
تعلم الذكاء الاصطناعي AI مجانًا مباشرةً من أكبر 10 شركات – فرصة ذهبية لعلم المستقبل


يشهد العالم اليوم تحول رقمي غير مسبوق، ويكمن جوهر هذا التحول في تعلم الذكاء الاصطناعي (AI)، التخصص الأكثر طلباً في سوق العمل العالمي. لم يعد مجرد مسعى أكاديمي أو ترف فكري، بل أصبح المعيار الحقيقي الذي يفصل بين من يصنعون المستقبل ومن يكتفون بمشاهدته. الفرصة سانحة الآن، مجانية ومتاحة من كبرى شركات التكنولوجيا العالمية.
لسنوات، ساد الاعتقاد بأن الذكاء الاصطناعي حكر على المتخصصين وحاملي الشهادات العليا. لكن الواقع مختلف تماماً. فشركات مثل Google، وMeta، وAnthropic، وNvidia، وغيرها، تفتح أبوابها مجاناً لكل من يرغب في التعلم، بمحتوى صممه نخبة المهندسين والباحثين في العالم. هذه المقالة دليلك العملي للوصول إلى هذه الموارد وتحويلها إلى مهارة قيّمة تستحق الاستثمار.
ما ستجده هنا ليس مجرد قائمة روابط، بل هو خارطة طريق منظمة تبدأ من الصفر وتوصلك إلى مستوى يؤهلك لسوق العمل. ستتعلم المكونات الأساسية للتعلم، وأفضل المسارات المجانية، والأخطاء التي تضيع الوقت، وكيفية بناء مشروعك الأول في غضون ثلاثين يومًا.
جدول المحتويات
- ما هو الذكاء الاصطناعي ؟
- ما معنى تعلم الذكاء الاصطناعي؟
- لماذا تحتاج إلى مسار منظم لتعلم الذكاء الاصطناعي بدلاً من المصادر العشوائية ؟
- المكونات الجوهرية لأي خطة ناجحة في تعلم الذكاء الاصطناعي
- تعلم الذكاء الاصطناعي مجانًا: من أين تبدأ بالضبط؟
- أفضل 10 شركات تقدم مسارات مجانية معتمدة في تعلم الذكاء الاصطناعي
- جدول مقارنة الشهادات والمسارات التعليمية للذكاء الاصطناعي
- الأخطاء القاتلة التي تحوّل تعلم الذكاء الاصطناعي إلى مضيعة للوقت
- كيف تبني مشروعك التطبيقي الأول خلال 30 يوماً من بدء تعلم الذكاء الاصطناعي
- هل تعلم الذكاء الاصطناعي كافٍ في سوق العمل؟
- خلاصة عملية وجدول زمني أسبوعي لتعلم الذكاء الاصطناعي من الصفر
- هل تعلم الذكاء الاصطناعي سهل؟
- الخاتمة
ما هو الذكاء الاصطناعي؟
الذكاء الاصطناعي هو فرع من علوم الحاسوب يهدف إلى بناء أنظمة قادرة على تنفيذ مهام تتطلب عادة ذكاءً بشرياً. يشمل ذلك التعرف على الصور والكلام، وترجمة اللغات، واتخاذ القرارات، وتوليد النصوص. الفكرة الجوهرية هي تمكين الآلة من التعلم من البيانات بدلاً من البرمجة اليدوية لكل سيناريو ممكن.
ينقسم الذكاء الاصطناعي إلى عدة مجالات. التعلم الآلي Machine Learning هو الأوسع، ويعتمد على بناء نماذج تتعلم من البيانات وتحسن أداءها بمرور الوقت. وداخله يوجد التعلم العميق Deep Learning الذي يحاكي طريقة عمل الدماغ البشري عبر شبكات عصبية اصطناعية متعددة الطبقات. هذه الشبكات هي العقل الذي يقف خلف ChatGPT وأنظمة التعرف على الوجه وسيارات القيادة الذاتية.
من الناحية التاريخية، مر الذكاء الاصطناعي بمراحل تطور متعاقبة منذ خمسينيات القرن الماضي. غير أن القفزة الحقيقية جاءت مع توفر البيانات الضخمة وازدياد القدرة الحسابية للمعالجات الحديثة. واليوم، تشكل نماذج اللغة الكبيرة LLMs مثل GPT-4 وClaude وGemini جيلاً جديداً من الأنظمة القادرة على الفهم والتوليد اللغوي بمستوى لم يشهد من قبل.
فهم الذكاء الاصطناعي لا يعني بالضرورة أن تصبح باحثاً. بل يعني أن تعرف كيف تختار النموذج المناسب للمشكلة، وكيف تعد البيانات، وكيف تقيم النتائج، وكيف تدمج هذه الأنظمة في تطبيقات حقيقية تحل مشكلات حقيقية، وهذا المستوى في متناول يدك إذا اتبعت مساراً منظماً.
مقالة ذات صلة: الذكاء الاصطناعي (AI): ثورة في تحسين كفاءة الأعمال وتطوير المستقبل.
ما معنى تعلم الذكاء الاصطناعي؟

تعلم الذكاء الاصطناعي لا يعني أن تصبح عالماً أبحاثاً أو أن تكتب خوارزميات من الصفر باستخدام الورقة والقلم. بل يعني أن تصل إلى مرحلة الفهم الأعمق التي تسمح لك باختيار الأداة المناسبة للمشكلة المناسبة، وتجهيز البيانات بشكل صحيح، وتشغيل النموذج وتقييمه، وتفسير نتائجه بثقة، وأخيراً نشره في بيئة حقيقية ليخدم مستخدمين فعلين. وهذا المستوى لا يحتاج إلى ذكاء خارق، بل يحتاج إلى منهجية واضحة و صبر منظم و تطبيق عملي مستمر.
بمعنى أدق، تعلم الذكاء الاصطناعي ينقسم إلى ثلاث مراحل متصاعدة:
المرحلة الأولى: فهم المفاهيم (ما هي الشبكة العصبية، ما الفرق بين التعلم الخاضع وغير الخاضع للإشراف).
المرحلة الثانية: استخدام الأدوات (تنفيذ نموذج باستخدام Scikit-learn أو PyTorch، ومعالجة البيانات باستخدام Pandas).
والمرحلة الثالثة: التطبيق المستقل (حل مشكلة حقيقية من البداية إلى النهاية، وتوثيق الحل، والدفاع عنه أمام الآخرين). فمعظم الناس يتوقف عند المرحلة الثانية، بينما سوق العمل يريد من وصل إلى المرحلة الثالثة.
جوهر التعلم إذاً ليس حفظ المصطلحات والمكتبات، بل بناء القدرة على التفكير المنهجي في حل المشكلات باستخدام البيانات والنماذج. بمعنى أنك حين تواجه مشكلة جديدة لم ترها من قبل، ستكون قادراً على تشريحها، وتحويلها إلى مهمة تعلم آلي، وتجربة حلول عملية، وتقييمها ثم تحسينها. هذا ما يفرق المتعلم الحقيقي عن مستهلك المحتوى، وهذا هو المعنى العميق لـ تعلم الذكاء الاصطناعي الذي تبحث عنه.
لماذا تحتاج إلى مسار منظم لتعلم الذكاء الاصطناعي بدلاً من المصادر العشوائية؟
ليس فرق معلومات بل فرق منهجية بين المعرفة السطحية والكفاءة القابلة للتنفيذ في سوق العمل. فكثيرون يقضون أشهراً يشاهدون مقاطع YouTube ويلتحقون بدورات متفرقة. ثم يجدون أنفسهم أمام مشكلة برمجية بسيطة عاجزين عن حلها، والسبب هو غياب البنية التحتية للمعرفة. وحين تتعلم بشكل عشوائي، تجمع قطعاً من أحجية لا تتصل ببعضها.
المسار المنظم يبني المعرفة طبقة فوق طبقة. فتبدأ بالأسس الرياضية، ثم تنتقل إلى البرمجة، ثم معالجة البيانات، ثم النماذج، وأخيراً التطبيق. وكل مرحلة تعزز ما قبلها وتفتح ما بعدها. وهذا هو الفرق بين من يفهم لماذا يعمل النموذج وبين من يعرف فقط كيف يشتغله، والفرق ضخم جداً في سوق العمل الذي يبحث عن الأول لا عن الثاني.
ويميز أصحاب العمل والعملاء بسرعة بين من بنى مهارته على أساس متين وبين من جمع شهادات إتمام دورات AI. فـالمشروع الحقيقي يفضح المستوى الحقيقي. ولهذا السبب، الشركات الكبرى التي سنذكرها في هذا المقال لا تقدم فقط محتوى، بل تقدم مسارات متسلسلة مع مشاريع تطبيقية وشهادات معترف بها في السوق.
