانات أكثر بكثير من مجرد مخاوف البيانات الإحصائية؛ فهو يغطي أيضًا أتمتة التعلم الآلي وإصدار أحكام مدفوعة بالبيانات. ومع ذلك، فإنه يشمل أيضًا تكامل البيانات وهندسة البيانات وتصور البيانات، بالإضافة إلى الهندسة المعمارية الموزعة وتطوير لوحات المعلومات وتطبيقات ذكاء الأعمال الأخرى. في الواقع، يشمل Data Science أي نشر للبيانات على مستوى الإنتاج.
لذا، بينما يولد عالم البيانات رؤى من البيانات، تتعلم الآلة بناءً على الرؤى التي اكتشفها عالم البيانات سابقًا. وبينما يمكن للكمبيوتر أن يستمد رؤاه من الإطار الخوارزمي الحالي، يجب أن يبدأ ببعض البيانات المنظمة.
باختصار، يجب على عالم البيانات أن يفهم التعلم الآلي، الذي يتضمن العديد من مناهج علم البيانات. ومع ذلك، قد تتضمن “البيانات” بالنسبة لعالم البيانات بيانات من عملية ميكانيكية أو آلة وقد لا تتضمنها.
الفرق بين علم البيانات والتعلم العميق
التعلم العميق هو وظيفة الذكاء الاصطناعي التي تحاكي كيفية معالجة الدماغ البشري للبيانات وإنتاج أنماط لاتخاذ القرار. وبالتالي فإن التعلم العميق هو مجموعة فرعية من التعلم الآلي الذي يركز على الشبكات العصبية العميقة القادرة على إتقان المواد غير المنظمة أو غير المصنفة دون تدخل بشري. يُعرف هذا أيضًا باسم التعلم العصبي العميق.
ينخرط التعلم العميق في عملية التعلم الآلي من خلال استخدام الشبكات العصبية الاصطناعية الهرمية. هذه الشبكات العصبية الاصطناعية عبارة عن شبكات معقدة من عقد الخلايا العصبية، على غرار الدماغ البشري. على الرغم من أن أدوات تحليل البيانات النموذجية تعالج البيانات بشكل خطي، فإن التسلسل الهرمي لوظائف نظام التعلم العميق يسمح باتباع نهج غير خطي للقضايا.
نظرًا لأن البيانات الضخمة غير منظمة بشكل عام، فإن التعلم العميق هو مجال فرعي أساسي لدراسة علم البيانات.
مقالة ذات صلة: ما هو التعلم العميق (Deep Learning) وما هي استخداماته؟
المستقبل والآثار الواعدة لعلم البيانات
وفقًا لـ IDC، ستصل البيانات العالمية إلى 175 زيتابايت بحلول عام 2025. يساعد علم البيانات الشركات على فهم كميات هائلة من البيانات بسهولة من مصادر متعددة واكتساب رؤى مهمة لاتخاذ خيارات أفضل تعتمد على البيانات.
كما ذكرنا، يتم استخدام Data Science على نطاق واسع في مجموعة متنوعة من الصناعات، بما في ذلك التسويق والرعاية الصحية والتمويل والخدمات المصرفية وصنع السياسات. وهذا يوضح أهمية علم البيانات.
لتلخيص فائدة علم البيانات من منظور الشخص العادي، يمكننا القول إنه يقسم البيانات المعقدة إلى نموذج أولي قابل للاستخدام. لقد جعل هذا المجال متعدد التخصصات من الممكن الوصول إلى البيانات الضخمة وتفسيرها. وبالتالي، يمكن للأفراد العمل دون عناء على أحجام كبيرة لتحديد العمليات المثلى.
نظرًا للارتباط الوثيق بين البيانات الضخمة والعالم. يسمح هذا الارتباط للفرد بتغيير نماذج الأعمال السائدة للصناعات والشركات القديمة لإنشاء نماذج جديدة.
تساعد هذه التعديلات قطاعات مختلفة مثل التسويق والنقل والخدمات المصرفية والتجارة الإلكترونية والزراعة والتمويل والرعاية الصحية وما إلى ذلك على التحسن والازدهار. ونتيجة لذلك، تتمتع الشركات التي تعتمد على البيانات بإمكانية كسب تريليونات الدولارات. ووفقًا لموقع Glassdoor، يمكن لعلماء البيانات كسب ما يصل إلى 166000 دولار سنويًا في الولايات المتحدة.
ما فائدة علم البيانات؟
- في صناعة الرعاية الطبية، يستخدم الأطباء Data Science لتحليل البيانات التي تم الحصول عليها من أجهزة التتبع التي يحملها المرضى لضمان صحة مرضاهم؛ وبهذه الطريقة، يمكنهم اتخاذ قرارات صحيحة وفي الوقت المناسب عند الضرورة؛ بالإضافة إلى ذلك، يمكن لعلم البيانات أن يسمح لمديري المستشفيات بتقليل وقت انتظار المرضى. كما تستخدم شركات الرعاية الطبية علم البيانات لإنشاء أدوات لتشخيص وعلاج الأمراض.
