

أعلنت شركة أنثروبيك عن إطلاق Claude Opus 4.7، أحدث إصدار من نموذجها الرائد. يشهد قطاع الذكاء الاصطناعي تطوراً سريعاً نحو نماذج مستقلة وقابلة للتنفيذ، مما يجعل هذا الإصدار في وقته المناسب. وتتمثل أهم ميزة يقدمها هذا النموذج في تحسين استقلاليته.
تقدم أنثروبيك هذا النموذج كأداة قادرة على التعامل مع أكثر عمليات البرمجة والأنشطة الذكية تعقيداً واستهلاكاً للوقت دون الحاجة إلى مراقبة مستمرة ودقيقة. لا يمثل هذا التطور مجرد تحسين تدريجي، بل قفزة نوعية في كيفية تفاعل البشر مع نماذج اللغة الضخمة.
يظهر هذا الإصدار أيضاً أن إمكانياته تتجاوز إمكانيات Opus 4.7. يتفوق نموذج Mythos Preview الداخلي من أنثروبيك على العديد من المعايير، إلا أنه لم يطرح على نطاق واسع حتى يتم تطبيق إجراءات الأمن السيبراني اللازمة.
بالنسبة لأي شخص خارج فريق البحث والتطوير في أنثروبيك، ويمثل Claude Opus 4.7 أحدث ما توصلت إليه التكنولوجيا الحالية. يثير هذا الأمر تساؤلات بالغة الأهمية حول مستقبل النماذج المغلقة مقابل النماذج المفتوحة، فضلاً عن مسؤوليات الشركات في ضمان أمن تقنياتها قبل إتاحتها للجمهور.
في هذه المقالة، سنستعرض الجديد في Claude Opus 4.7، ونتناول نتائج الاختبارات المعيارية، ونقدم اختبارات عملية يمكنك إجراؤها بنفسك. تهدف هذه المقالة إلى تقديم ملخص شامل لمساعدة الأكاديميين والمطورين وصناع القرار على فهم مكانة هذا النموذج في بيئة المنافسة الحالية.
جدول المحتويات
- ما هو Claude Opus؟
- ما هو Claude Opus 4.7؟
- ما الجديد في Claude Opus 4.7؟
- اختبار في Claude Opus 4.7؟
- تحسين اتباع التعليمات
- معايير قياس Claude Opus 4.7
- ما الذي تغير في Claude Opus 4.7 عن Opus 4.6
- ما الذي تم إطلاقه أيضا بجانب Claude Opus 4.7؟
- Claude Opus 4.7 مقابل GPT-5.4
- تفاصيل التسعير لـ Claude Opus 4.7
- أين تستخدم Claude Opus 4.7
- كيفية اختبار تكامل Claude Opus 4.7 مع واجهة برمجة التطبيقات
- كيف تتم الترقية إلى Claude Opus 4.7؟
- الخاتمة
ما هو Claude Opus؟
Anthropic Claude Opus هو نموذج ذكاء اصطناعي لغوي متطور ضمن عائلة نماذج كلود الشهيرة. طور لأداء مهام معقدة تتطلب فهمًا عميقًا للسياق، واستدلالًا منطقيًا، وتحليلًا معمقا للنصوص الطويلة.
يعتمد النموذج على نماذج اللغة الكبيرة (LLMs)، وهي نماذج لغوية ضخمة تدرب على كميات هائلة من البيانات النصية لفهم اللغة الطبيعية وإنشاء محتوى يحاكي اللغة البشرية. يصنف كلود أوبوس كنموذج عالي الأداء مصمم للتطبيقات المهنية والتجارية، لا سيما في المجالات التالية:
- تحليل البيانات النصية
- أتمتة الأعمال
- إنشاء المحتوى
- البرمجة وتوليد الأكواد
- المساعدون الأذكياء للمؤسسات
- خدمة العملاء المدعومة بالذكاء الاصطناعي
ما هو Claude Opus 4.7؟
يعد Claude Opus 4.7 أحدث نماذج Anthropic وأكثرها كفاءة، وهو متاح للاستخدام العام، وقد أطلق في 16 أبريل 2026. يقدم هذا النموذج رؤية عالية الدقة (تصل إلى 3.75 ميجابكسل)، ومستوى جهد جديد يسمى xhigh، وميزانيات مهام للحلقات الآلية، ومجزئ كلمات جديد. يحافظ على نافذة سياق مليون رمز وتسعير 5 دولارات/25 دولارا لكل مليون رمز من Opus 4.6، ولكنه يتضمن العديد من التغييرات الجذرية في واجهة برمجة التطبيقات (API)، بما في ذلك إزالة ميزانيات التفكير الموسعة ومعايير أخذ العينات.
وفقا لوثائق Cloud Opus 4.7، وبالتركيز على سيناريوهات النشر الواقعية، حيث يقدم Cloud Opus 4.7 العديد من التحسينات الرئيسية التي تجعله أكثر كفاءة بشكل ملحوظ في بيئات الإنتاج الحقيقية.
لقد تفوق أحدث نموذج لغوي هام من Anthropic، وهو Claude Opus 4.7، على Sonnet وHaiku ليصبح رائدا في عائلة نماذج Claude. بعد إصدار Cloud Opus 4.6، تم تطويره خصيصا للمهام الأكثر تعقيدا، مثل سير العمل الذكي المتطور ومهام الاستدلال متعددة الخطوات التي تتطلب أداء ثابتا على مدار جلسات طويلة.
بالمقارنة مع Opus 4.6، يركز الإصدار Claude Opus 4.7 على ثلاثة مجالات رئيسية:
- برمجة وكالة أكثر قوة
- قدرات استدلال بصري محسنة
- أداء أفضل مع استخدام أوسع للأدوات
باختصار، يعد Opus 4.7 نموذجا مشابها تم تدريبه خصيصا بميزات أقل في مجال الأمن السيبراني. من أنثروبيك، الذي أشرنا إليه سابقاً وتوجد لدينا أسئلة شائعة حوله، يتفوق على عدة معايير قياسية، لكنه غير متاح على نطاق واسع. يشكل Claude Opus 4.7 أساساً نموذجاً شقيقاً تم تدريبه مع تقليل قدرات الأمن السيبراني بشكل متعمد.
ما الجديد في Claude Opus 4.7؟
أعلنت Anthropic أن عدة مجالات من القدرات شهدت تحسينات ملحوظة في Opus 4.7.
دعم الصور عالية الدقة
هذه الإضافة الأبرز في هذا الإصدار. كانت النماذج السابقة من Claude تقبل الصور بطول أقصى يبلغ 1568 بكسل على الحافة الطويلة (حوالي 1.15 ميجابكسل). يرفع Opus 4.7 هذا الحد إلى 2576 بكسل على الحافة الطويلة (حوالي 3.75 ميجابكسل).
الأثر العملي: لقطات الشاشة، والنماذج التصميمية، والمستندات، والصور الفوتوغرافية تأتي بدقة أعلى بكثير. أصبح تخطيط الإحداثيات بنسبة 1:1 مع البكسلات الفعلية، مما يلغي حسابات عامل القياس التي كانت تتطلبها سير عمل استخدام الكمبيوتر سابقا.
يحسن Opus 4.7 أيضا المهام البصرية المحددة التالية:
- الإدراك منخفض المستوى: مهام التأشير والقياس والعد أصبحت أكثر دقة
- توطين الصور: كشف المربع المحيط وتوطين الصور الطبيعية يظهران تحسنا واضحا
الدقة العالية تعني رموزا أكثر لكل صورة. إذا كانت حالتك الاستخدامية لا تحتاج إلى الدقة الإضافية، يمكنك تقليل جودة الصور قبل إرسالها لتوفير التكاليف.