المكونات الجوهرية لأي خطة ناجحة في تعلم الذكاء الاصطناعي
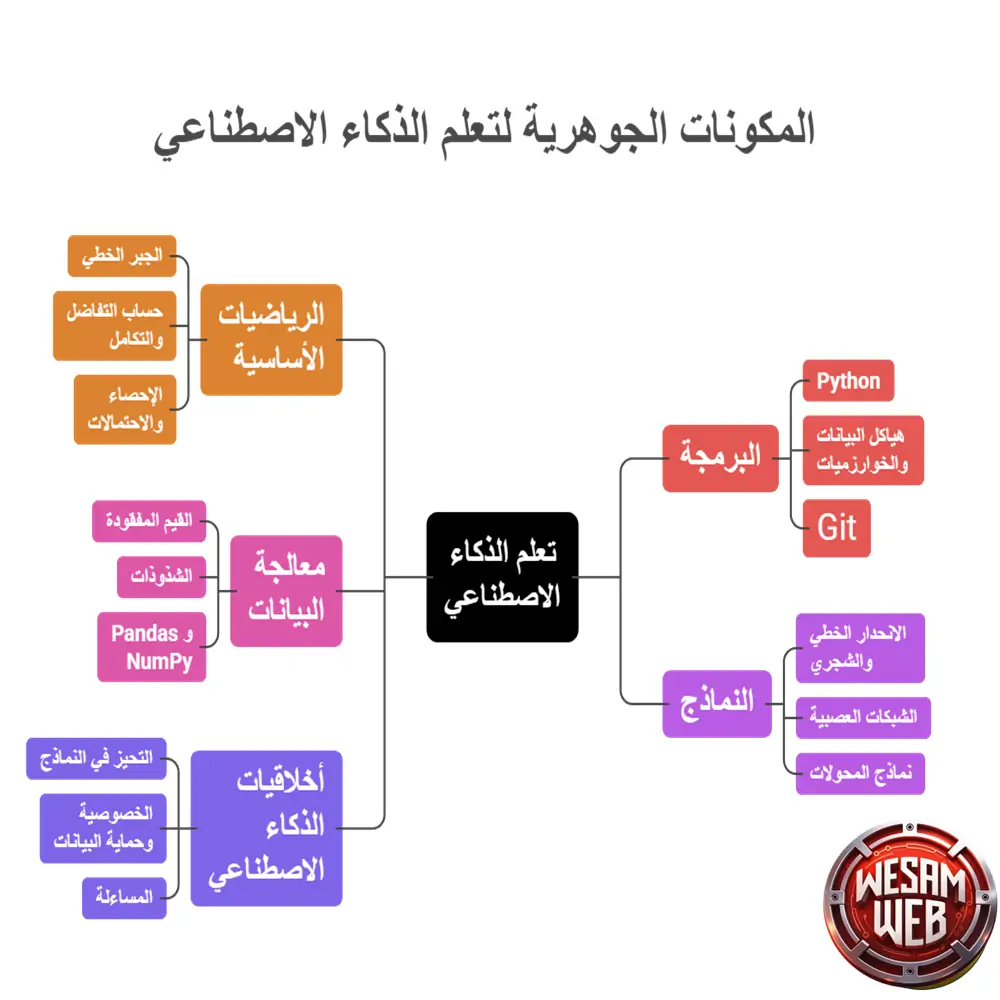
قبل أن تلتحق بأي دورة أو تفتح أي موقع، يجب أن تعرف ما الذي تتعلمه بالضبط. تعلم الذكاء الاصطناعي ليس مادة واحدة، بل منظومة من المعارف المتشابكة. الجيد في الأمر أنك لا تحتاج إلى إتقان كل شيء من البداية، بل تحتاج إلى معرفة الترتيب الصحيح.
من يبني هذه المنظومة بشكل صحيح يجد نفسه قادراً على التعامل مع أي مشكلة جديدة في المجال، لأن لديه الأدوات المفاهيمية للتفكير فيها. أما من يبنيها بشكل خاطئ فيجد نفسه يحفظ خطوات دون فهم، ويتوه أمام أي تغيير في المشكلة.
أولاً: الرياضيات الأساسية
لا يحتاج الجميع إلى درجة في الرياضيات التطبيقية، لكن ثمة حد أدنى لا غنى عنه. الجبر الخطي هو لغة البيانات في عالم الذكاء الاصطناعي، لأن كل صورة ونص وصوت يمثل في النهاية كمصفوفات أرقام. وحساب التفاضل والتكامل ضروري لفهم كيف تتعلم النماذج وتحسن نفسها عبر ما يعرف بـ الانحدار التدريجي Gradient Descent. كما أن الإحصاء والاحتمالات تمنحك القدرة على تقييم النماذج وتفسير نتائجها بشكل صحيح.
المستوى المطلوب ليس أكاديمياً عميقاً، بل وظيفياً عملياً. فأنت تحتاج أن تفهم ما تعنيه المعادلات، لا أن تثبتها من الصفر. والمفاتيح الأساسية التي تركز عليها هي:
- الجبر الخطي: المصفوفات، ضرب المصفوفات، القيم الذاتية
- التفاضل والتكامل: المشتقات، سلسلة القواعد Chain Rule
- الإحصاء: التوزيعات، الارتباط، الاختبارات الإحصائية
- الاحتمالات: نظرية بايز، التوزيعات الشرطية
ثانياً: البرمجة
تعلم البرمجة قبل تعلم الذكاء الاصطناعي يعني فهم المنطق الحسابي نفسه، كيف تفكر الآلة، كيف تخزن البيانات في الذاكرة، كيف تتصرف الخوارزميات مع الزمن والمساحة. هذه المبادئ المجردة تبقى صحيحة سواء كتبت الكود بإحدى لغات البرمجة مثل بايثون أم جافا أم سي++, وهي الأساس الذي يجعلك قادراً على تعلم أي لغة جديدة خلال أيام. فالمبتدئ الذي يفهم الحلقات و الشروط و الدوال و المصفوفات و التعقيد الحسابي يكون جاهزاً لأي بيئة برمجية مهما كانت. أما من يكتفي بحفظ دوال بايثون فقط فيجد نفسه عاجزاً خارج بيئة اللغة الواحدة.
لماذا بايثون Python تحديداً للذكاء الاصطناعي؟ ليس لأنها لغة برمجة مثالية، بل لأنها أصبحت لغة التجميع الفعلية للمجتمع. فجميع المكتبات الأساسية في المجال مكتوبة بلغات أسرع مثل C++ و CUDA خلف الكواليس، وتقدم بايثون واجهة بسيطة للتعامل معها.
هذا يعني أنك تتعلم كيف تستدعي مكتبة قوية مكتوبة بلغة منخفضة المستوى، وليس كيف تكتب خوارزمية ذكاء اصطناعي من الصفر بلغة سي++. وهذا يختصر عليك سنوات من العمل ويتيح لك التركيز على حل المشكلة وليس على تفاصيل إدارة الذاكرة.
مقالة ذات صلة: تعرف على أساسيات لغة بايثون (Python) لغة البرمجة الأولى للمبتدئين والمبرمجين.
ما تحتاجه:
ما تحتاجه حقاً هو ثلاث طبقات من المعرفة البرمجية. الطبقة الأولى: أساسيات البرمجة العامة (التي تتعلمها من أي لغة، لكن بايثون أسهل للبدء). الطبقة الثانية: بيئة بايثون العلمية وتشمل NumPy للعمليات الرقمية، Pandas للجداول، Matplotlib للرسم. الطبقة الثالثة: أدوات الاحتراف مثل Git للتحكم في الإصدارات، وبيئات العمل الافتراضية، وكتابة الاختبارات، وتنظيم المشاريع. فالطبقة الأولى وحدها لا تكفي، والطبقة الثانية بدون الأولى تصبح حفظاً للصيغ، والطبقة الثالثة هي ما يفصل الهواة عن المحترفين في بيئات العمل الحقيقية.
نصيحة من وسام ويب:
ابدأ بتعلم البرمجة العامة عبر لغة بايثون (دورة CS50 مقدمة من Harvard مثلاً)، وركز على المفاهيم لا الصيغ. ثم تعلم مكتبات بايثون العلمية، ولا تنتقل إلى الذكاء الاصطناعي قبل أن تكون قادراً على كتابة برنامج من 100 سطر دون نسخ ولصق. والمهارات البرمجية التي تبنيها هنا ليست مضيعة للوقت بل هي استثمار في سرعتك المستقبلية. فكلما قويت أسسك البرمجية اليوم، زادت سرعتك في تجربة أفكار الذكاء الاصطناعي غداً بأضعاف مضاعفة.
مقالة ذات صلة: البرمجة للمبتدئين Programming: خارطة طريق نحو أول مشروع حقيقي.
ثالثاً: معالجة البيانات
البيانات هي وقود الذكاء الاصطناعي، فالنموذج الجيد على بيانات سيئة يعطي نتائج سيئة دائماً. لذا فإن فهم كيفية جمع البيانات وتنظيفها واستكشافها والتحقق من جودتها هو مهارة مستقلة تستحق وقتاً خاصاً بها. وهذه المهارة يهملها كثير من المتعلمين الجدد، فيندمون عليها لاحقاً حين تتوقف نماذجهم عن العمل لأسباب تتعلق بالبيانات. فالوقت المستثمر في تعلم معالجة البيانات يعود بفوائد كبيرة في كل مشروع لاحق.
معالجة البيانات تشمل التعامل مع القيم المفقودة، واكتشاف الشذوذات والقيم المتطرفة، وتحويل المتغيرات إلى صيغ يفهمها النموذج. كما تشمل تقسيم البيانات بشكل صحيح بين مجموعات التدريب والتحقق والاختبار. فالأخطاء في هذه المرحلة تفسد كل ما يليها، ولا يمكن لأي نموذج أن يصححها لاحقاً. ومكتبتا Pandas و NumPy هما الأداتان الأساسيتان في هذه المرحلة، ويضاف إليهما Matplotlib و Seaborn للتصوير البياني الذي يساعدك على فهم البيانات قبل بناء أي نموذج.
رابعاً: النماذج
بعد إتقان التعامل مع البيانات، تنتقل إلى بناء النماذج وتقييمها. ثم تبدأ بـ:
- الانحدار الخطي والشجري: لفهم منطق التنبؤ الأساسي
- شجرة القرار وGradient Boosting: لمسائل التصنيف والتنبؤ المنظم
- الشبكات العصبية الأساسية: لفهم بنية التعلم العميق
- الشبكات التلافيفية CNN: للصور ومعالجة المرئيات
- نماذج المحولات Transformers: الأساس الذي تقوم عليه نماذج اللغة الكبيرة
- النماذج التوليدية: من GANs إلى نماذج الانتشار
خامساً: أخلاقيات الذكاء الاصطناعي
أخلاقيات الذكاء الاصطناعي ليست مادة اختيارية أو تكميلية، بل هي جزء أساسي من تكوين أي مهندس ذكاء اصطناعي محترف. ففي بيئة العمل الحديثة، المهندس الذي لا يفكر في تداعيات ما يبنيه يعد ناقصاً مهنياً وغير مكتمل الأدوات. والشركات الكبرى اليوم تضع هذا البعد الأخلاقي في قلب عملية التطوير، لا على هامشها. لذا فإن إهمال هذا الجانب يقلل من فرصك في الشركات الجادة.