- تستخدمه شركات التجزئة لتحسين تجربة العملاء وكذلك الاحتفاظ بعملائهم؛ على سبيل المثال، يوصي موقع أمازون بمنتجات مختلفة للعملاء بناءً على اهتماماتهم.
- يستخدم data science على نطاق واسع في البنوك والمؤسسات المالية للكشف عن الاحتيال وكذلك المشورة المالية الشخصية.
- تستخدم شركات البناء Data Science لاتخاذ قرارات أفضل من خلال تتبع الأنشطة، بما في ذلك متوسط الوقت لإكمال المهام المختلفة وتكاليف المواد الاستهلاكية والمزيد.
- يجعل علم البيانات من الممكن العثور على أنماط المحتوى التي يستخدمها المستخدمون باستخدام محتوى الشبكات الاجتماعية. تساعدنا هذه الأنماط في إنتاج محتوى حصري لكل مستخدم؛ كما يقترح محتوى مناسبًا للمستخدم.
- يتم تطوير ألعاب الفيديو والكمبيوتر الآن بمساعدة علوم البيانات، وقد أدى هذا إلى رفع تجربة الألعاب إلى مستوى أعلى.
لماذا تهتم المملكة العربية السعودية بتدريس علم البيانات؟
أظهرت المملكة العربية السعودية اهتمامًا متزايدًا بعلم البيانات لعدة أسباب رئيسية. أولاً، تعمل البلاد بنشاط نحو التنويع الاقتصادي لتقليل اعتمادها على النفط.
يوفر Data Science فرصًا للابتكار وتطوير الصناعات القائمة على المعرفة. من خلال الاستثمار في علم البيانات، يمكن للمملكة العربية السعودية تعزيز الاقتصاد الرقمي، وخلق فرص عمل جديدة، ودفع النمو الاقتصادي في المناطق الناشئة.
ثانيًا، أدى دفع الحكومة نحو التحول الرقمي عبر مختلف القطاعات إلى زيادة الاهتمام بعلوم البيانات. تسعى المملكة العربية السعودية إلى الاستفادة من البيانات لتعزيز الكفاءة التشغيلية وتقديم خدمات أفضل للمواطنين.
من خلال استخدام تقنيات علم البيانات، يمكن للبلاد تحليل مجموعات البيانات الكبيرة، وتوليد رؤى قيمة، وتحسين عمليات صنع القرار. يساهم هذا في الهدف العام المتمثل في تحسين تقديم الخدمات، وتحسين تخصيص الموارد، وتحسين الحوكمة.
أخيرًا، يتماشى السعي وراء Data Science مع رؤية المملكة العربية السعودية 2030، وهي خطة شاملة لمستقبل البلاد. تهدف رؤية 2030 إلى تنويع الاقتصاد، وتحسين نوعية الحياة، وجذب الاستثمار الأجنبي.
تلعب علوم البيانات دورًا محوريًا في قطاعات مثل الرعاية الصحية والمدن الذكية والتجارة الإلكترونية والتعليم، مما يساهم في الابتكار والنمو الاقتصادي المستدام. ومن خلال تبني علوم البيانات، تعمل المملكة على وضع نفسها كمركز للتقدم التكنولوجي والسعي إلى تطوير قوة عاملة ماهرة قادرة على قيادة أجندة التحول الرقمي.
إستنتاج
في ختام مقالنا عن “علم البيانات“، نستنتج أنه يشكل ركيزة أساسية في التحول الرقمي الذي نشهده اليوم، فمن خلال تسخير التقنيات المتقدمة وتحليل كميات هائلة من البيانات، تستطيع الشركات والمؤسسات تحقيق رؤى دقيقة تعزز اتخاذ القرارات الاستراتيجية وتوفر حلولاً مبتكرة.
لقد استعرضنا كيف يجمع Data Science بين عدة مجالات مثل الإحصاء والبرمجة والتعلم الآلي لخلق قيمة حقيقية من البيانات الخام، كما أشرنا إلى التطور السريع لهذا المجال والطلب المتزايد على علماء البيانات في السوق العالمية، مما يؤكد على أهمية هذا التخصص في تشكيل مستقبل الأعمال والابتكار.
وفي الختام، يبرز سؤال مهم: كيف سيستمر علم البيانات في التطور لمواكبة التحديات المستقبلية والاستجابة للتغيرات السريعة في عالم التكنولوجيا؟ ويبقى هذا السؤال مفتوحًا، ويدعو القراء إلى التفكير في الإمكانيات غير المحدودة التي قد يقدمها هذا المجال المثير.
وفي الختام، تظل علوم البيانات بوابة حقيقية للتحليل الذكي، وركيزة أساسية لدفع التقدم والابتكار في مختلف القطاعات.