مستوى جهد xhigh الجديد
يتحكم معامل الجهد في مقدار التفكير الذي يستثمره Claude في الرد. يضيف Opus 4.7 مستوى xhigh فوق المستويات الحالية high و medium و low.
استخدم xhigh في مهام البرمجة والوكالة الذكية حيث الجودة أهم من زمن الاستجابة. عند هذا المستوى، ينفق النموذج رموزا أكثر بكثير على التفكير الداخلي، مما يؤدي إلى مخرجات أفضل للمشكلات المعقدة. استخدم high كحد أدنى للأعمال الحساسة للذكاء. المستويات المنخفضة تستبدل الدقة بالسرعة وتوفير التكاليف.
ميزانيات المهام (نسخة تجريبية)
تحل ميزانيات المهام مشكلة واجهها كل من يبني وكلاء ذكيين: كيف تمنع حلقة وكالة متعددة الخطوات من استهلاك عدد غير محدود من الرموز؟
مع ميزانيات المهام، يمكنك إعطاء Claude هدفا تقريبيا للرموز للحلقة بأكملها، بما في ذلك التفكير واستدعاءات الأدوات ونتائج الأدوات والمخرجات النهائية. يرى النموذج عدا تنازليا جاريا ويستخدمه لتحديد أولويات العمل وتخطي الخطوات منخفضة القيمة والإنهاء بأناقة مع نفاد الميزانية.
التفاصيل الرئيسية:
- الحد الأدنى لميزانية المهام هو 20,000 رمز
- إنها توجيهية وليست سقفا صارما، يحاول Claude البقاء ضمنها لكنه قد يتجاوزها
- إنها مختلفة عن max_tokens، وهو سقف صارم لكل طلب لا يراه النموذج
- تتطلب عنوان beta header task-budgets-2026-03-13
بالنسبة للمهام المفتوحة حيث الجودة أهم شيء، يمكنك تخطي ميزانية المهام والسماح للنموذج بالعمل بحرية. احتفظ بميزانيات المهام لأعباء العمل التي تحتاج فيها إلى التحكم في الإنفاق الإجمالي.
التفكير التكيفي كوضع التفكير الوحيد
تمت إزالة التفكير الموسع (حيث تحدد budget_tokens ثابتا). محاولة تعيين thinking: {“type”: “enabled”, “budget_tokens”: N} تعيد خطأ 400.
التفكير التكيفي هو وضع التفكير الوحيد. في تقييمات Anthropic الداخلية، تفوق باستمرار على نهج الميزانية الثابتة لأن النموذج يخصص رموز التفكير ديناميكيا بناء على صعوبة المهمة.
مهم: التفكير التكيفي معطل افتراضيا. يجب عليك تعيين thinking: {“type”: “adaptive”} لتفعيله.
افتراضيا، يتم أيضا حذف محتوى التفكير من الردود. إذا كنت بحاجة إلى رؤية منطق النموذج (مثل تدفق التقدم للمستخدمين)، قم بتعيين display: “summarized” في إعدادات التفكير.
ذاكرة محسنة
Opus 4.7 أفضل في الكتابة والقراءة من الذاكرة القائمة على نظام الملفات. إذا كان وكيلك يحتفظ بورقة ملاحظات أو ملف ملاحظات أو مخزن ذاكرة منظم عبر الخطوات، فسيكون أفضل في تحديث تلك الملاحظات والرجوع إليها.
هذا مهم للوكلاء طويلي التشغيل، والمساعدين البحثيين، وأي سير عمل حيث يمتد السياق عبر الجلسات.
تحسينات أعمال المعرفة
تحسينات محددة على مهام المعرفة الواقعية:
- تعديل المستندات: أفضل في إنتاج والتحقق من التغييرات المتعقبة في ملفات .docx
- تحرير الشرائح: دقة محسنة عند إنشاء والتحقق من تخطيطات .pptx
- تحليل المخططات: أفضل في استخدام مكتبات معالجة الصور (مثل PIL) لتحليل المخططات على مستوى البكسل وتحويل البيانات من الأشكال البيانية
اختبار في Claude Opus 4.7؟
أوضحت Anthropic أن نموذج Claude Opus 4.7 شهد تحسينات ملحوظة في عدة جوانب تقنية أساسية، الأمر الذي يجعله أكثر كفاءة في تنفيذ المهام المعقدة مقارنة بالإصدارات السابقة.
تحسين اتباع التعليمات
أصبح Claude Opus 4.7 أكثر دقة في تنفيذ التعليمات مقارنة بالنماذج السابقة. وتمثل هذه الميزة عنصرًا بالغ الأهمية في بيئات العمل التي تعتمد على الموثوقية العالية وسير العمل الآلي. ومع ذلك، تشير Anthropic إلى نقطة مهمة، وهي أن التعليمات التي كانت النماذج القديمة تتجاهلها أو تفسرها بشكل مرن أصبحت الآن تنفذ بصورة حرفية ودقيقة، لذلك تنصح الشركة المستخدمين بإعادة ضبط الـ Prompts وآليات التشغيل الخاصة بهم للحصول على أفضل النتائج.
لاختبار قدرة Opus 4.7 على اتباع التعليمات، استخدمنا الموجه التفصيلي التالي لاختبار قدرته على التحمل. يحتوي هذا الموجه على 12 قيدا مميزا يمكننا التحقق منها في النهاية.
اختبار قدرة Opus 4.7 على اتباع التعليمات
أنت تكتب مستند إحاطة قصير لموظف جديد في موقع وسام ويب. اتبع كل التعليمات أدناه. اكتب إحاطة حول نهج الموقع في تأهيل العملاء الجدد. يجب أن تلبي الإحاطة جميع المتطلبات التالية:
- يجب أن تتكون الإحاطة من 4 فقرات بالضبط.
- يجب أن تبدأ الفقرة الثانية بكلمة “تاريخيا”.
- يجب أن تحتوي كل فقرة على ما بين 3 و 5 جمل. لا يجوز لأي فقرة أن تقل عن 3 جمل أو تزيد عن 5.
- لا تستخدم كلمات معينة في أي مكان في المستند.
- تضمن اقتباسين مباشرين بالضبط من شركاء كبار خياليين. انسب كل اقتباس إلى شريك مسمى. لا تتضمن أي مادة مقتبسة أخرى.
- أحد الشركاء المقتبس عنهم يجب أن يكون لقبه يبدأ بحرف الميم.
- أنه المستند بسطر ختامي مكون من جملة واحدة منفصل عن الفقرة الرابعة بسطر فارغ. لا يحسب سطر الختام هذا ضمن متطلب الفقرات الأربع.
- يجب أن يكون سطر الختام سؤالا.
- لا تستخدم أي نقاط أو قوائم مرقمة أو عناوين.
- اذكر اسم عميل خيالي محدد مرة واحدة بالضبط، واكتبه بخط مائل.
- يجب أن يكون إجمالي عدد كلمات الإحاطة، بما في ذلك سطر الختام، بين 280 و 320 كلمة. لا تتضمن أي مقدمة أو شرح أو تعليق قبل الإحاطة أو بعدها. أخرج الإحاطة فقط.
وإليك النتيجة التي أنتجها النموذج:
مرحبا بكم في موقع وسام ويب، حيث يعتبر تأهيل العملاء الجدد أساس كل علاقة ناجحة طويلة الأجل. يركز نهجنا على فهم المنظمة خلف الأرقام قبل بدء أي عمل تقني، مما يعني أن الأسبوعين الأولين مخصصان بالكامل تقريبا للاستماع. يتم تعيين قائد تأهيل مخصص للعملاء الجدد ينسق التعريفات عبر فرق تصميم المواقع وكتابة المحتوى. يضمن هذا الهيكل أن كل زميل يتعامل مع الحساب يمتلك فهما متسقا لأولويات العميل وحساسياته.