التحيز في النماذج مشكلة حقيقية وموثقة ومعترف بها عالمياً. فحين تدرّب النماذج على بيانات تعكس تفاوتات تاريخية، فإنها تعيد إنتاج هذه التفاوتات وتضاعفها وتعمقها. لذا فإن فهم مصادر التحيز وطرق الكشف عنه والتخفيف منه جزء لا يتجزأ من بناء أنظمة ذكاء اصطناعي مسؤولة وعادلة. وتشمل الأخلاقيات أيضاً مسائل الخصوصية وحماية البيانات، وقابلية التفسير والشفافية في قرارات النماذج. كما تشمل المساءلة حين تخطئ هذه الأنظمة وتسبب ضرراً للبشر. فالإلمام بهذه الجوانب يجعلك محترفاً أكثر نضجاً وموثوقية في أعين أصحاب العمل.
تعلم الذكاء الاصطناعي مجانًا: من أين تبدأ بالضبط؟
المسار التعليمي الموصى به يتدرج على النحو التالي، وكل خطوة تهيئ للتي تليها:
أولًا: Python: ابدأ بتعلم Python من الصفر إذا لم تكن مبرمجًا. ركز على الأنواع الأساسية، والدوال، والكائنات، وكيفية قراءة الملفات وكتابتها. أسبوعان إلى ثلاثة كافية للوصول إلى مستوى مريح إذا خصصت ساعة يومية.
ثانيًا: Pandas: هذه المكتبة هي مساحة العمل الأساسية للبيانات الجدولية. تعلم كيف تحمل ملفات CSV وتنظفها وتحسب إحصاءاتها وتدمج جداول مختلفة. معظم المشاريع الحقيقية تبدأ من هنا.
ثالثًا: Scikit-learn: مكتبة تضم معظم خوارزميات التعلم الآلي الكلاسيكية مع واجهة برمجية موحدة وبسيطة. ستتعلم هنا كيف تبني نماذج التصنيف والتنبؤ وكيف تقيّمها بشكل صحيح. هذا المستوى يؤهلك لكثير من وظائف تحليل البيانات.
رابعًا: PyTorch أو TensorFlow: حين تريد الانتقال إلى التعلم العميق والشبكات العصبية، تحتاج إلى أحد هذين الإطارين. PyTorch أصبح المفضل في الأوساث البحثية وكثير من الشركات الكبرى، بينما يبقى TensorFlow حاضرًا بقوة في بيئات الإنتاج. البداية بأي منهما جيدة، والمفاهيم قابلة للنقل بينهما.
أفضل 10 شركات تقدم مسارات مجانية معتمدة في تعلم الذكاء الاصطناعي
الشركات الواردة أدناه لا تقدم محتوى هامشيًا، بل مسارات صممها المهندسون الذين يبنون الأنظمة فعليًا. قيمة هذه المواد لا تقدَر حين تعلم أن من كتبها هم من يعملون يوميًا على حل أصعب مشكلات الذكاء الاصطناعي في العالم.
1. Anthropic

Anthropic شركة أمريكية متخصصة في أبحاث سلامة الذكاء الاصطناعي، تأسست عام 2021 على يد دريو باغت وداريو أموديي وعدد من الباحثين السابقين في OpenAI. تعد Anthropic من أبرز المختبرات البحثية في العالم في مجال بناء أنظمة ذكاء اصطناعي آمنة وموثوقة. نموذجها الرئيسي Claude ينافس أقوى النماذج اللغوية عالمياً، ويتميز بقدرته على اتباع التعليمات المعقدة والتعامل مع السياقات الطويلة جداً. هذا النموذج أصبح خياراً مفضلاً للشركات التي تعطي أولوية للسلامة والموثوقية في تطبيقاتها.
تقدم Anthropic للمطورين والباحثين توثيقاً تقنياً معمقاً يشرح فلسفة البناء، وطرق التفاعل مع النماذج، وأفضل الممارسات في هندسة الأوامر Prompt Engineering. هذا التوثيق نفسه يدرس في جامعات مرموقة مثل ستانفورد ومعهد ماساتشوستس للتكنولوجيا. كما ينشر فريق البحث في Anthropic أوراقاً بحثية مفتوحة تعمق الفهم النظري لمن يريد الغوص أكثر في آليات عمل النماذج اللغوية. وكل هذه المواد متاحة مجاناً على موقع الشركة الرسمي.
مسار التعلم عبر Anthropic يمنحك فهماً حقيقياً لكيفية عمل نماذج اللغة الكبيرة من الداخل، وكيفية استخدام الـ API بكفاءة، وكيفية بناء تطبيقات تعتمد على هذه النماذج. هذه المعرفة مطلوبة بشدة في سوق العمل الحالي، لأن الطلب على المطورين القادرين على توظيف النماذج اللغوية في تطبيقات حقيقية في ازدياد مستمر. الشركة تقدم أيضاً نماذج أولية تطبيقية يمكنك دراستها وتعديلها لتتناسب مع مشروعاتك الخاصة. تبدأ رحلتك مع Anthropic من خلال قراءة وثائقهم التقنية التي تشرح كل شيء خطوة بخطوة.
المميزات والعيوب وكيفية التقديم
المميزات:
- توثيق تقني استثنائي الجودة مكتوب بوضوح ودقة
- مرجعية بحثية عالية للأوراق المنشورة
- API متاح مجانًا بحد معين للتجربة والتطوير
- تغطية معمقة لأخلاقيات الذكاء الاصطناعي وسلامته
العيوب:
- لا يوجد مسار تعليمي منظم للمبتدئين بشكل كامل
- يتطلب مستوى تقنيًا مسبقًا لفهم معظم المحتوى البحثي
- الوصول الكامل إلى API بقيود تجارية
كيفية التقديم: توجه مباشرةً إلى anthropic.com وابدأ بقراءة التوثيق الرسمي في قسم Docs، يمكنك التسجيل للحصول على مفتاح API مجاني والبدء ببناء تجارب حقيقية مع نموذج Claude.
2. Google

Google لا تحتاج إلى تعريف، لكن مساهمتها في تعليم الذكاء الاصطناعي أضخم مما يعرفه كثيرون. فالشركة التي نشرت ورقة Attention Is All You Need عام 2017، تقدم اليوم منظومة تعليمية متكاملة مجانية عبر عدة منصات. وهذه الورقة هي الأساس الذي بنيت عليه نماذج المحولات Transformers التي تقف خلف ChatGPT وكل نماذج اللغة الكبيرة الحديثة.
تقدم Google مسار Google AI for Everyone وMachine Learning Crash Course كنقطة بداية مثالية للمبتدئين. دورة Crash Course ألفها مهندسو Google أنفسهم وتقدم التعلم الآلي بأسلوب عملي مع أمثلة حقيقية من منتجات الشركة مثل Gmail وSearch. وتحتوي على تمارين تفاعلية تعمل في المتصفح، وتضم أكثر من 30 ساعة من المحتوى المجاني بالكامل.
منصة Google Cloud Skills Boost تقدم مسارات معتمدة في Vertex AI وخدمات الذكاء الاصطناعي السحابية مع تدريب عملي على أدوات الإنتاج الفعلية. يمكنك الحصول على شارات رقمية قابلة للإضافة إلى ملفك في LinkedIn، كما توفر Google مختبرات تفاعلية على سحابة حقيقية دون تكلفة إضافية.
المسار المعتمد من Google يعد من أكثر الشهادات قيمة في سوق العمل العالمي، خصوصاً لمن يريد العمل في بيئات سحابية كبيرة. هذه الشهادات معترف بها عالمياً وتفتح أبواباً مغلقة أمام المتعلمين العاديين. والتحضير لها لا يتطلب رسوماً باهظة، إذ يمكنك الاعتماد على المواد المجانية ودفع رسوم الامتحان فقط حين تشعر أنك جاهز.
مقالة ذات صلة: Google AI Overviews – نظرة عامة على الذكاء الاصطناعي بداية عصر لبحث جوجل.
المميزات والعيوب وكيفية التقديم
المميزات:
- محتوى شامل من المبتدئين إلى المتقدمين
- شهادات معتمدة لها وزن حقيقي في سوق العمل
- TensorFlow وKeras مدعومان بالكامل مع توثيق ممتاز
- Google Colab مجاني للبدء فورًا بدون إعداد بيئة محلية
العيوب:
- بعض المسارات المتقدمة تتطلب اشتراكًا مدفوعًا
- التنقل بين المنصات المختلفة (Coursera، Google Cloud، AI Hub) قد يُربك المبتدئ
كيفية التقديم: ابدأ من ai.google أو توجه مباشرةً إلى developers.google.com/machine-learning/crash-course للدورة المجانية الأساسية.
3. Meta AI

تحولت Meta في السنوات الأخيرة إلى لاعب محوري في أبحاث الذكاء الاصطناعي مفتوح المصدر على مستوى العالم. فنماذج Llama التي أصدرتها متاحة مجاناً للباحثين والمطورين، وتمثل فرصة حقيقية لدراسة بنية نماذج اللغة الكبيرة من الداخل. وهذا الانفتاح غير المسبوق جعل الجامعات ومراكز الأبحاث الصغيرة قادرة على العمل مع نماذج متقدمة. والنسخة الثالثة Llama 3 تعتبر حالياً من أقوى النماذج مفتوحة المصدر في العالم.
ينشر Meta AI Research أوراقاً بحثية وأكواداً مفتوحة المصدر بشكل منتظم، مما يجعله مورداً تعليمياً لا يقدر بثمن. والأكاديمية التعليمية التي تقدمها تشمل دورات في التعلم العميق والرؤية الحاسوبية ومعالجة اللغة الطبيعية على مستوى احترافي. وPyTorch نفسه بُني في مختبرات Meta AI قبل أن يتحول إلى مشروع مجتمعي مستقل، وهو اليوم أشهر إطار عمل للتعلم العميق. فتعلم PyTorch يعني أنك تتعلم الأداة التي تستخدمها أكبر الشركات التقنية في العالم.
ما يميز Meta هو المزج بين البحث النظري والتطبيق العملي على نطاق واسع لا تستطيعه شركة أخرى. فأنظمة Meta تعمل على بيانات حقيقية من مليارات المستخدمين يومياً عبر فيسبوك وإنستغرام وواتساب. والدروس المستخلصة من هذا النطاق تختلف تماماً عما هو متاح في أي بيئة أخرى. والمحتوى التعليمي القادم من Meta يحمل خبرة نادرة في التعامل مع البيانات الضخمة والسرعة الفائقة بشكل متزامن.
المبتدئون يمكنهم البدء بدورة Introduction to Large Language Models with Llama المتاحة مجاناً عبر منصات متعددة. وهذه الدورة تشرح كيف تبني تطبيقاً يعتمد على Llama من الصفر. أما المتقدمون فلهم مسارات متخصصة في Fine-tuning وتقنيات الاسترجاع المعزز RAG التي تحول النماذج العامة إلى نماذج متخصصة لمجالك. وكل هذه المواد مرتبطة بالنظام البيئي لـ PyTorch مما يسهل الانتقال من التعلم إلى التطبيق الفعلي.
المميزات والعيوب وكيفية التقديم
المميزات:
- PyTorch مدعوم بالكامل مع توثيق وفير
- نماذج Llama متاحة للدراسة والتعديل
- محتوى بحثي متقدم يصعب إيجاده في مكان آخر
- مجتمع مطورين نشط حول أدوات Meta المفتوحة
العيوب:
- المحتوى التعليمي المنظم أقل منهجية مقارنة بـ Google
- يتطلب مستوى تقنيًا مسبقًا لاستيعاب معظم المحتوى البحثي
كيفية التقديم: ابدأ من ai.meta.com وتصفح قسم Research والموارد المفتوحة. للوصول إلى نماذج Llama، توجه إلى llama.meta.com.
4. NVIDIA

NVIDIA ليست فقط شركة معالجات رسومية، بل أصبحت البنية التحتية الفعلية للذكاء الاصطناعي العالمي. فمعالجات GPU التي صممتها هي ما يشغل معظم نماذج الذكاء الاصطناعي الكبيرة من GPT إلى Llama وGemini. وهذا الموقع المحوري أعطاها خبرة فريدة لا تمتلكها أي شركة أخرى، لأنها ترى تحديات الذكاء الاصطناعي من طبقة الأجهزة نفسها. فالتعلم من NVIDIA يعني التعلم من الشركة التي تفهم أداء الذكاء الاصطناعي أفضل من أي كيان آخر.
NVIDIA Deep Learning Institute DLI هو الذراع التعليمية الرسمية، ويقدم دورات في التعلم العميق والرؤية الحاسوبية وتسريع التطبيقات بمستوى احترافي. وكثير من هذه الدورات مجانية بالكامل أو بتكاليف رمزية، وبعضها يتضمن مختبرات عملية على كروت الشاشة GPUS حقيقية في السحابة. والشهادات المعتمدة من NVIDIA لها قيمة عالية في شركات السيارات ذاتية القيادة ومراكز الأبحاث وشركات التكنولوجيا الكبرى. وهذه الشهادات تفتح أبواب وظائف متخصصة بأجور مرتفعة.
ما يميز مواد NVIDIA هو التركيز الشديد على جانب الأداء والتحسين الذي تهمله معظم الدورات الأخرى. فأنت تتعلم ليس فقط كيف تبني النماذج، بل كيف تجعلها تعمل بكفاءة على الأجهزة الحقيقية في حدود الذاكرة والطاقة والزمن المتاحة. وهذه المهارة التي تجمع بين الخوارزميات والأجهزة نادرة جداً في السوق ومطلوبة بشدة. فالشركات تبحث عن مهندس يشغل نموذجاً بتكلفة 100 دولار لا ألف دولار.
للمبتدئين تنصح NVIDIA بالبدء بدورة Fundamentals of Deep Learning التي تشرح كل شيء من الصفر مع أمثلة عملية. وبعد إتقان الأساسيات يمكن الانتقال إلى مسارات متخصصة مثل Accelerating Data Science و Building Transformer Models التي تغطي أحدث الأبحاث. وكل دورة في DLI تأتي مع بيئة مختبر معدة مسبقاً، مما يعني أنك لن تضيع وقتاً في إعداد الأدوات.
المميزات والعيوب وكيفية التقديم
المميزات:
- خبرة لا مثيل لها في تحسين الأداء وتسريع النماذج
- شهادات معتمدة ذات قيمة في سوق المؤسسات
- محتوى تقني عميق حول CUDA والتوازي الحسابي
- دورات مجانية بشكل دوري عبر برامج خاصة
العيوب:
- معظم المحتوى المتميز مدفوع
- مناسب أكثر للمستويات المتوسطة والمتقدمة
كيفية التقديم: توجه إلى learn.nvidia.com وابحث عن الدورات المجانية في قسم Free Courses.
5. Microsoft

دمجت Microsoft الذكاء الاصطناعي في منتجاتها بشكل ثوري، واستثمارها في OpenAI جعلها شريكاً استراتيجياً في تطوير أقوى نماذج اللغة مثل GPT-4. وتعلم الذكاء الاصطناعي عبر Microsoft يمنحك وصولاً إلى أحدث التكنولوجيا اللغوية في العالم. ومنصة Microsoft Learn هي واحدة من أكثر المنصات التعليمية شمولاً وتنظيماً، وهي مجانية بالكامل. كل ما تحتاجه هو حساب Microsoft مجاني وتبدأ رحلة التعلم فوراً.
مسارات الذكاء الاصطناعي على Microsoft Learn تغطي من أساسيات التعلم الآلي إلى خدمات Azure Cognitive Services للرؤية الحاسوبية والترجمة الفورية. كما تصل إلى بناء التطبيقات الذكية على السحابة واستضافة نماذجك الخاصة بموثوقية Enterprise. والشهادات المعتمدة مثل AI-900 و DP-100 لها وزن كبير في المؤسسات الكبرى. ومواد التحضير لهذه الشهادات متاحة مجاناً على Microsoft Learn نفسها.
يضاف إلى ذلك المحتوى المرتبط بـ GitHub Copilot والأدوات المدمجة في Visual Studio Code، مما يجعل التعلم أكثر ارتباطاً بالعمل الفعلي للمطورين. فبدلاً من النظرية فقط، ستتعلم كيف تستخدم الذكاء الاصطناعي كمساعد حقيقي في كتابة الكود. وتقدم Microsoft أيضاً مختبرات تفاعلية على Azure for Students بأرصاد مجانية تصل إلى 100 دولار شهرياً. وهذا المزيج بين التعلم المجاني والأرصاد السحابية لا تجده مجتمعاً في أي منصة أخرى.
للمبتدئين تبدأ رحلتك بمسار Get started with AI on Azure المصمم خصيصاً لمن ليس لديهم خلفية تقنية عميقة. ثم يمكنك الانتقال إلى مسار Build intelligent applications with Azure AI الذي يدمج رؤية الكمبيوتر ومعالجة اللغة والكلام. وكل مسار يحتوي على وحدات، كل وحدة تأخذ بين 20 و45 دقيقة. وهذا يسمح لك بالتعلم في فترات قصيرة يومياً دون الشعور بالإرهاق.
المميزات والعيوب وكيفية التقديم
المميزات:
- منصة Learn مجانية بالكامل مع مسارات منظمة
- شهادات Azure AI معتمدة ومطلوبة في سوق المؤسسات
- تكامل عميق مع أدوات التطوير المعروفة
- محتوى بالعربية في بعض الأجزاء
العيوب:
- بعض المحتوى مرتبط بخدمات Azure المدفوعة
- الشهادات تتطلب اختبارات ذات رسوم
كيفية التقديم: ابدأ من learn.microsoft.com/ai وابحث عن مسار AI Fundamentals المجاني.
6. OpenAI

حولت OpenAI مجال الذكاء الاصطناعي من مختبرات الأبحاث المغلقة إلى منتجات يستخدمها الملايين يومياً. فما كان حكراً على الباحثين أصبح الآن في متناول أي شخص بفضل نماذج مثل GPT و DALL-E و Whisper. وهذه الشركة التي بدأت كمنظمة غير ربحية أصبحت اليوم القاطرة التي تقود ثورة النماذج اللغوية الكبيرة. فالتعلم من أدوات OpenAI يعني أنك تتعلم من السباق الأول في هذا المجال تحديداً.
التوثيق التقني للـ API والنماذج من OpenAI يعد مرجعاً أساسياً لكل مطور يعمل مع نماذج اللغة الكبيرة. و OpenAI Cookbook هو مستودع مفتوح ومجاني يحتوي على أمثلة عملية لأنماط استخدام متقدمة للـ API. وفر هذا المصدر الكثير من الوقت على آلاف المطورين، لأنه يقدم حلولاً جاهزة لمشكلات حقيقية. كما تنشر OpenAI أوراقاً بحثية تشرح بنية نماذجها لمن يريد الفهم العميق.
مسار التعلم عبر OpenAI يناسب من يريد بناء تطبيقات على GPT أو DALL-E أو Whisper، وهذا القطاع آخذ في النمو الملحوظ بسوق العمل. فالشركات تبحث عن مطورين يعرفون كيف يصممون الأوامر Prompt Engineering بدقة، وكيف يبنون تطبيقات متعددة الخطوات. وتوفر OpenAI كل هذا في مكان واحد: وثائق تقنية، وأكواد أمثلة، ومنتدى مجتمعياً ضخماً. وهذا النظام البيئي يجعل تعلم أدوات OpenAI أسرع من أي تقنية أخرى.