تاريخيا، كان الموقع يعمل بنموذج أكثر تعاملا، حيث يتم التعامل مع التأهيل بشكل مجزأ من قبل أي شريك وقع على خطاب التعاقد. تغير ذلك في عام 2020، عندما أدركت القيادة العليا أن منافسينا كانوا يفوزون بالعمل على أساس العلاقات وليس الرسوم وحدها. وكما يذكر مرتضى شعيت، مدير الموقع المتخصص، كثيرا للموظفين الجدد: “العميل الذي يشعر بأنه مفهوم في الأسبوع الأول نادرا ما يعترض على الفاتورة في الشهر السادس”. أدى النهج المنقح إلى تحسين ملحوظ في معدلات الاحتفاظ بالعملاء والإحالات عبر كل خط خدمة.
من الناحية العملية، سيتوقع منك حضور اجتماع الاكتشاف الأولي لأي عميل تدعمه، حتى لو كان ذلك بصفة مراقبة فقط. يجب أن تتعرف على قطاع العميل وإيداعاته الأخيرة وأي تعليقات عامة من قيادته قبل تلك المحادثة الأولى. عندما قمنا بتأهيل موقع صحة لاند الطبي في الربيع الماضي، كان الزميل المبتدئ الذي اطلع على متطلباتهم التقنية بدقة هو من اكتشف الفجوات في استراتيجية المحتوى التي شكلت أساس تحسين تجربة المستخدم بأكمله. التحضير بهذا العمق هو المعيار الذي نتوقعه، وليس الاستثناء.
ستلاحظ أيضا أننا نؤكد على الصراحة منذ البداية، خاصة فيما يتعلق بالنطاق والجداول الزمنية الواقعية. يقول مرتضى شعيت، رئيس فريق تصميم المواقع: “نحن نفضل أن نخسر عرضا على أن نعد بشيء لا نستطيع تقديمه”، وتلك الفلسفة تلون كل محادثة تأهيل. خذ الوقت الكافي لطرح الأسئلة، وراقب الشركاء الكبار أثناء العمل، وأدرك أن الثقة تتراكم ببطء ولكنها توزع أرباحا متراكمة.
هل أنت مستعد لمقابلة عميلك الأول؟
الآن حان وقت تقييم النتيجة. سأشارككم معيار التقييم الخاص بنا:
| # | القيد | طريقة التحقق |
|---|---|---|
| 1 | 4 فقرات بالضبط (بالإضافة إلى سطر الختام) | عد فواصل الفقرات |
| 2 | الفقرة 2 تبدأ بكلمة “تاريخيا” | النظر إلى الكلمة الأولى |
| 3 | كل فقرة تحتوي على 3 إلى 5 جمل | عد الجمل في كل فقرة |
| 4 | لا توجد كلمات محظورة | البحث عن الكلمات المحظورة |
| 5 | اقتباسان بالضبط مع نسبهما، ولا مادة مقتبسة أخرى | عد علامات التنصيص |
| 6 | أحد الشركاء لقبه يبدأ بحرف الميم | التحقق من نسب الاقتباسات |
| 7 | سطر الختام مفصول بسطر فارغ | فحص بصري |
| 8 | سطر الختام هو سؤال | ينتهي بعلامة استفهام |
| 9 | لا نقاط أو قوائم مرقمة أو عناوين | فحص بصري |
| 10 | ذكر عميل خيالي مرة واحدة مع كتابته بخط مائل | البحث عن العلامات النجمية |
| 11 | عدد الكلمات بين 280 و 320 | لصق النص في عداد كلمات |
سنوفر عليك عناء التحقق بنفسك. حصل النموذج على 10 من 11.
كان النموذج يؤدي عمله بشكل مثالي، لكن في النهاية تجاوز عدد الكلمات بشكل طفيف جدا (325 كلمة مقابل حد أقصى 320 كلمة).
طبقنا الاختبار نفسه على Claude Sonnet 4.6، وحصل أيضا على 10 من 11 بشكل صحيح، مع فشل في نفس النقطة (عدد الكلمات). لكننا ما زلنا نعتبر Opus 4.7 تحسنا لأن Sonnet 4.6 تجاوز الحد بشكل كبير جدا (400 كلمة).
تطوير الدعم متعدد الوسائط
شهدت قدرات الرؤية الحاسوبية داخل النموذج تطورًا واضحًا، إذ أصبح يدعم تحليل الصور عالية الدقة حتى 3.75 ميجا بكسل، وهو ما يزيد بأكثر من ثلاثة أضعاف عن قدرة النماذج الأقدم. ويسهم هذا التحسين في رفع كفاءة وكلاء استخدام الحاسوب وأنظمة استخراج البيانات، خصوصًا في المهام التي تعتمد على قراءة التفاصيل الدقيقة ومستوى وضوح يصل أحيانًا إلى مستوى البكسل الواحد.
اختبار تعدد الوسائط
للاختبار الثاني، زودنا Opus 4.7 بصورة يصعب قراءتها:
أنت تحلل صورة متدهورة قد تكون ضبابية أو منخفضة الدقة أو يصعب قراءتها بطريقة أخرى. وظيفتك هي استخراج أكبر قدر ممكن من المعلومات الدقيقة.
أكمل جميع المهام التالية. لا تتضمن أي مقدمة أو شرح أو تعليق. أخرج فقط المخرجات المطلوبة.
- صف نوع المستند أو التصور الذي يبدو هذا عليه (مثال: مخطط شريطي، لوحة معلومات، جدول، صفحة تقرير). اذكر ثقتك كـ High أو Medium أو Low.
- اسرد كل رقم يمكنك تمييزه، حتى لو كان جزئيا. لكل رقم، اذكر ما تعتقد أنه يشير إليه وثقتك (High أو Medium أو Low). إذا كان الرقم غامضا بين قراءتين (مثال: يمكن أن يكون 138 أو 188)، فاذكر كلا الاحتمالين.
- اسرد كل نص يمكنك تمييزه، عناوين، تسميات، توضيحات، حواشي، مقتبسا بأكبر قدر ممكن من الدقة. عندما يكون حرف أو كلمة غير واضحة، استخدم [?] لتحديد الحرف غير المؤكد، مثال: “Re[?]enue”.
- صف التخطيط: كم عدد الأقسام أو اللوحات المميزة المرئية، وماذا يحتوي كل منها على ما يبدو؟
- اذكر ما تعتقد أن الموضوع العام أو قصة الصورة هو، في جملة واحدة لا تزيد عن 25 كلمة. حدد إذا كانت ثقتك Low.
- اسرد أي شيء حاولت قراءته لكنك لم تستطع تمييزه على الإطلاق.
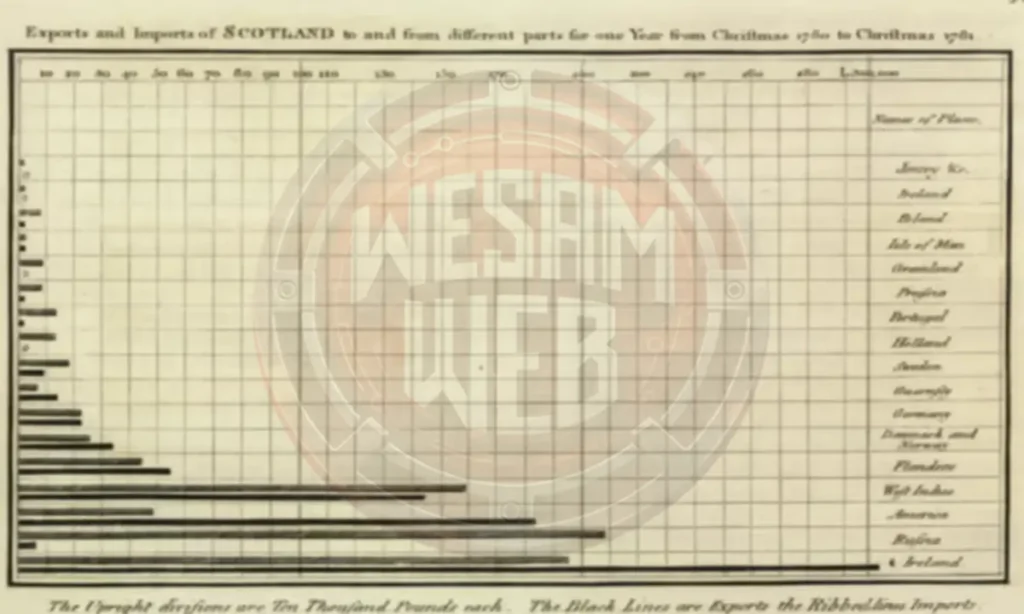
بالإضافة إلى هذه التعليمات، زودنا Opus 4.7 بلقطة شاشة متدهورة الجودة لمخطط Playfair التجاري لاسكتلندا عام 1786، والتي أخذناها من مقال عن أمثلة تصور البيانات.