المبتدئون يبدأون بـ دورة Introduction to AI على منصة DeepLearning.AI بالشراكة مع OpenAI، وهي مجانية وتشرح الأساسيات ثم تنتقل للتطبيق العملي. وبعد ذلك يمكن استكشاف OpenAI Cookbook على GitHub حيث تجد نماذج لتلخيص المستندات وتحليل المشاعر وتوليد الشيفرات البرمجية. وأيضاً منصة platform.openai.com توفر Playground لتجربة النماذج مباشرة في المتصفح. هذه الأدوات المجانية تجعل التعلم سلساً حتى لمن ليس لديهم خلفية برمجية عميقة.
المميزات والعيوب وكيفية التقديم
المميزات:
- API موثق بشكل ممتاز مع أمثلة عملية وافرة
- OpenAI Cookbook مصدر مجاني لا يُقدَّر بثمن
- أوراق بحثية تشرح GPT-4 وما قبله بتفصيل علمي
- مجتمع مطورين ضخم وداعم
العيوب:
- الاستخدام الفعلي للـ API مدفوع بعد حد مجاني محدود
- لا يوجد مسار تعليمي منظم للمبتدئين
كيفية التقديم: ابدأ من platform.openai.com/docs وتصفح Cookbook من cookbook.openai.com.
7. IBM

IBM من أعرق الشركات في مجال الذكاء الاصطناعي، ونظامها Watson كان رائداً في التطبيقات المؤسسية منذ سنوات طويلة. واليوم تقدم IBM منظومة تعليمية شاملة عبر منصة IBM SkillsBuild التي تستهدف صراحة الداخلين الجدد لسوق العمل. هذه المنصة مجانية بالكامل وتحتوي على مسارات متكاملة تشمل فيديوهات وتمارين تفاعلية ومشاريع تطبيقية. وهي مصممة خصيصاً لتحويل المبتدئين إلى مرشحين جاهزين للعمل في المؤسسات الكبرى.
مسارات IBM في الذكاء الاصطناعي وتعلم الآلة تقدم بالشراكة مع Coursera وتشمل شهادات مهنية مجانية أو بأسعار رمزية. و IBM Data Science Professional Certificate و IBM AI Engineering Professional Certificate من بين أكثر الشهادات طلباً من قبل أصحاب العمل على LinkedIn. وهذه الشهادات لا تتطلب خلفية تقنية عميقة للبدء، وتأخذ حوالي 3 إلى 6 أشهر لإكمالها بمعدل 5 ساعات أسبوعياً. والمواد مصممة على يد مهندسي IBM الذين يعملون على Watson وغيره من المنتجات الحقيقية.
ما يميز IBM هو التركيز على الجانب المؤسسي والحوكمة وتطبيقات الذكاء الاصطناعي في بيئات الأعمال الكبيرة. فمحتوانا مناسب بشكل خاص لمن يسعى إلى العمل في المؤسسات الكبيرة والقطاع المصرفي والحكومي والصحي. كما تغطي مسارات IBM موضوعات نادرة مثل الذكاء الاصطناعي الموثوق والشفاف وتفسير النماذج وتوثيقها للجهات التنظيمية. وهذه المهارات مطلوبة جداً في الشركات التي تخضع لرقابة صارمة مثل البنوك وشركات التأمين.
للمبتدئين تبدأ رحلة IBM بمسار AI Fundamentals المجاني على SkillsBuild والذي لا يتطلب أي خبرة برمجية سابقة. وبعد إتقان الأساسيات يمكن الانتقال إلى مسار Applied AI الذي يشرح كيفية بناء تطبيقات ذكاء اصطناعي حقيقية باستخدام Watson وخدمات IBM السحابية. وكل مسار يمنح شارة رقمية قابلة للإضافة إلى ملفك المهني على LinkedIn.
المميزات والعيوب وكيفية التقديم
المميزات:
- شهادات مهنية موثوقة ومطلوبة في سوق المؤسسات
- تغطية ممتازة للجانب المؤسسي وحوكمة البيانات
- IBM SkillsBuild يقدم محتوى مجانيًا للفئات المستهدفة
- شراكة مع Coursera تتيح إمكانية الحصول على مساعدة مالية
العيوب:
- بعض الشهادات المميزة تتطلب اشتراكًا في Coursera
- المحتوى أكثر توجهًا للمستوى المؤسسي مما يناسب المبتدئين
كيفية التقديم: ابدأ من skillsbuild.org للمحتوى المجاني، أو ابحث عن “IBM AI” في coursera.org للشهادات المهنية.
8. AWS (Amazon Web Services)

تهيمن AWS على سوق الحوسبة السحابية عالمياً، وخدمات الذكاء الاصطناعي التي تقدمها من بين الأشمل والأوسع انتشاراً في المؤسسات. فمن SageMaker لتدريب النماذج، إلى Rekognition للرؤية الحاسوبية، إلى Comprehend لمعالجة اللغة الطبيعية. وتقدم AWS بنية تحتية كاملة للذكاء الاصطناعي يستخدمها مئات آلاف الشركات حول العالم. وهذا يعني أن تعلم AWS يجعلك مؤهلاً للعمل في أكبر بيئة سحابية على وجه الأرض.
AWS Skill Builder هو منصة التعلم الرسمية، وتوفر عشرات الدورات المجانية في الذكاء الاصطناعي والتعلم الآلي بمستويات متنوعة. ويمكنك الوصول إلى مختبرات تفاعلة على بيئة AWS الحقيقية دون أي تكلفة إضافية من خلال حساب Free Tier. والشهادة المعتمدة AWS Certified Machine Learning Specialty تعتبر من أعلى الشهادات قيمة في السوق. وتأثيرها على الراتب وفرص العمل مباشر وملموس وفقاً لجميع استبيانات الرواتب التقنية السنوية.
التعلم عبر AWS يناسب بشكل خاص من يريد العمل في الشركات التي تعتمد على البنية السحابية، وهذا هو النمط السائد في معظم الشركات التقنية الكبيرة اليوم. فمعظم المؤسسات لا تشغل نماذجها على أجهزتها المحلية، بل على سحابة AWS أو منافسيها. وستتعلم مهارات عملية مثل استضافة النماذج وتشغيلها ومراقبتها على نطاق واسع يخدم آلاف المستخدمين. وهذه المهارات نادرة ومطلوبة بشدة لأن معظم المتعلمين يتوقفون عند بناء النموذج ولا يصلون إلى مرحلة نشره في الإنتاج.
المميزات والعيوب وكيفية التقديم
المميزات:
- منصة Skill Builder تقدم محتوى مجانيًا وافرًا
- شهادات ذات تأثير مباشر ومُثبَت على الراتب
- تغطية شاملة لخدمات الذكاء الاصطناعي السحابية
- AWS Free Tier يتيح التجربة العملية مجانًا
العيوب:
- المحتوى المتقدم مرتبط بالخدمات المدفوعة
- التركيز على بيئة AWS قد يحد من قابلية النقل
كيفية التقديم:
للمبتدئين تبدأ الرحلة بدورة Getting Started with Machine Learning المجانية على AWS Skill Builder، وهي لا تتطلب أي خبرة سابقة. وبعد ذلك يمكن الانتقال إلى مسار Machine Learning Pipeline الذي يشرح كل مرحلة من جمع البيانات إلى نشر النموذج. وتقدم AWS أيضاً مبادرة AI & ML Scholarship Program للطلاب والمبتدئين مجاناً بالكامل مع مرشدين متخصصين. تبدأ كل شيء عبر aws.amazon.com/training واختيار قسم Machine Learning لتجد مواد منظمة حسب المستوى والمسار الوظيفي المستهدف.
9. DeepLearning.AI

أسس DeepLearning.AI العالم أندرو نغ Andrew Ng، وهو أحد أبرز علماء الذكاء الاصطناعي في العالم والمعلم الأكثر تأثيراً في تاريخ تعليم هذا المجال. فدورة Machine Learning Specialization التي يقدمها على Coursera أتمها أكثر من خمسة ملايين شخص حول العالم، وهذا الرقم وحده يختصر حجم تأثيرها الهائل. وأندرو نغ هو المؤسس المشارك لـ Coursera، والقائد السابق لـ Google Brain و Baidu AI. وباختصار، أنت هنا تتعلم من شخص صنع تاريخ الذكاء الاصطناعي الحديث بيديه، وليس من مدرب عادي.
ما يميز DeepLearning.AI هو قدرة أندرو نغ الاستثنائية على تبسيط المفاهيم المعقدة دون إفقادها دقتها العلمية العميقة. فدوراته تمزج بين النظرية والتطبيق العملي بتوازن نادر لا تجده في أي منصة أخرى على الإطلاق. ومسار Deep Learning Specialization يغطي الشبكات العصبية، والشبكات التلافيفية CNN، والشبكات المتكررة RNN، والمحولات Transformer. أما مسار MLOps Specialization فيركز على كيفية إدارة دورة حياة النماذج في بيئة الإنتاج الفعلية، وهي مهارة نادرة ومطلوبة جداً.
من المسارات القوية جداً أيضاً LLMs with Semantic Search الذي يشرح كيفية بناء تطبيقات بحث دلالي باستخدام نماذج اللغة الكبيرة. ومسار Generative AI with LLMs يعد من أحدث المسارات وأكثرها طلباً في سوق العمل الآن وفي السنوات القادمة. وتغطي DeepLearning.AI موضوعات متقدمة مثل Fine-tuning و RAG و Prompt Engineering بمستوى عملي لا توفره أي منصة أخرى بنفس العمق والوضوح. وجميع هذه المسارات مصممة لتكون عملية بشكل أساسي، وتمنحك مشاريع حقيقية يمكنك إضافتها مباشرة إلى محفظة أعمالك الشخصية.
المميزات والعيوب وكيفية التقديم
المميزات:
- أفضل جودة تعليمية لتبسيط التعلم العميق للمبتدئين
- مسارات متكاملة تغطي من الأساسيات إلى المتقدم
- مساعدة مالية متاحة للحصول على الشهادات مجانًا
- محتوى محدَّث بانتظام ليواكب آخر التطورات
العيوب:
- الشهادة المدفوعة ضرورية للاستفادة الكاملة من المنصة
- بعض المسارات تستغرق وقتًا أطول مما يتوقعه المبتدئون
كيفية التقديم:
معظم دورات DeepLearning.AI على Coursera يمكن مراجعتها مجاناً بالكامل دون أي قيود، والشهادة مدفوعة برسوم رمزية ومعقولة جداً. ويمكنك أيضاً الحصول على الشهادة مجاناً تماماً عبر برنامج المساعدة المالية من Coursera الذي توافق عليه المنصة بنسبة 95% من الطلبات تقريباً.
وتوجد قناة DeepLearning.AI على YouTube تحتوي على مئات المقاطع القصيرة والمجانية التي تشرح المفاهيم الأساسية بطريقة مبسطة. تبدأ رحلتك ببساطة بالبحث عن Andrew Ng على منصة Coursera، واضغط على “Audit” لمراجعة المحتوى مجانًا، أو “Financial Aid” للحصول على الشهادة مجانًا.
10. Hugging Face

تحولت Hugging Face خلال سنوات قليلة من مجرد مكتبة Python إلى المنصة المرجعية العالمية لنماذج الذكاء الاصطناعي مفتوحة المصدر. يضم مستودعها الآن أكثر من نصف مليون نموذج متاح للتنزيل والاستخدام والتعديل بحرية. بالإضافة إلى آلاف مجموعات البيانات المفتوحة التي تغطي كل لغة ومجال تقريباً. ولهذا السبب يطلق عليها مجتمع الذكاء الاصطناعي اسم GitHub للنماذج، لأن كل باحث ومطور يستخدمها يومياً.
دورات Hugging Face المجانية تعد من أفضل المصادر المتاحة لمن يريد تعلم تقنيات المحولات Transformers ونماذج اللغة الكبيرة. فالدورات تغطي ضبط النماذج الدقيق Fine-tuning، وتوليد النصوص، والترجمة الآلية، والإجابة على الأسئلة، وتحليل المشاعر، وغيرها الكثير. والمحتوى مكتوب بلغة بسيطة وواضحة مع كود قابل للتشغيل مباشرة في Google Colab دون الحاجة إلى أي تجهيزات محلية. وتوجد نسخة كاملة من هذا الكورس باللغة العربية أيضاً على موقعهم الرسمي.
ما يجعل Hugging Face استثنائياً هو أنك لا تتعلم مجرد نظرية أكاديمية جافة، بل تتعامل مع النماذج الفعلية التي يستخدمها الباحثون والمطورون حول العالم يومياً. وهذا التوافق المباشر بين البيئة التعليمية وبيئة العمل الحقيقية نادر جداً ومهم للغاية لبناء الكفاءة القابلة للاستثمار فوراً. فما تدرسه في الدورة هو نفسه ما ستستخدمه في وظيفتك المستقبلية دون أي فجوة. وهذا يختصر وقت الانتقال من التعلم إلى الإنتاج بشكل كبير جداً.
للمبتدئين يبدأ المسار بدورة NLP Course المجانية التي تشرح المحولات من الصفر مع تمارين تفاعلية خطوة بخطوة. وبعد إتقان الأساسيات يمكن الانتقال إلى Hugging Face Cookbook الذي يحتوي على عشرات الأمثلة التطبيقية لمشكلات حقيقية. كما توفر المنصة نموذج Spaces المجاني لتجربة أي نموذج في المتصفح مباشرة دون كتابة أي كود.
المميزات والعيوب وكيفية التقديم
المميزات:
- دورات مجانية بالكامل مع كود قابل للتشغيل
- أكبر مستودع نماذج مفتوحة المصدر في العالم
- مجتمع نشط ومتعاون للغاية
- تحديثات مستمرة تواكب أحدث النماذج
العيوب:
- يتطلب مستوى Python جيدًا للاستفادة الكاملة
- المحتوى يفترض خلفية تقنية أساسية مسبقة
كيفية التقديم: توجه إلى huggingface.co/learn وابدأ بـ NLP Course أو Diffusion Models Course وفق اهتمامك.
جدول مقارنة الشهادات والمسارات التعليمية للذكاء الاصطناعي
| # | الشركة / المنصة | اسم الشهادة / المسار الأبرز | مستوى المتطلب | التكلفة | الميزة الأقوى | الجهة المستهدفة |
|---|---|---|---|---|---|---|
| 1 | Anthropic | توثيق API + Prompt Engineering | متوسط (خبرة برمجية) | مجاني بالكامل | فهم عمق أمان النماذج وتقنيات الاستدعاء | مطورو تطبيقات LLM |
| 2 | Professional ML Engineer | متوسط إلى متقدم | رسوم امتحان (حوالي 200$) | أعلى انتشار في سوق العمل | مهندسو ML في السحابة | |
| 3 | Meta AI | PyTorch + Llama Courses | مبتدئ إلى متوسط | مجاني بالكامل | التعلم من مطوري PyTorch أنفسهم | باحثون ومطورو نماذج مفتوحة المصدر |
| 4 | NVIDIA | DLI Certificates (مثل Fundamentals of DL) | مبتدئ إلى متقدم | مجاني / رمزي (50-150$) | التركيز على الأداء والتحسين على GPU | مهندسو تحسين الأداء والتعلم العميق |
| 5 | Microsoft | AI-900 (Azure AI Fundamentals) و DP-100 | مبتدئ (AI-900) إلى متوسط (DP-100) | 99-165$ لكل امتحان | التكامل الكامل مع أدوات المؤسسات (Azure) | محترفو السحابة والشركات الكبرى |
| 6 | OpenAI | Cookbook + API Documentation | متقدم (برمجة متوسطة فما فوق) | مجاني (التوثيق) + رسوم API | التعلم من صانعي GPT وDALL-E | مطورو تطبيقات تعتمد على LLMs |
| 7 | IBM | IBM AI Engineering Professional Certificate | مبتدئ (بعد أساسيات Python) | مجاني (audit) أو رسوم رمزية على Coursera | التركيز على الحوكمة والقطاع المؤسسي | العاملون في البنوك والحكومة والرعاية الصحية |
| 8 | AWS (Amazon Web Services) | AWS Certified Machine Learning – Specialty | متقدم (خبرة سحابية سنتين) | 300$ تقريباً | الأعلى أجراً وفق استبيانات الرواتب | مهندسو ML في البيئات السحابية الكبيرة |
| 9 | DeepLearning.AI | Deep Learning Specialization | مبتدئ (بعد أساسيات ML) | مجاني (audit) أو 49$/شهراً | تبسيط استثنائي من أندرو نغ | كل من يريد فهماً عميقاً وعملياً من الصفر |
| 10 | Hugging Face | NLP Course + Cookbook | مبتدئ (معرفة أساسية بـ Python) | مجاني بالكامل + مختبرات على Colab | التطابق بين التعليم وبيئة الإنتاج الحقيقية | مطورو ومحللوا النماذج مفتوحة المصدر |
ملخص سريع للتوصيات حسب الهدف
| إذا كنت تريد… | فابدأ بـ… |
|---|---|
| أسهل بداية مجانية ولا تحتاج خبرة | DeepLearning.AI + Hugging Face |
| شهادة معترف بها في كل مكان لسيرتك الذاتية | Google Professional ML Engineer |
| أعلى راتب متوقع في السوق | AWS Certified ML Specialty |
| فهم النماذج اللغوية الكبيرة بعمق | Anthropic (التوثيق) + OpenAI (Cookbook) |
| التخصص في الأداء والسرعة على الأجهزة | NVIDIA DLI |
| العمل في القطاع الحكومي أو البنوك الكبرى | IBM AI Engineering |
| التعلم من صانع PyTorch نفسه | Meta AI (PyTorch + Llama) |
| الاندماج مع بيئة Microsoft في شركة كبرى | Microsoft Azure AI (AI-900 ثم DP-100) |
الأخطاء القاتلة التي تحوّل تعلم الذكاء الاصطناعي إلى مضيعة للوقت
الخطأ الأول الأكثر شيوعًا وتكلفة
هو ما يعرف بمتلازمة تكديس الدورات التدريبية. إذ يلتحق الشخص بدورة تدريبية، ويكمل جزءًا منها، ثم يبحث عن أخرى تبدو أفضل، فيبدأ بها، ثم يبحث عن ثالثة ورابعة. بعد ستة أشهر، يكون قد شاهد عشرات الساعات من محتوى متفرق دون أن يُطبّق أي شيء عمليًا. تصيب هذه المشكلة 80% من المتعلمين الجدد، وهي السبب الرئيسي للانسحاب من المجال والتخلي عنه نهائيًا. يُعدّ إكمال الدورة والتطبيق العملي أهم بكثير من اختيار الدورة أو المورد الأمثل.
الخطأ الثاني التركيز على الأدوات
أما التركيز على الأدوات دون فهم أساسياتها فهو ثاني أكثر الأخطاء تدميرًا للفعالية على المدى الطويل. يسارع الكثيرون إلى تعلم أحدث المكتبات والنماذج مثل LangChain وLlamaIndex دون فهم آلية عملها. يجد هؤلاء أنفسهم عاجزين تمامًا عندما تتغير الأدوات بعد عام، أو عندما يواجهون مشكلة خارج نطاق ما درسوه. والسبب في ذلك هو أن الأسس الرياضية والمفاهيمية تبقى ثابتة لسنوات، بينما تتغير الأدوات كل بضعة أشهر. من يفهم “السبب” يستطيع تعلم أي “كيفية” جديدة في أيام بدلًا من شهور.