عرفنا أننا نستطيع التحقق من المخرجات لأننا حصلنا على نسخة عالية الدقة من Wikipedia. إليك الصورة التي رآها Opus 4.7:
وإليك قراءة Opus 4.7:
النوع: مخطط شريطي أفقي، نقش قديم. الثقة: High.
الأرقام: علامات المحور X: 10، 20، 30…110، 130، 150، 170، 200، 220، 240، 260، 280، L.300,000 (High، لكن 130/220 غير مؤكدة). السنتان “1780” و “1781” في العنوان (High). “Ten Thousand Pounds” لكل قسم (High).
العنوان: “Exports and Imports of SCOTLAND to and from different parts for one Year from Christmas 1780 to Christmas 1781”.
رأس الصفحة: “Names of Places”.
الأماكن: Jersey &c.، Ireland، [?]oland، Isle of Man، Gr[oe]nland، Prussia، Portugal، Holland، Sweden، Guernsey، Germany، Denmark and Norway، Flanders، West Indies، America، Russia، Ireland (مكرر؟)
الحاشية: “The Upright divisions are Ten Thousand Pounds each. The Black Lines are Exports the Ribbed lines Imports.”
التخطيط: لوحة واحدة، عنوان، منطقة الرسم تحتوي على حوالي 16 زوجا من الأشرطة، عمود أسماء الأماكن على اليمين، حاشية سفلية.
الموضوع: مخطط تجاري للفترة 1780-1781 يوضح صادرات وواردات اسكتلندا حسب الشريك التجاري. الثقة: High.
لم يستطع قراءته: علامة الزاوية اليمنى العليا، قيم الأشرطة الدقيقة، الحرف الأول من “[?]oland”، وما إذا كانت كلمة “Ireland” السفلية مكررة.
عرفنا أن هذا الاختبار قد يكون صعبا، لأن المحور X لمخطط Playfair يغير العد فعليا في منتصفه (كل 10 حتى 110، ثم العشرات الفردية 130/150/170، ثم العشرات الزوجية 200/220/240/260/280). لكن Opus 4.7 قرأ المحور بشكل صحيح في المحاولة الأولى على الرغم من أنه كان غريبا.
شيء واحد لا يزال يلفت انتباهنا: نحن نحب أن تظهر نماذج الذكاء الاصطناعي عدم يقينها، لكن “[?]oland” كان يجب أن تقرأ بثقة كـ “Poland” و “Gr[oe]nland” كان يجب أن تكون “Greenland”. على الرغم من أنه لم يكن لدينا معيار تقييم رسمي لهذا الاختبار، يمكننا منحه 9 من 10 بإنصاف.
تحسينات الذاكرة والسياق طويل المدى
أصبح Claude Opus 4.7 أكثر كفاءة في إدارة الذاكرة المعتمدة على نظام الملفات، وهي آلية تعتمد على قيام النموذج بكتابة الملاحظات داخل ملفات أثناء العمل ثم الرجوع إليها لاحقًا في الجلسات المستقبلية.
ويظهر هذا الاستخدام بوضوح داخل أداة Claude Code، حيث يتم إنشاء ملف باسم CLAUDE.md داخل المشروع، ليقوم النموذج بقراءته عند بدء الجلسة، وتحديثه مع تطور القرارات البرمجية، ثم استخدامه لاحقًا عند العودة إلى المشروع.
والمقصود هنا بكلمة “أفضل” ليس فقط الاحتفاظ بالملاحظات، بل أيضًا امتلاك قدرة أدق على تحديد المعلومات المهمة التي تستحق الحفظ، مع تحسين استدعائها لاحقًا بصورة أكثر موثوقية. ووفقًا لـ Anthropic فإن هذه الميزة تقلل الحاجة إلى إعادة شرح تفاصيل المشروع أو القواعد البرمجية في كل جلسة جديدة، وهو ما يمثل تحسينًا عمليًا مهمًا للمطورين وفرق العمل التقنية.
وباختصار، إذا كنت تستخدم Claude Opus 4.7 في مشاريع طويلة الأمد أو جلسات متعددة، فمن الأفضل السماح للنموذج بالاحتفاظ بالملاحظات، لأنه أصبح أكثر كفاءة في إدارة المعرفة مقارنة بالإصدارات السابقة.
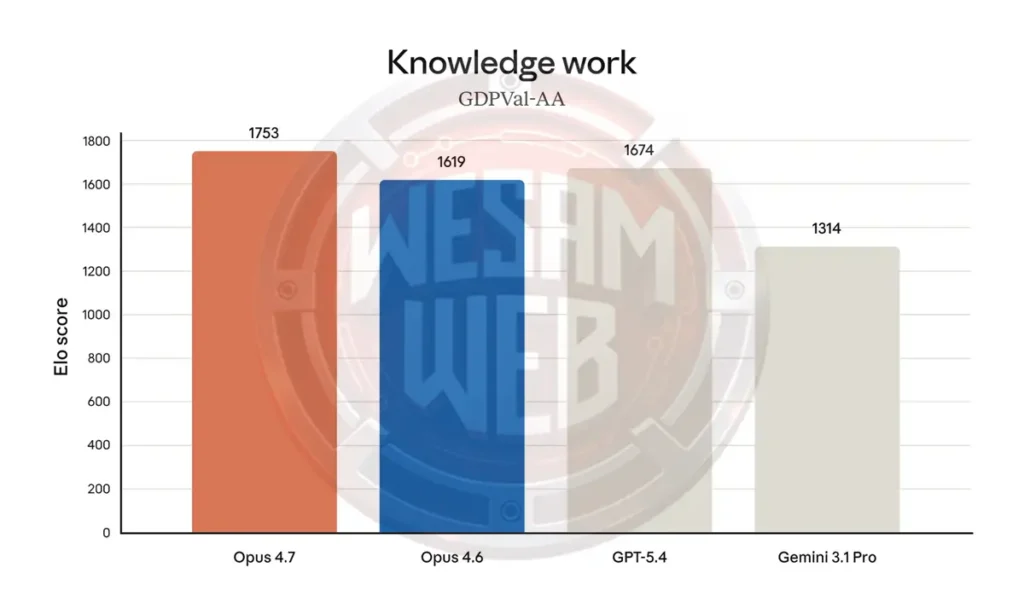
معايير قياس Claude Opus 4.7
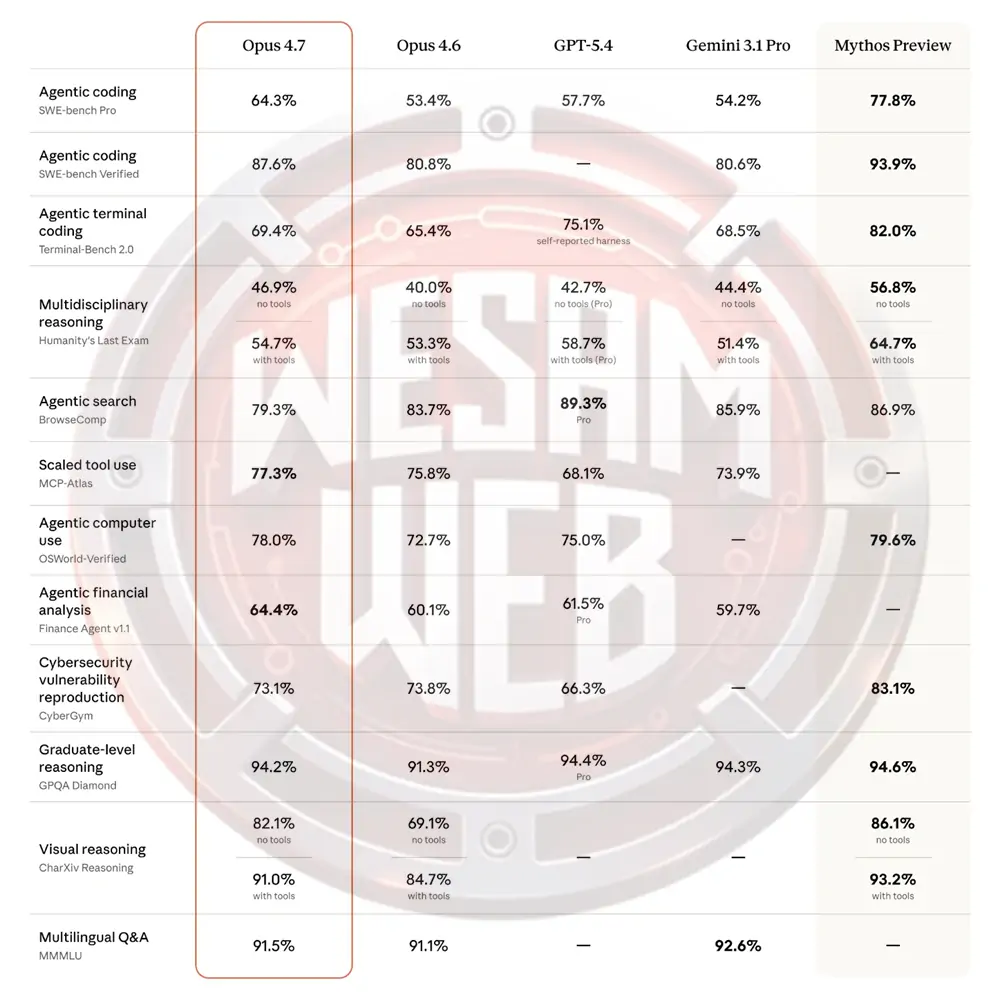
تم تقييم Opus 4.7 عبر 14 معيارا تغطي البرمجة والاستدلال واستخدام الأدوات واستخدام الكمبيوتر والاستدلال البصري. الجدول أدناه يظهر المقارنة الكاملة مع Opus 4.6 و GPT 5.4 و Gemini 3.1 Pro و Mythos Preview الذي لم ينشر بعد.
1. البرمجة الوكيلة
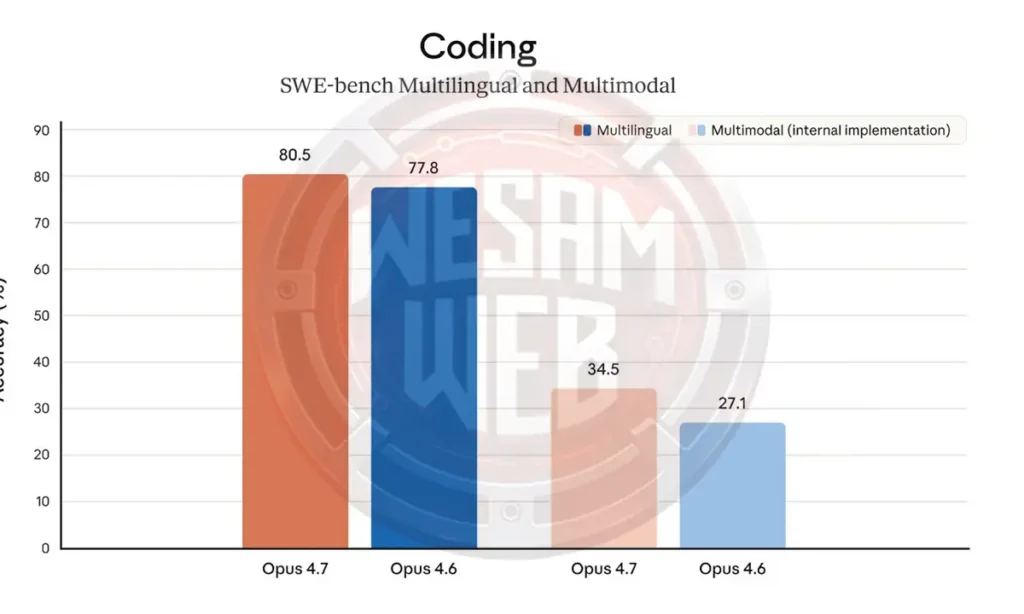
على معيار SWE-bench Pro، سجل Opus 4.7 نسبة 64.3%، متقدما على GPT-5.4 بنسبة 57.7%، و Gemini 3.1 Pro بنسبة 54.2%، و Opus 4.6 بنسبة 53.4%. على معيار SWE-bench Verified، وصل Opus 4.7 إلى 87.6% مقابل 80.6% لـ Gemini 3.1 Pro و 80.8% لـ Opus 4.6.
يختبر SWE-bench قدرة النموذج على حل مشكلات GitHub الحقيقية في مستودعات Python مفتوحة المصدر. Pro هو متغير أصعب بمشكلات أكثر تعقيدا. الفارق 10.9 نقطة فوق Opus 4.6 على SWE-bench Pro هو أكبر تحسن في هذا الإصدار ويضع Opus 4.7 بوضوح في المقدمة على كلا المنافسين الرئيسيين في هذه المهمة.
فقط Mythos Preview الداخلي من Anthropic يسجل 77.8% على SWE-bench Pro و 93.9% على SWE-bench Verified، مما يظهر أنه لا يزال هناك مجال أعلى من Opus 4.7. ومع ذلك، Mythos ليس متاحا على نطاق واسع، لذا للاستخدام الإنتاجي، Opus 4.7 هو السقف الحالي.
النتائج على معيار Terminal-Bench 2.0، وهو المعيار المرجعي للبرمجة الوكيلة في الطرفية، مثيرة للاهتمام حقا. يحسن Opus 4.7 قليلا مقارنة بسابقه (69.4% مقابل 65.4%) ويتفوق على Gemini 3.1 Pro الذي سجل 68.5%.
ومع ذلك، لا يمكنه منافسة GPT-5.4 (75.1%) في هذا الصدد، على الرغم من أن التحفظ الذي أبلغ عنه GPT-5.4 بنفسه يستحق وضعه في الاعتبار عند المقارنة. قد يكون مخيبا للآمال بالنسبة لـ Anthropic أن أحدث نموذج رائد لها لا يتصدر معيارا مركزيا لتطوير البرمجيات الوكيلة.
2. الاستدلال
Humanity’s Last Exam هو مجموعة من الأسئلة على مستوى الدراسات العليا في العلوم والرياضيات والعلوم الإنسانية، صممت لتكون صعبة على النماذج الرائدة الحالية. يتصدر Opus 4.7 البديل بدون أدوات، والذي يختبر الاستدلال الخام دون استرجاع خارجي. الفجوة مع الأدوات لصالح GPT-5.4 (58.7%) هي أوضح منطقة لا يتصدر فيها Opus 4.7 (54.7%).