الخطأ الثالث لتعلم دون هدف
هو التعلم دون هدف محدد ودون مشكلة حقيقية تدفعك للأمام. التعلم العام دون توجيه واضح سيقودك إلى منتصف الطريق في كل اتجاه، لكنه لن يوصلك إلى نهاية أي طريق. لذا، حدد مجالًا تطبيقيًا يثير اهتمامك شخصيًا، سواء كان تحليل البيانات في قطاع الرعاية الصحية، أو بناء روبوتات محادثة لخدمة العملاء، أو تحليل الصور الطبية للتشخيص المبكر. هذا الهدف المحدد يمنح تعلمك معنى وسياقًا حقيقيين، ويسهل عليك التمييز بين ما يستحق وقتك وما لا يستحقه. بدون هدف، ستجد نفسك تائهًا في بحر من الموارد بلا بوصلة.
الخطأ الرابع الخوف من استخدام واجهات برمجة التطبيقات (APIs)
الخوف من استخدام واجهات برمجة التطبيقات (APIs) والانتظار حتى “تتقن” مهاراتك قبل بناء أي شيء حقيقي. يقضي الكثيرون شهورًا في دراسة النظريات قبل كتابة سطر واحد من التعليمات البرمجية التي تستدعي نموذجًا واقعيًا. الحقيقة هي أن التعلم الفعال يأتي من البناء التكراري، وليس من إكمال المنهج ثم البدء في البناء.
استخدم واجهة برمجة تطبيقات جوجل للتعلم الآلي اليوم، وابنِ مشروعًا صغيرًا، حتى لو كان متواضعًا، وحسّنه تدريجيًا. هذا النهج العملي التكراري هو ما يصنع مهندسي الذكاء الاصطناعي الحقيقيين، وليس مجرد إكمال دورات نظرية بشكل سلبي.
تجنب هذه الأخطاء الأربعة وركز على التعلم العملي القائم على المشاريع. افهم الأساسيات، لا الأدوات فقط، وضع هدفًا واضحًا وموجّهًا. استخدم أدوات واقعية مباشرةً من اليوم الأول. سيوفّر لك هذا المسار مئات الساعات الضائعة ويحقّق نتائج ملموسة في ثلث الوقت الذي يستغرقه المتعلّم العادي.
كيف تبني مشروعك التطبيقي الأول خلال 30 يوماً من بدء تعلم الذكاء الاصطناعي
المشروع الأول في تعلم الذكاء الاصطناعي
لا يحتاج أن يكون ثورياً أو يغير قواعد اللعبة في مجالك، بل يحتاج أن يكون حقيقياً وقابلاً للعرض أمام صاحب عمل أو عميل محتمل. فالفرق بين من يقدم نفسه بمشروع حقيقي يعمل ويعطي نتائج، وبين من يقدم شهادات إتمام دورات فقط، هذا الفرق ضخم جداً في سوق العمل. ولذلك أول نصيحة: إكمال مشروع واحد حتى النهاية أفضل من بدء عشرة مشاريع وتركها نصف مكتملة.
الأسبوع الأول في تعلم الذكاء الاصطناعي
حدد مشكلة بسيطة ومحددة لتضرب فيها حجر الأساس. ولا تبدأ بعبارة طموحة مثل “أريد بناء نظام توصيات مثل Netflix”. بل ابدأ بعبارة واضحة مثل “أريد نموذجاً يتوقع أسعار السكن في مدينتي” أو “نموذجاً يصنف تعليقات العملاء إيجابية أو سلبية”. فالمشكلة الصغيرة التي تنجزها بالكامل أفضل بأضعاف من المشكلة الكبيرة التي تبدأها ثم تتركها في المنتصف. والهدف هنا هو الوصول إلى نقطة النهاية خلال أيام محدودة، لا أن تغرق في بحر من التفاصيل.
الأسبوع الثاني في تعلم الذكاء الاصطناعي
اجمع البيانات ونظفها وحضرها جيداً قبل أن تفكر في أي نموذج. وهذه المرحلة ستأخذ وقتاً أطول مما تتوقع، لأن البيانات الحقيقية دائماً فوضوية وناقصة وتحتوي على شذوذات لا تخطر على البال. استخدم مصادر مجانية موثوقة مثل Kaggle و UCI Machine Learning Repository و Hugging Face Datasets. ثم نظف البيانات من القيم المفقودة والمكررة، واستكشفها بصرياً باستخدام Matplotlib وSeaborn. وحاول أن تفهم ما تخبرك به البيانات قبل أن تدخلها في أي نموذج.
الأسبوع الثالث من تعلم الذكاء الاصطناعي
ابنِ النموذج الأبسط أولاً ثم حسّنه تدريجياً. ولا تبدأ بالتعلم العميق والشبكات العصبية متعددة الطبقات مباشرة، فهذا يؤدي إلى تعقيد غير ضروري ويصعب تتبعه وتصحيحه. بل ابدأ بـ الانحدار الخطي Linear Regression أو شجرة القرار Random Forest أو الانحدار اللوجستي Logistic Regression حسب طبيعة مشكلتك. ثم قيم النتائج باستخدام مقاييس مناسبة، وافهم لماذا يخطئ النموذج في بعض الحالات. ثم حاول تحسينه خطوة بخطوة بإضافة بيانات أفضل أو اختيار معاملات أدق أو تجربة نموذج أكثر تعقيداً بقليل.
الأسبوع الرابع في تعلم الذكاء الاصطناعي
اعرض نتائجك على الآخرين بشكل منظم ومقنع. ويمكن أن يكون ذلك مقالاً بسيطاً على LinkedIn يشرح ما فعلته، أو مستودع GitHub منظماً مع توثيق واضح، أو عرضاً قصيراً من 5 إلى 10 شرائح تقدمه لزملائك. فالمشاركة العلنية لعملك تجبرك على فهم ما فعلته حقاً بعمق، وتبني حضورك المهني في الوقت ذاته. وأفضل المخرجات التي تضعها هي: مستودع GitHub منظم، ودفتر Jupyter يشرح كل خطوة، ورسوم بيانية تعرض النتائج بوضوح، وفقرة قصيرة تصف المشكلة ونهجك والنتائج التي وصلت إليها.
هل تعلم الذكاء الاصطناعي كافٍ في سوق العمل؟
الجواب القصير: لا. أما الجواب الصحيح فهو: يعتمد على ما تعنيه بـ تعلم الذكاء الاصطناعي تحديداً. فإذا كانت إجابتك أنك أتممت دورة أو اثنتين وتعلمت استخدام Scikit-learn، فهذا المستوى مجرد نقطة انطلاق لا أكثر. وسوق العمل الحقيقي لا يبحث عن من يعرف قليلاً من كل شيء، بل يبحث عن من يتقن شيئاً واحداً بعمق. فالشركات اليوم تدفع رواتب عالية للمتخصص، وتبحث عن العام فقط للوظائف المبتدئة محدودة النطاق والراتب.
ما يقدر فعلياً في سوق العمل هو القدرة على حل مشكلة محددة بشكل موثوق وقابل للصيانة والتوسع. وهذا يتطلب عمقاً في منطقة واحدة على الأقل، سواء كانت نماذج اللغة الكبيرة LLMs، أو الرؤية الحاسوبية Computer Vision، أو التعلم المعزز Reinforcement Learning، أو الأنظمة التوصية Recommendation Systems، أو معالجة الإشارات الصوتية. فالشخص الذي يعرف كل مجال بشكل سطحي أقل قيمة من الشخص الذي يحل مشكلة حقيقية في مجال واحد بإتقان.
الخلاصة العملية: تعلم الذكاء الاصطناعي هو أساس ضروري لكنه غير كافٍ للنجاح في سوق العمل بمفرده. فأنت بحاجة بعد إتقان الأساسيات إلى اختيار تخصص فرعي، ثم بناء محفظة مشاريع متعمقة فيه، ثم متابعة التحديثات المستمرة لأن المجال يتطور أسبوعياً. ومن يفعل هذا يصبح مؤهلاً للعمل، ومن يكتفي بالدورات العامة يظل في خانة المبتدئين لفترة طويلة جداً.
تعلم أساسيات الشبكات العصبية
الشبكات العصبية الاصطناعية (Artificial Neural Networks – ANNs) هي العمود الفقري للتعلم العميق، وفهمها الحقيقي يجعلك مختلفاً عن كثيرين. فالشبكة العصبية في جوهرها تحويلات رياضية متعاقبة تتعلم تمثيلات البيانات عبر الانتشار الخلفي Backpropagation. وهذا الفهم العميق سيجعلك قادراً على تشخيص مشكلات النماذج وحلها بنفسك. أما من يستخدمها كصندوق أسود فسيظل عاجزاً أمام أي خطأ غير مألوف.
ما يجب فهمه في هذا المستوى يشمل بنية الشبكة من طبقات إدخال ومخفية وإخراج، ودوال التنشيط مثل ReLU وSigmoid وSoftmax مع معرفة سياق استخدام كل منها. ويشمل أيضاً الانتشار الأمامي والخلفي لفهم كيف تتدفق البيانات وكيف تتحدث الأوزان. إضافة إلى تنظيم النموذج عبر Dropout وBatch Normalization وL2 Regularization. وأخيراً إشكاليات التدريب مثل Overfitting وUnderfitting وVanishing Gradients.
بإختصار ما يجب فهمه في هذا المستوى:
- بنية الشبكة: طبقات الإدخال والمخفية والإخراج
- دوال التنشيط: ReLU, Sigmoid, Softmax وسياق استخدام كل منها
- الانتشار الأمامي والخلفي: كيف تتدفق البيانات وكيف تتحدث الأوزان
- تنظيم النموذج: Dropout, Batch Normalization, L2 Regularization
- إشكاليات التدريب: Overfitting, Underfitting, Vanishing Gradients
ضبط النماذج الكبيرة اللغوية LLMs
أصبح ضبط نماذج اللغة الكبيرة أحد أكثر المهارات طلباً في سوق العمل اليوم. فالضبط الدقيق Fine-tuning يعني تكييف نموذج مدرب مسبقاً لمهمة محددة باستخدام بيانات أقل بكثير من التدريب من الصفر. وهذا النهج وفر على الشركات ملايين الدولارات، ومنح المطورين المستقلين إمكانية بناء نماذج متخصصة بإمكانيات محدودة. فبدلاً من حاجة تدريب نموذج من الصفر إلى آلاف البطاقات، يمكنك ضبط نموذج جاهز خلال ساعات على جهاز واحد.