عادة ما يقاس الاستدلال على مستوى الدراسات العليا في GPQA-Diamond، وهو مشبع جدا هذه الأيام، مثل جميع النماذج الرائدة الحالية، تحقق النماذج الأربعة المقارنة نتيجة تزيد عن 90% وهي متعادلة أساسا.
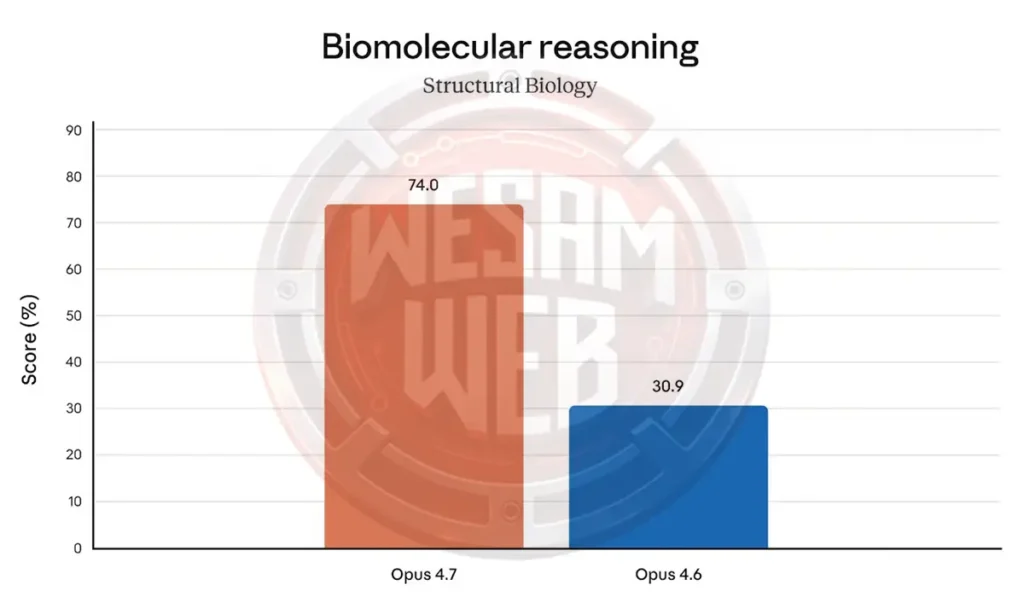
نتيجة معيار أكثر إثارة للاهتمام تستهدف علم الأحياء، وهو أحد المجالات التي تم اختبارها أيضا في GPQA-Diamond تحديدا. على الرغم من أننا لا نستطيع مقارنتها بالنماذج المنافسة، فإن القفزة بين Opus 4.6 (30.9%) و Opus 4.7 (74.0%) جديرة بالملاحظة بالتأكيد.
3. الاستدلال البصري
النتائج في معيار CharXiv، الذي يقيس الاستدلال البصري حول المخططات والأشكال العلمية، تعكس أن هذه كانت واحدة من مجالات التركيز الرئيسية في تطوير Opus 4.7.
التحسن بـ 13 نقطة بدون أدوات هو أكبر زيادة نسبية في هذا الإصدار. بدون نتائج المنافسين للمقارنة، من الصعب تحديد مكانة Opus 4.7 في المجال الأوسع لهذه المهمة، لكن التحسن مقارنة بـ Opus 4.6 كبير.
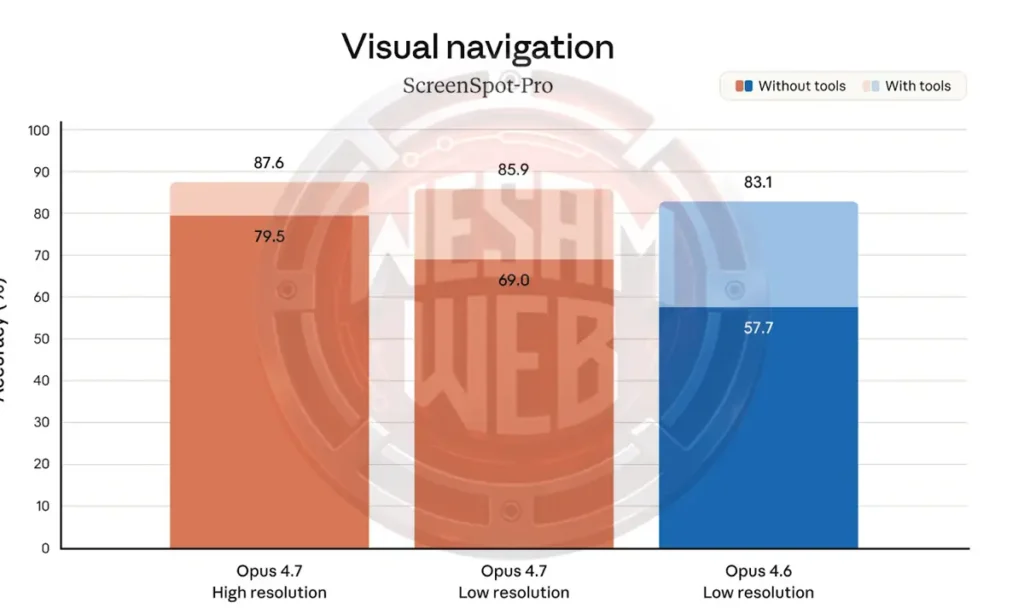
دعم الدقة العالية للصور هو likely أحد أسباب تحسين الاستدلال البصري. يظهر مخطط نتائج Screenspot-Pro بدقات مختلفة الزيادة الهائلة في الدقة التي يحصل عليها Opus 4.7 من الدقة العالية، خاصة بدون استخدام الأدوات (79.5% مقابل 69.0%).
4. الاستخدام الوكيل للأدوات والكمبيوتر
MCP-Atlas يختبر الأداء عبر سير عمل معقد متعدد الأدوات. يسجل Opus 4.7 77.3% هنا، وهو الأعلى بين أي نموذج في المقارنة. النموذج الوحيد الذي يتفوق على نتيجة Opus 4.7 في MCP-Atlas بشكل طفيف جدا هو Muse Spark، الذي سجل 78.3%.
OSWorld يختبر قدرة النموذج على إكمال المهام عن طريق التحكم في واجهة الكمبيوتر، والنقر، والكتابة، والتنقل بين التطبيقات.
- يسجل Opus 4.7 78.0%، مرتفعا من 72.7% في Opus 4.6.
- وسجل GPT-5.4 75.0%، وليس لدى Gemini 3.1 Pro نتيجة منشورة على هذا المعيار.
- أنتج Mythos Preview 79.6%، أعلى قليلا من Opus 4.7.
هذه بالتأكيد مجال يتفوق فيه Opus 4.7، فهو يتصدر كلا من MCP-Atlas و OSWorld-Verified بفارق كبير عن النماذج الرائدة من Google و OpenAI، وهي نتيجة قوية لأي شخص يبني أنظمة وكالة إنتاج تعتمد على تنسيق الأدوات ووكلاء استخدام الكمبيوتر.
5. التحليل المالي
تستحق مهارات التحليل المالي للنموذج إشارة خاصة. يتصدر Opus 4.7 لوحة متصدرين Finance Agent v1.1 (64.4%)، متقدما بشكل كبير على كلا من GPT-5.4 (61.5%) و Gemini 3.1 Pro (59.7%).
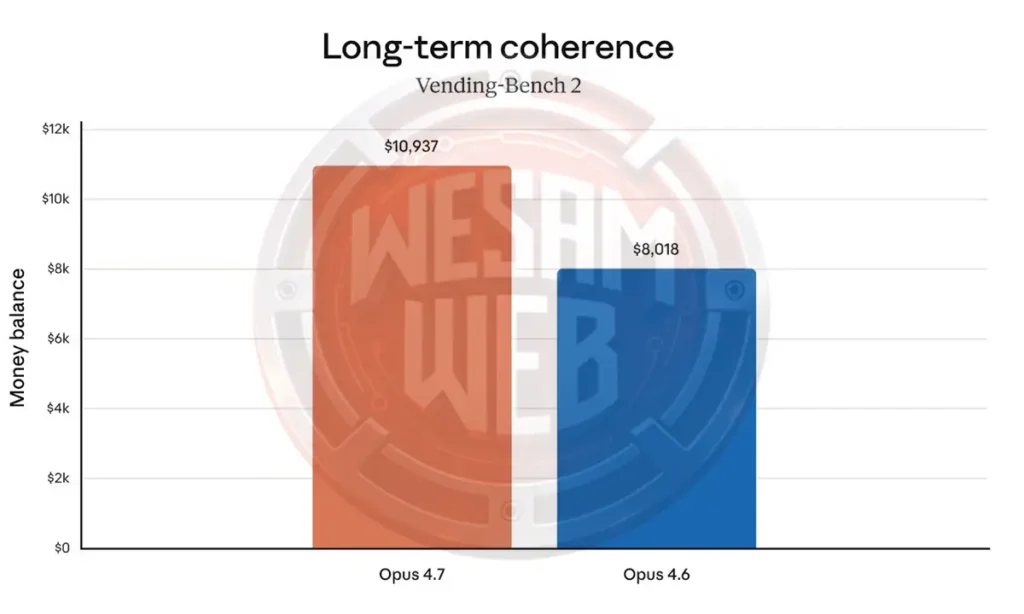
في معيار Vending-Bench 2 الأكثر توجها نحو التطبيق العملي، نرى أن Opus 4.7 أفضل مع المال أيضا. في المتوسط، انتهى النموذج بمبلغ 10,937 دولارا، مقارنة بـ 8,018 دولارا مع Opus 4.6.
ما الذي تغير في Claude Opus 4.7 عن Opus 4.6
يأتي الإصدار الجديد Opus 4.7 بعدة تغييرات جوهرية مقارنة بالإصدار السابق Opus 4.6، بعضها جذري في واجهة برمجة التطبيقات ويتطلب تعديلات في الكود الحالي، والبعض الآخر تغييرات سلوكية تؤثر على طريقة تفاعلك مع النموذج وجودة المخرجات.
تغييرات جذرية في واجهة برمجة التطبيقات
تنطبق هذه التغييرات على Messages API. إذا كنت تستخدم Claude Managed Agents، فلا توجد تغييرات جذرية.
| التغيير | قبل (Opus 4.6) | بعد (Opus 4.7) |
|---|---|---|
| التفكير الموسع | thinking: {“type”: “enabled”, “budget_tokens”: 32000} | يجب استخدام thinking: {“type”: “adaptive”} |
| معاملات أخذ العينات | temperature, top_p, top_k مقبولة | القيم غير الافتراضية تعيد خطأ 400 |
| عرض التفكير | محتوى التفكير مضمن افتراضيا | محذوف افتراضيا، يمكن تفعيله بـ display: “summarized” |
| تجزئة الكلمات | مجزئ كلمات قياسي | مجزئ كلمات جديد (حتى 35% رموزا إضافية لنفس النص) |
تغييرات سلوكية
هذه التغييرات ليست جذرية في واجهة برمجة التطبيقات ولكنها قد تؤثر على موجهاتك:
- اتباع تعليمات أكثر حرفية. النموذج لن يعمم التعليمات بصمت من عنصر إلى آخر.
- طول الاستجابة يتناسب مع تعقيد المهمة بدلا من افتراض طول ثابت.
- استدعاءات أدوات أقل افتراضيا، مفضلا التفكير على العمل. ارفع مستوى الجهد لزيادة استخدام الأدوات.
- نبرة أكثر مباشرة وحازمة مع رموز تعبيرية أقل وصياغة أقل تأكيدا.
- عدد أقل من الوكلاء الفرعيين بشكل افتراضي في سير العمل الوكيل.
إذا كنت قد بنيت سقالات توجيهية لإجبار Claude على سلوكيات محددة (مثل “تحقق مرة أخرى من تخطيط الشريحة” أو “قدم تحديثات الحالة”)، فحاول إزالتها. Opus 4.7 يتعامل مع العديد من هذه الأنماط بشكل أصلي.
ما الذي تم إطلاقه أيضا بجانب Claude Opus 4.7؟
أطلقت Anthropic عدة تحديثات إلى جانب النموذج نفسه تستحق المعرفة، على الأقل إذا كنت تستخدم Claude Code أو تبني على واجهة برمجة التطبيقات.
مستوى جهد xhigh جديد
أضيف مستوى جهد xhigh (“مرتفع جدا”) جديد بين high و max. هذا يمنحك خيارا آخر عند الاختيار بين عمق التفكير وزمن الاستجابة. في Claude Code، تم رفع مستوى الجهد الافتراضي إلى xhigh عبر جميع الخطط، وتوصي Anthropic بالبدء بـ high أو xhigh عند اختبار Opus 4.7 على مهام البرمجة والوكالة الذكية.
/ultrareview في Claude Code
اكتسب Claude Code أمر شرطة مائلة جديد /ultrareview، والذي يقوم بتشغيل مراجعة مخصصة على تغييراتك وتحديد الأخطاء أو مشكلات التصميم التي قد يكتشفها مراجع بشري دقيق. يحصل مستخدمو Pro و Max على ثلاث مراجعات ultrareviews مجانية لتجربتها.
الوضع التلقائي لمستخدمي Max
يحصل مستخدمو Max الآن على الوضع التلقائي، وهو إعداد أذونات حيث يتخذ Claude قرارات نيابة عنك. إنه حل وسط بين الموافقة على كل خطوة وتخطي الأذونات تماما.
ميزانيات المهام على واجهة برمجة التطبيقات
أصبحت ميزانيات المهام الآن في النسخة التجريبية العامة على Claude API. تسمح هذه للمطورين بتحديد سقف لإنفاق Claude من الرموز عبر الجولة، وهو مفيد بشكل خاص لسير عمل الوكالة الأطول حيث تريد أن ينظم النموذج نفسه بدلا من حرق ميزانيته.
Claude Opus 4.7 مقابل GPT-5.4
نظرنا عن كثب إلى نتائج المعايير القياسية، وتلك النتائج احتوت على مقارنة بالنماذج الأخرى. بشكل عام، دعونا نقارن Opus 4.7 مع GPT-5.4 مباشرة.
الخلاصة الأساسية هي أن Opus 4.7 يحسن من الاستقلالية طويلة الأجل، بينما GPT-5.4 هو نموذج عام موحد مع دعم أوسع للأدوات وتسعير أرخص للسياق القصير.
| المعيار | Claude Opus 4.7 | GPT-5.4 |
|---|---|---|
| الأفضل في | جولات البرمجة الطويلة، استخدام كمبيوتر سطح المكتب، الرؤية الكثيفة | أبحاث المتصفح، مهام السياق القصير، توجيه منتصف الاستجابة |
| SWE-bench Pro | 64.3% | 57.7% |
| BrowseComp | 79.3% | 89.3% |
| التسعير | سعر ثابت عبر مليون سياق | أرخص تحت 272 ألف رمز، إعادة تسعير الجلسة الكاملة أعلاه |
| نافذة السياق | ~1 مليون رمز | ~1 مليون رمز |
تفاصيل التسعير لـ Claude Opus 4.7
يحافظ Opus 4.7 على نفس التسعير لكل رمز مثل Opus 4.6 و 4.5:
| نوع الاستخدام | التكلفة |
|---|---|
| الإدخال القياسي | $5 / مليون رمز |
| الإخراج القياسي | $25 / مليون رمز |
| الإدخال المجمع | $2.50 / مليون رمز |
| الإخراج المجمع | $12.50 / مليون رمز |
| قراءة ذاكرة التخزين المؤقت | $0.50 / مليون رمز |
| كتابة ذاكرة التخزين المؤقت (5 دقائق) | $6.25 / مليون رمز |
| كتابة ذاكرة التخزين المؤقت (ساعة) | $10 / مليون رمز |
| الإدخال السريع (Opus 4.6 فقط) | $30 / مليون رمز |
| إقامة البيانات في الولايات المتحدة | مضاعف 1.1x |
مجزئ الكلمات الجديد هو متغير التكلفة الذي يجب مراقبته. لأنه قد ينتج ما يصل إلى 35% رموزا إضافية لنص الإدخال نفسه، فقد تزيد تكلفتك الفعلية لكل طلب على الرغم من أن سعر الرمز الواحد لم يتغير. اختبر باستخدام نقطة النهاية /v1/messages/count_tokens لقياس التأثير على موجهاتك المحددة.