تقنية LoRA (Low-Rank Adaptation) حولت ضبط النماذج الكبيرة من مهمة تحتاج عشرات معالجات GPU إلى شيء يمكن إنجازه على جهاز واحد عادي. فهذه التقنية تضيف أوزاناً صغيرة قابلة للتدريب إلى النموذج بدلاً من تعديل كل الأوزان الأصلية. لذا فإن فهمها وتطبيقها عبر مكتبة PEFT من Hugging Face أصبح مهارة يجب أن تكون في قاموسك التقني. وإتقان هذه التقنية يجعلك قادراً على ضبط Llama أو Mistral أو Gemma بأقل الإمكانيات المتاحة.
تقنية RLHF (Reinforcement Learning from Human Feedback) هي ما حولت GPT-3 إلى ChatGPT، أي أنها جعلت النماذج أكثر توافقاً مع تعليمات البشر. وهذه التقنية تعتمد على جمع تفضيلات البشر لتوجيه النموذج نحو سلوك مرغوب وتجنب سلوك غير مرغوب. والإلمام بمبادئها وببديلاتها الأحدث مثل DPO (Direct Preference Optimization) يعد ميزة تنافسية حقيقية ممتازة. فالشركات اليوم تبحث عن متخصصين يستطيعون مواءمة النماذج مع قيم المؤسسة وسياساتها الخاصة.
مسارات متخصصة
التخصص ليس تضييقاً لخياراتك، بل هو تعميق لقيمتك في نقطة محددة. فسوق العمل يدفع أكثر لمن يحل مشكلة محددة بكفاءة عالية، مقارنة بمن يعرف قليلاً عن كل شيء. لذا اختر تخصصاً ينسجم مع اهتماماتك الحقيقية وخلفيتك المهنية السابقة. فمن يملك خلفية طبية ويضيف إليها معرفة بالذكاء الاصطناعي يجد نفسه في منطقة طلب نادر ومقدر جداً. وكذلك المحامي الذي يفهم نماذج اللغة القانونية يستطيع تقديم قيمة لا يستطيع تقديمها مهندس حاسوب وحده أبداً.
رؤية الحاسوب Computer Vision هي أحد أعمق تطبيقات الذكاء الاصطناعي وأكثرها تأثيراً في العالم الحقيقي. وتشمل تطبيقاتها تشخيص الأمراض عبر تحليل الصور الطبية، وأنظمة مراقبة الجودة في المصانع، والقيادة الذاتية للسيارات. فالشبكات التلافيفية CNN هي الأساس الكلاسيكي في هذا المجال. غير أن معمارية المحولات Vision Transformers أصبحت تحتل مكانة أكبر في أبحاث رؤية الحاسوب الحديثة.
يشمل ما يجب إتقانه في هذا المجال:
- تصنيف الصور Image Classification مع نماذج مثل ResNet وEfficientNet
- كشف الأجسام Object Detection مع YOLO وDetr
- التجزئة الدلالية Semantic Segmentation
- نقل الأنماط Style Transfer والنماذج التوليدية للصور
معالجة اللغة الطبيعية NLP هي المجال الأسرع تطوراً في الذكاء الاصطناعي خلال السنوات الأخيرة. فمن نماذج BERT وGPT إلى نماذج اللغة الكبيرة متعددة التروبتات، المجال يتطور بوتيرة لا تتوقف أسبوعياً. ومهارات NLP مطلوبة بشدة في تحليل تعليقات العملاء، وتلخيص الوثائق الطويلة، وترجمة اللغات، وبناء روبوتات المحادثة الذكية. واليوم، العمل في NLP يعني غالباً العمل مع نماذج مدربة مسبقاً وضبطها لمهام محددة مع فهم معمارية المحولات Transformers وآلية الانتباه Attention بشكل عميق.
خلاصة عملية وجدول زمني أسبوعي لتعلم الذكاء الاصطناعي من الصفر
هذه الخطة التفصيلية تفترض ساعة إلى ساعتين يومياً، وتهدف إلى الوصول إلى مستوى قابل للتوظيف خلال ستة أشهر فقط. وهي تعتمد على مبدأ المخرجات القابلة للقياس بعد كل مرحلة، لا على مجرد استهلاك المحتوى بشكل سلبي. والتزم بهذا الجدول مع إمكانية تعديل المدة حسب وتيرتك الشخصية ودون تخطي مرحلة قبل إتقان مخرجاتها تماماً. فالبناء المتين على أساس صحيح أفضل من التقدم السريع ثم الانهيار لاحقاً.
الأسبوع 1 إلى 4: الأسس الرياضية والبرمجية
المخرج القابل للقياس: قادر على كتابة كود Python لمعالجة ملفات البيانات وحساب إحصاءاتها الأساسية.
المصدر الموصى به: Python for Everybody من Coursera مجاناً.
الأسبوع 5 إلى 8: معالجة البيانات
المخرج القابل للقياس: مشروع تنظيف وتحليل لمجموعة بيانات حقيقية من Kaggle منشور على GitHub.
المصدر الموصى به: Pandas documentation و Kaggle Courses.
الأسبوع 9 إلى 14: التعلم الآلي الكلاسيكي
المخرج القابل للقياس: نموذج تنبؤي حقيقي مع تقييم كامل وتوثيق احترافي.
المصدر الموصى به: Machine Learning Specialization من DeepLearning.AI على Coursera.
الأسبوع 15 إلى 20: التعلم العميق
المخرج القابل للقياس: نموذج شبكة عصبية يحل مشكلة تصنيف أو توليد بشكل موثوق.
المصدر الموصى به: Deep Learning Specialization من DeepLearning.AI.
الأسبوع 21 إلى 26: التخصص والمشروع الكبير
المخرج القابل للقياس: مشروع متكامل في مجال متخصص مع توثيق كامل وعرض تقديمي للمشاركة.
المصدر الموصى به: Hugging Face Courses و NVIDIA DLI وفق مجال التخصص الذي اخترته.
الخارطة الذهنية للمهارات المتوازية: بجانب هذا المسار الرئيسي، خصص 20% من وقتك لقراءة الأخبار التقنية ومتابعة أحدث الأوراق البحثية عبر Papers With Code. وانضم إلى مجتمعات عملية مثل r/MachineLearning و Hugging Face Discord و Kaggle Forums. فالتعلم المعزول تقنياً وحده غير كافٍ أبداً، بل السياق المهني والتطورات اللحظية والتواصل مع المتعلمين الآخرين ضرورية أيضاً. وهذه المهارات الناعمة والشبكات المهنية هي ما يجعل سيرتك الذاتية تبرز بين مئات المتقدمين المتشابهين تقنياً.
هل تعلم الذكاء الاصطناعي سهل؟
الإجابة الصادقة هي: أسهل مما كان قبل عشر سنوات، وأصعب مما يصور في كثير من الإعلانات التجارية الجذابة. فالأدوات المتاحة اليوم خفضت الحاجز التقني بشكل كبير جداً، ويمكنك تشغيل نموذج لغوي متقدم في عشر دقائق باستخدام Hugging Face. لكن فهم ما تفعله فعلياً وتشخيص أخطائه وتحسينه لبيئة الإنتاج، هذا لا يزال يتطلب وقتاً وجهداً حقيقيين لا اختصار لهما. فالفرق بين تشغيل نموذج وفهمه هو الفرق بين الهاوي والمحترف في نظر سوق العمل.
ما هو سهل فعلاً: استخدام النماذج الجاهزة من خلال واجهات برمجة التطبيقات، وبناء نماذج أولية بسيطة لحل مشكلات صغيرة، وفهم المفاهيم الأساسية باستخدام المصادر الجيدة المتاحة مجاناً. وما هو صعب فعلاً: فهم لماذا يخطئ نموذجك بشكل محدد في حالات معينة، وتحسين الأداء في بيئات الإنتاج التي تخدم آلاف المستخدمين، والبقاء على اطلاع دائم في مجال يتطور بهذه السرعة الجنونية أسبوعياً. والمهارات الصعبة هي نفسها التي تدفع لها الشركات رواتب عالية، لأن قلة قليلة تتقنها.
الاستمرارية هي المتغير الأكثر تأثيراً في نجاحك أو فشلك في هذا المجال. فمن يتعلم ساعة يومياً بانتظام لمدة ستة أشهر سيتفوق دائماً على من يتعلم عشر ساعات في عطلة نهاية الأسبوع ثم يتوقف لأسابيع. لأن العقل البشري يحتاج إلى وقت لترسيخ المعرفة الجديدة وبناء الروابط العصبية اللازمة، ولا يوجد اختصار حقيقي لهذه العملية البيولوجية. لذا ابدأ بخطوات صغيرة لكن ثابتة، وتذكر أن الاستمرار أضعاف المضاعفة في تعلم الذكاء الاصطناعي أهم من السرعة الأولية بأضعاف كثيرة.
الخاتمة
تعلم الذكاء الاصطناعي اليوم ليس ترفًا، بل استثمار في المستقبل المهني بمفهومه الأشمل. الشركات العشر التي ذكرناها في هذا المقال تقدم مجتمعةً موارد تعليمية تُقدَّر بعشرات الآلاف من الدولارات، وتضعها بين يديك مجانًا أو بتكلفة رمزية. الفرصة موجودة، والسؤال الوحيد المتبقي هو: متى تبدأ.
البداية الأفضل هي التي تحدث الآن، لا الكاملة التي تحدث لاحقًا. اختر مصدرًا واحدًا من هذه القائمة يتناسب مع مستواك، وخصص ساعة يومية ثابتة، وابن مشروعك الأول خلال الثلاثين يومًا الأولى. هذه الخطوات الثلاث تُفرق بين من يبقى يقرأ عن الذكاء الاصطناعي وبين من يبنيه.