نافذة السياق مليون رمز ليس لها علاوة على السياق الطويل. طلب 900 ألف رمز يكلف نفس السعر لكل رمز مثل طلب 9 آلاف رمز.
أين تستخدم Claude Opus 4.7
قبل تحديد ما إذا كان Opus 4.7 مناسبا لحالتك الاستخدامية، من المهم فهم الموازنة بين الأداء والتكلفة والتعقيد. يتفوق هذا النموذج في المهام الطويلة والمعقدة التي تتطلب استدلالا عميقا واستقلالية عالية، لكنه قد يكون أكثر من اللازم للمهام البسيطة التي يمكن لنماذج أخف مثل Haiku أو Sonnet إنجازها بتكلفة أقل وزمن استجابة أسرع.
حالات استخدام قوية
وكلاء البرمجة المستقلة: مستوى الجهد xhigh + ميزانيات المهام يمنحك تحكما دقيقا في سلوك الوكيل والتكلفة.
استخدام الكمبيوتر: تخطيط إحداثيات 1:1 ورؤية 3.75 ميجابكسل يجعلان تفاعل الشاشة أكثر موثوقية بشكل كبير.
معالجة المستندات: تحليل محسن لـ .docx و .pptx والمخططات لأتمتة أعمال المعرفة.
استرجاع السياق الطويل: نافذة مليون رمز بتسعير قياسي لقواعد التعليمات البرمجية الكبيرة أو المستندات القانونية أو الأوراق البحثية.
وكلاء متعددو الجلسات: ذاكرة أفضل قائمة على الملفات لسير العمل التي تمتد عبر عدة محادثات.
متى قد يكون Claude Opus 4.7 مبالغا فيه
الأسئلة البسيطة أو مهام التصنيف: Haiku 4.5 (1/5 لكل مليون رمز) أو Sonnet 4.6 (3/15 لكل مليون رمز) يقدمان نتائج قوية بجزء بسيط من التكلفة.
تدفقات الدردشة منخفضة زمن الاستجابة: عبء التفكير التكيفي ومستويات الجهد العالية يضيف زمنا مستقطعا.
التحليلات المجمعة على البيانات المنظمة: واجهة برمجة تطبيقات المجموعات (Batch API) مع Sonnet هي أكثر فعالية من حيث التكلفة عادة.
كيفية اختبار تكامل Claude Opus 4.7 مع واجهة برمجة التطبيقات
تغيير معرف النموذج من claude opus 4.6 إلى claude opus 4.7 هو الجزء السهل. الجزء الأصعب هو التحقق من أن موجهاتك الحالية وتعريفات أدواتك ومعالجة الأخطاء لا تزال تعمل بشكل صحيح بعد التغييرات الجذرية.
Apidog يجعل هذا مباشرا:
استيراد مخطط واجهة برمجة التطبيقات API الخاص بك. قم بإدراج مواصفات OpenAPI الخاصة بك أو حدد يدويا نقاط نهاية Claude API. يقوم Apidog بإنشاء قوالب طلب تلقائيا لـ Messages API.
إنشاء سيناريوهات اختبار. قم بإعداد محادثات متعددة الخطوات تختبر أنماط استخدام الأدوات الخاصة بك. يتيح لك Apidog ربط الطلبات وتمرير السياق بين الخطوات والتحقق من مخططات الاستجابة.
مقارنة إصدارات النماذج. قم بتشغيل سيناريوهات الاختبار نفسها مقابل claude-opus-4-6 و claude-opus-4-7 جنبا إلى جنب. تحقق من الاختلافات في عدد الرموز وهيكل الاستجابة وجودة المخرجات.
التحقق من صحة التغييرات الجذرية. تأكد من أن تكوين التفكير المحدث يعمل، وأن معاملات أخذ العينات المحذوفة لا تعود، وأن مجزئ الكلمات الجديد لا يتجاوز حدود max_tokens الخاصة بك.
تصحيح أخطاء حمولات استخدام الأدوات. افحص جسم الطلب والاستجابة الكاملين لمحادثات استخدام الأدوات متعددة الخطوات. تجعل الواجهة المرئية لـ Apidog من السهل اكتشاف نتائج الأدوات غير الصحيحة أو مراجع tool_use_id المفقودة.
كيف تتم الترقية إلى Claude Opus 4.7؟
إذا كنت تترحل من Opus 4.6:
[ ] تحديث معرف النموذج إلى claude-opus-4-7
- استبدال thinking: {“type”: “enabled”, “budget_tokens”: N} بـ thinking: {“type”: “adaptive”}
- إزالة معاملات temperature، top_p، top_k (أو تعيينها إلى القيم الافتراضية)
- إذا كنت تبث التفكير للمستخدمين، أضف display: “summarized” إلى تكوين التفكير الخاص بك
- زيادة مساحة max_tokens لمراعاة مجزئ الكلمات الجديد (حتى 35% رموزا إضافية)
- اختبار تخزين الموجهات المؤقت، سوف تختلف أعداد الرموز
- إزالة السقالات التوجيهية للسلوكيات التي يتعامل معها Opus 4.7 بشكل أصلي (تحديثات الحالة، التحقق الذاتي)
- تشغيل مجموعة الاختبارات الخاصة بك باستخدام Apidog للتحقق من السلوك الشامل
الخاتمة
Claude Opus 4.7 هو أقوى نموذج متاح بشكل عام من Anthropic. الرؤية عالية الدقة وميزانيات المهام ومستوى الجهد xhigh تدفعه إلى أبعد من ذلك في منطقة الوكيل المستقل. التغييرات الجذرية (لا مزيد من ميزانيات التفكير الموسعة، لا معاملات أخذ العينات) تتطلب تحديثات في الكود، لكن مسار الترحيل واضح.
مجزئ الكلمات الجديد هو اعتبار التكلفة الرئيسي. أسعار كل رمز ثابتة، لكن الموجه نفسه قد يكلف أكثر بسبب أعداد الرموز الأعلى. اختبر أعباء العمل الخاصة بك قبل تحويل حركة مرور الإنتاج.
للمطورين الذين يبنون تكاملات واجهة برمجة التطبيقات، يوفر Apidog بيئة الاختبار وتصحيح الأخطاء التي تحتاجها للتحقق من صحة الترحيل الخاص بك ومقارنة أداء النموذج عبر الإصدارات.
ما يجعل هذا الإصدار مثيرا للاهتمام هو إطار Mythos. فـ Opus 4.7 هو مركبة اختبار مقيدة سيبرانيا في الطريق إلى إصدار أوسع من فئة Mythos، مما يعني أن هناك الآن سقفا واضحا فوقه لا يمكنك الوصول إليه، ولكن أيضا أن الضمانات التي تأتي مع 4.7 هي نظرة مستقبلية لكيفية تخطط Anthropic للتعامل مع الإصدارات الرائدة في المستقبل.
